 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Learned Classifiers: an Information-theoretic Viewpoint of Training Deep Learning Classification Systems
Oct 03, 2022

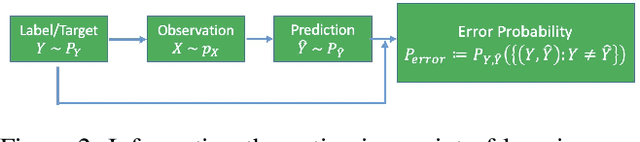

Deep learning systems have been reported to acheive state-of-the-art performances in many applications, and one of the keys for achieving this is the existence of well trained classifiers on benchmark datasets which can be used as backbone feature extractors in downstream tasks. As a main-stream loss function for training deep neural network (DNN) classifiers, the cross entropy loss can easily lead us to find models which demonstrate severe overfitting behavior when no other techniques are used for alleviating it such as data augmentation. In this paper, we prove that the existing cross entropy loss minimization for training DNN classifiers essentially learns the conditional entropy of the underlying data distribution of the dataset, i.e., the information or uncertainty remained in the labels after revealing the input. In this paper, we propose a mutual information learning framework where we train DNN classifiers via learning the mutual information between the label and input. Theoretically, we give the population error probability lower bound in terms of the mutual information. In addition, we derive the mutual information lower and upper bounds for a concrete binary classification data model in $\mbR^n$, and also the error probability lower bound in this scenario. Besides, we establish the sample complexity for accurately learning the mutual information from empirical data samples drawn from the underlying data distribution. Empirically, we conduct extensive experiments on several benchmark datasets to support our theory. Without whistles and bells, the proposed mutual information learned classifiers (MILCs) acheive far better generalization performances than the state-of-the-art classifiers with an improvement which can exceed more than 10\% in testing accuracy.
Pose-Aided Video-based Person Re-Identification via Recurrent Graph Convolutional Network
Sep 23, 2022

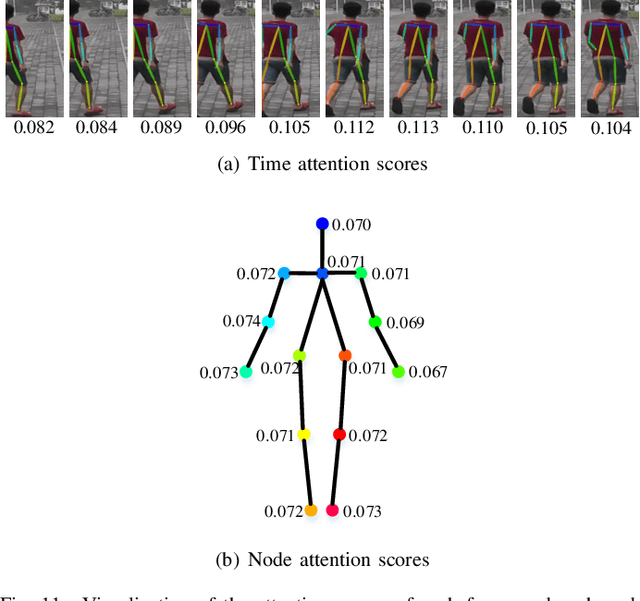
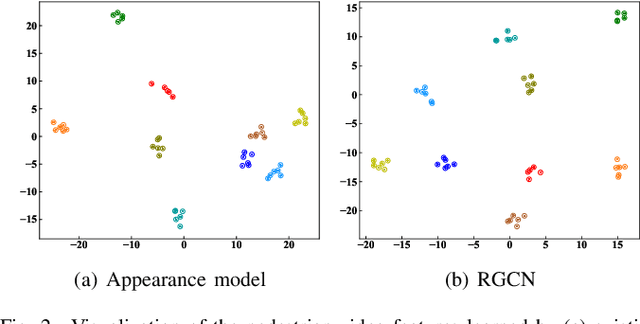
Existing methods for video-based person re-identification (ReID) mainly learn the appearance feature of a given pedestrian via a feature extractor and a feature aggregator. However, the appearance models would fail when different pedestrians have similar appearances. Considering that different pedestrians have different walking postures and body proportions, we propose to learn the discriminative pose feature beyond the appearance feature for video retrieval. Specifically, we implement a two-branch architecture to separately learn the appearance feature and pose feature, and then concatenate them together for inference. To learn the pose feature, we first detect the pedestrian pose in each frame through an off-the-shelf pose detector, and construct a temporal graph using the pose sequence. We then exploit a recurrent graph convolutional network (RGCN) to learn the node embeddings of the temporal pose graph, which devises a global information propagation mechanism to simultaneously achieve the neighborhood aggregation of intra-frame nodes and message passing among inter-frame graphs. Finally, we propose a dual-attention method consisting of node-attention and time-attention to obtain the temporal graph representation from the node embeddings, where the self-attention mechanism is employed to learn the importance of each node and each frame. We verify the proposed method on three video-based ReID datasets, i.e., Mars, DukeMTMC and iLIDS-VID, whose experimental results demonstrate that the learned pose feature can effectively improve the performance of existing appearance models.
