 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Experience to Strategy: Empowering LLM Agents with Trainable Graph Memory
Nov 11, 2025Large Language Models (LLMs) based agents have demonstrated remarkable potential in autonomous task-solving across complex, open-ended environments. A promising approach for improving the reasoning capabilities of LLM agents is to better utilize prior experiences in guiding current decisions. However, LLMs acquire experience either through implicit memory via training, which suffers from catastrophic forgetting and limited interpretability, or explicit memory via prompting, which lacks adaptability. In this paper, we introduce a novel agent-centric, trainable, multi-layered graph memory framework and evaluate how context memory enhances the ability of LLMs to utilize parametric information. The graph abstracts raw agent trajectories into structured decision paths in a state machine and further distills them into high-level, human-interpretable strategic meta-cognition. In order to make memory adaptable, we propose a reinforcement-based weight optimization procedure that estimates the empirical utility of each meta-cognition based on reward feedback from downstream tasks. These optimized strategies are then dynamically integrated into the LLM agent's training loop through meta-cognitive prompting. Empirically, the learnable graph memory delivers robust generalization, improves LLM agents' strategic reasoning performance, and provides consistent benefits during Reinforcement Learning (RL) training.
EconGym: A Scalable AI Testbed with Diverse Economic Tasks
Jun 13, 2025



Artificial intelligence (AI) has become a powerful tool for economic research, enabling large-scale simulation and policy optimization. However, applying AI effectively requires simulation platforms for scalable training and evaluation-yet existing environments remain limited to simplified, narrowly scoped tasks, falling short of capturing complex economic challenges such as demographic shifts, multi-government coordination, and large-scale agent interactions. To address this gap, we introduce EconGym, a scalable and modular testbed that connects diverse economic tasks with AI algorithms. Grounded in rigorous economic modeling, EconGym implements 11 heterogeneous role types (e.g., households, firms, banks, governments), their interaction mechanisms, and agent models with well-defined observations, actions, and rewards. Users can flexibly compose economic roles with diverse agent algorithms to simulate rich multi-agent trajectories across 25+ economic tasks for AI-driven policy learning and analysis. Experiments show that EconGym supports diverse and cross-domain tasks-such as coordinating fiscal, pension, and monetary policies-and enables benchmarking across AI, economic methods, and hybrids. Results indicate that richer task composition and algorithm diversity expand the policy space, while AI agents guided by classical economic methods perform best in complex settings. EconGym also scales to 10k agents with high realism and efficiency.
Internal Chain-of-Thought: Empirical Evidence for Layer-wise Subtask Scheduling in LLMs
May 20, 2025
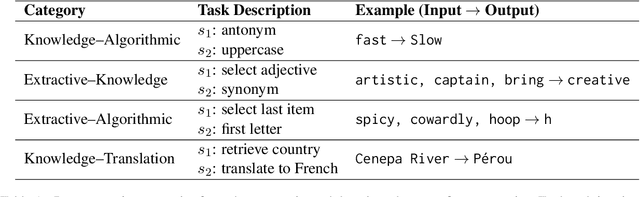


We show that large language models (LLMs) exhibit an $\textit{internal chain-of-thought}$: they sequentially decompose and execute composite tasks layer-by-layer. Two claims ground our study: (i) distinct subtasks are learned at different network depths, and (ii) these subtasks are executed sequentially across layers. On a benchmark of 15 two-step composite tasks, we employ layer-from context-masking and propose a novel cross-task patching method, confirming (i). To examine claim (ii), we apply LogitLens to decode hidden states, revealing a consistent layerwise execution pattern. We further replicate our analysis on the real-world $\text{TRACE}$ benchmark, observing the same stepwise dynamics. Together, our results enhance LLMs transparency by showing their capacity to internally plan and execute subtasks (or instructions), opening avenues for fine-grained, instruction-level activation steering.
UniMLVG: Unified Framework for Multi-view Long Video Generation with Comprehensive Control Capabilities for Autonomous Driving
Dec 06, 2024The creation of diverse and realistic driving scenarios has become essential to enhance perception and planning capabilities of the autonomous driving system. However, generating long-duration, surround-view consistent driving videos remains a significant challenge. To address this, we present UniMLVG, a unified framework designed to generate extended street multi-perspective videos under precise control. By integrating single- and multi-view driving videos into the training data, our approach updates cross-frame and cross-view modules across three stages with different training objectives, substantially boosting the diversity and quality of generated visual content. Additionally, we employ the explicit viewpoint modeling in multi-view video generation to effectively improve motion transition consistency. Capable of handling various input reference formats (e.g., text, images, or video), our UniMLVG generates high-quality multi-view videos according to the corresponding condition constraints such as 3D bounding boxes or frame-level text descriptions. Compared to the best models with similar capabilities, our framework achieves improvements of 21.4% in FID and 36.5% in FVD.
PSHuman: Photorealistic Single-view Human Reconstruction using Cross-Scale Diffusion
Sep 16, 2024



Detailed and photorealistic 3D human modeling is essential for various applications and has seen tremendous progress. However, full-body reconstruction from a monocular RGB image remains challenging due to the ill-posed nature of the problem and sophisticated clothing topology with self-occlusions. In this paper, we propose PSHuman, a novel framework that explicitly reconstructs human meshes utilizing priors from the multiview diffusion model. It is found that directly applying multiview diffusion on single-view human images leads to severe geometric distortions, especially on generated faces. To address it, we propose a cross-scale diffusion that models the joint probability distribution of global full-body shape and local facial characteristics, enabling detailed and identity-preserved novel-view generation without any geometric distortion. Moreover, to enhance cross-view body shape consistency of varied human poses, we condition the generative model on parametric models like SMPL-X, which provide body priors and prevent unnatural views inconsistent with human anatomy. Leveraging the generated multi-view normal and color images, we present SMPLX-initialized explicit human carving to recover realistic textured human meshes efficiently. Extensive experimental results and quantitative evaluations on CAPE and THuman2.1 datasets demonstrate PSHumans superiority in geometry details, texture fidelity, and generalization capability.
EA-RAS: Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton
Sep 03, 2024