Graph Convolutional Networks for Multi-modality Medical Imaging: Methods, Architectures, and Clinical Applications
Feb 17, 2022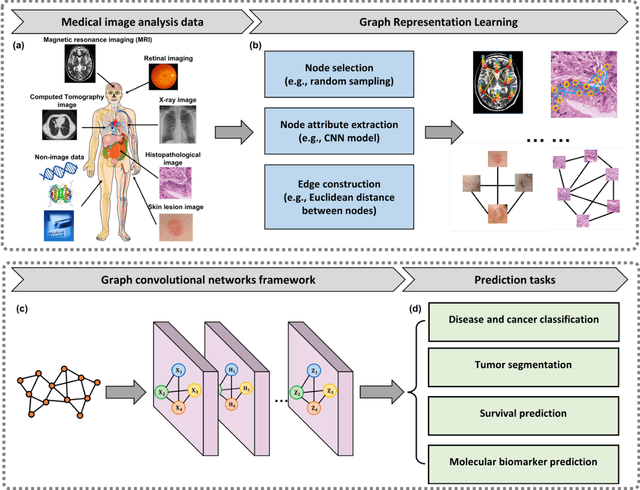

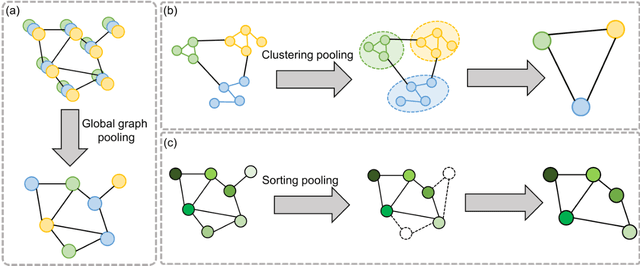
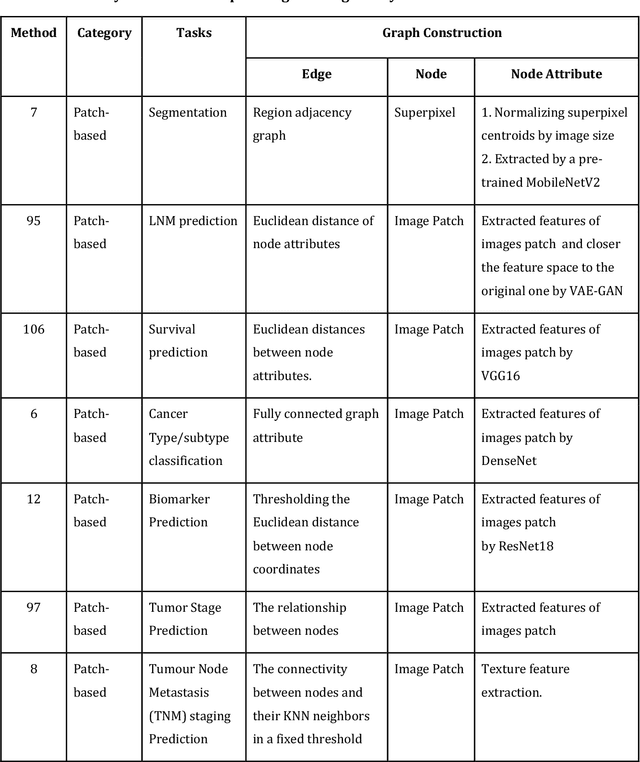
Image-based characterization and disease understanding involve integrative analysis of morphological, spatial, and topological information across biological scales. The development of graph convolutional networks (GCNs) has created the opportunity to address this information complexity via graph-driven architectures, since GCNs can perform feature aggregation, interaction, and reasoning with remarkable flexibility and efficiency. These GCNs capabilities have spawned a new wave of research in medical imaging analysis with the overarching goal of improving quantitative disease understanding, monitoring, and diagnosis. Yet daunting challenges remain for designing the important image-to-graph transformation for multi-modality medical imaging and gaining insights into model interpretation and enhanced clinical decision support. In this review, we present recent GCNs developments in the context of medical image analysis including imaging data from radiology and histopathology. We discuss the fast-growing use of graph network architectures in medical image analysis to improve disease diagnosis and patient outcomes in clinical practice. To foster cross-disciplinary research, we present GCNs technical advancements, emerging medical applications, identify common challenges in the use of image-based GCNs and their extensions in model interpretation, large-scale benchmarks that promise to transform the scope of medical image studies and related graph-driven medical research.