Efficient, accurate and low-cost estimation of human skeletal information is crucial for a range of applications such as biology education and human-computer interaction. However, current simple skeleton models, which are typically based on 2D-3D joint points, fall short in terms of anatomical fidelity, restricting their utility in fields. On the other hand, more complex models while anatomically precise, are hindered by sophisticate multi-stage processing and the need for extra data like skin meshes, making them unsuitable for real-time applications. To this end, we propose the EA-RAS (Towards Efficient and Accurate End-to-End Reconstruction of Anatomical Skeleton), a single-stage, lightweight, and plug-and-play anatomical skeleton estimator that can provide real-time, accurate anatomically realistic skeletons with arbitrary pose using only a single RGB image input. Additionally, EA-RAS estimates the conventional human-mesh model explicitly, which not only enhances the functionality but also leverages the outside skin information by integrating features into the inside skeleton modeling process. In this work, we also develop a progressive training strategy and integrated it with an enhanced optimization process, enabling the network to obtain initial weights using only a small skin dataset and achieve self-supervision in skeleton reconstruction. Besides, we also provide an optional lightweight post-processing optimization strategy to further improve accuracy for scenarios that prioritize precision over real-time processing. The experiments demonstrated that our regression method is over 800 times faster than existing methods, meeting real-time requirements. Additionally, the post-processing optimization strategy provided can enhance reconstruction accuracy by over 50% and achieve a speed increase of more than 7 times.
Cross-Block Fine-Grained Semantic Cascade for Skeleton-Based Sports Action Recognition
Apr 30, 2024Human action video recognition has recently attracted more attention in applications such as video security and sports posture correction. Popular solutions, including graph convolutional networks (GCNs) that model the human skeleton as a spatiotemporal graph, have proven very effective. GCNs-based methods with stacked blocks usually utilize top-layer semantics for classification/annotation purposes. Although the global features learned through the procedure are suitable for the general classification, they have difficulty capturing fine-grained action change across adjacent frames -- decisive factors in sports actions. In this paper, we propose a novel ``Cross-block Fine-grained Semantic Cascade (CFSC)'' module to overcome this challenge. In summary, the proposed CFSC progressively integrates shallow visual knowledge into high-level blocks to allow networks to focus on action details. In particular, the CFSC module utilizes the GCN feature maps produced at different levels, as well as aggregated features from proceeding levels to consolidate fine-grained features. In addition, a dedicated temporal convolution is applied at each level to learn short-term temporal features, which will be carried over from shallow to deep layers to maximize the leverage of low-level details. This cross-block feature aggregation methodology, capable of mitigating the loss of fine-grained information, has resulted in improved performance. Last, FD-7, a new action recognition dataset for fencing sports, was collected and will be made publicly available. Experimental results and empirical analysis on public benchmarks (FSD-10) and self-collected (FD-7) demonstrate the advantage of our CFSC module on learning discriminative patterns for action classification over others.
Embedded Representation Learning Network for Animating Styled Video Portrait
Apr 29, 2024



The talking head generation recently attracted considerable attention due to its widespread application prospects, especially for digital avatars and 3D animation design. Inspired by this practical demand, several works explored Neural Radiance Fields (NeRF) to synthesize the talking heads. However, these methods based on NeRF face two challenges: (1) Difficulty in generating style-controllable talking heads. (2) Displacement artifacts around the neck in rendered images. To overcome these two challenges, we propose a novel generative paradigm \textit{Embedded Representation Learning Network} (ERLNet) with two learning stages. First, the \textit{ audio-driven FLAME} (ADF) module is constructed to produce facial expression and head pose sequences synchronized with content audio and style video. Second, given the sequence deduced by the ADF, one novel \textit{dual-branch fusion NeRF} (DBF-NeRF) explores these contents to render the final images. Extensive empirical studies demonstrate that the collaboration of these two stages effectively facilitates our method to render a more realistic talking head than the existing algorithms.
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Apr 29, 2024



Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
Sketch3D: Style-Consistent Guidance for Sketch-to-3D Generation
Apr 07, 2024Recently, image-to-3D approaches have achieved significant results with a natural image as input. However, it is not always possible to access these enriched color input samples in practical applications, where only sketches are available. Existing sketch-to-3D researches suffer from limitations in broad applications due to the challenges of lacking color information and multi-view content. To overcome them, this paper proposes a novel generation paradigm Sketch3D to generate realistic 3D assets with shape aligned with the input sketch and color matching the textual description. Concretely, Sketch3D first instantiates the given sketch in the reference image through the shape-preserving generation process. Second, the reference image is leveraged to deduce a coarse 3D Gaussian prior, and multi-view style-consistent guidance images are generated based on the renderings of the 3D Gaussians. Finally, three strategies are designed to optimize 3D Gaussians, i.e., structural optimization via a distribution transfer mechanism, color optimization with a straightforward MSE loss and sketch similarity optimization with a CLIP-based geometric similarity loss. Extensive visual comparisons and quantitative analysis illustrate the advantage of our Sketch3D in generating realistic 3D assets while preserving consistency with the input.