An Informative Tracking Benchmark
Dec 13, 2021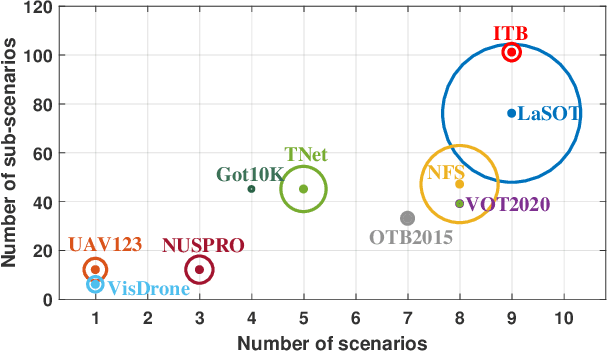
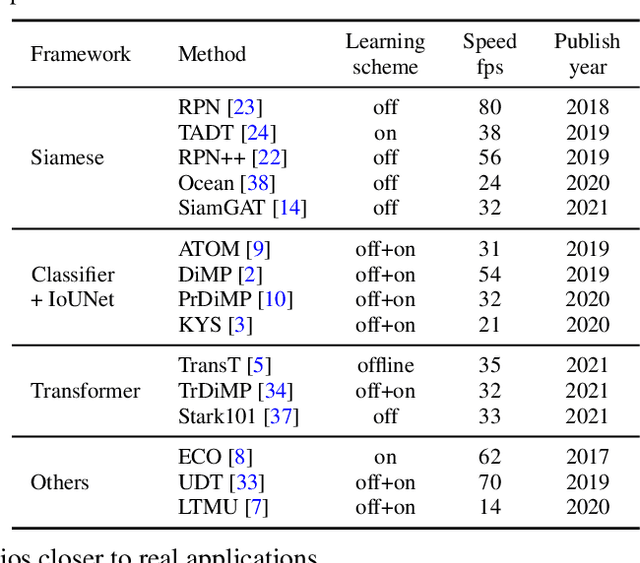
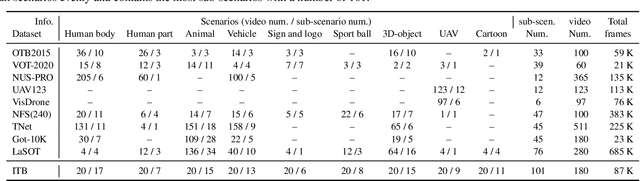
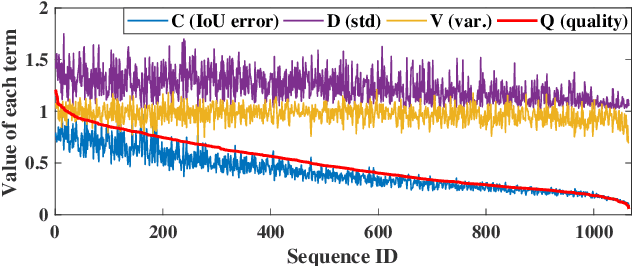
Along with the rapid progress of visual tracking, existing benchmarks become less informative due to redundancy of samples and weak discrimination between current trackers, making evaluations on all datasets extremely time-consuming. Thus, a small and informative benchmark, which covers all typical challenging scenarios to facilitate assessing the tracker performance, is of great interest. In this work, we develop a principled way to construct a small and informative tracking benchmark (ITB) with 7% out of 1.2 M frames of existing and newly collected datasets, which enables efficient evaluation while ensuring effectiveness. Specifically, we first design a quality assessment mechanism to select the most informative sequences from existing benchmarks taking into account 1) challenging level, 2) discriminative strength, 3) and density of appearance variations. Furthermore, we collect additional sequences to ensure the diversity and balance of tracking scenarios, leading to a total of 20 sequences for each scenario. By analyzing the results of 15 state-of-the-art trackers re-trained on the same data, we determine the effective methods for robust tracking under each scenario and demonstrate new challenges for future research direction in this field.
Active Learning for Deep Visual Tracking
Oct 17, 2021


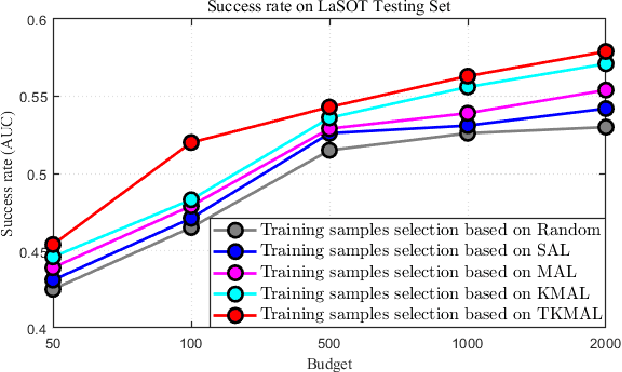
Convolutional neural networks (CNNs) have been successfully applied to the single target tracking task in recent years. Generally, training a deep CNN model requires numerous labeled training samples, and the number and quality of these samples directly affect the representational capability of the trained model. However, this approach is restrictive in practice, because manually labeling such a large number of training samples is time-consuming and prohibitively expensive. In this paper, we propose an active learning method for deep visual tracking, which selects and annotates the unlabeled samples to train the deep CNNs model. Under the guidance of active learning, the tracker based on the trained deep CNNs model can achieve competitive tracking performance while reducing the labeling cost. More specifically, to ensure the diversity of selected samples, we propose an active learning method based on multi-frame collaboration to select those training samples that should be and need to be annotated. Meanwhile, considering the representativeness of these selected samples, we adopt a nearest neighbor discrimination method based on the average nearest neighbor distance to screen isolated samples and low-quality samples. Therefore, the training samples subset selected based on our method requires only a given budget to maintain the diversity and representativeness of the entire sample set. Furthermore, we adopt a Tversky loss to improve the bounding box estimation of our tracker, which can ensure that the tracker achieves more accurate target states. Extensive experimental results confirm that our active learning-based tracker (ALT) achieves competitive tracking accuracy and speed compared with state-of-the-art trackers on the seven most challenging evaluation benchmarks.
Foster Strengths and Circumvent Weaknesses: a Speech Enhancement Framework with Two-branch Collaborative Learning
Oct 12, 2021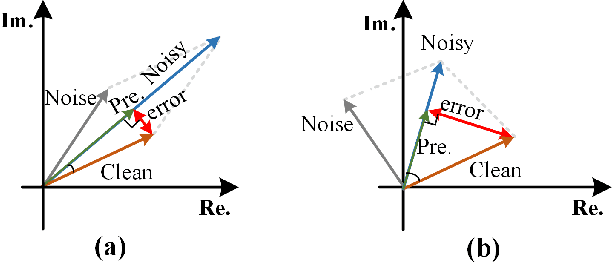
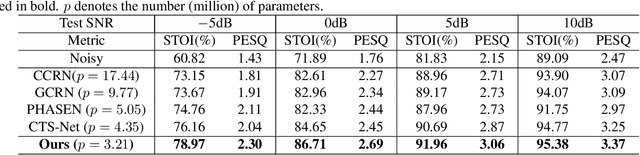
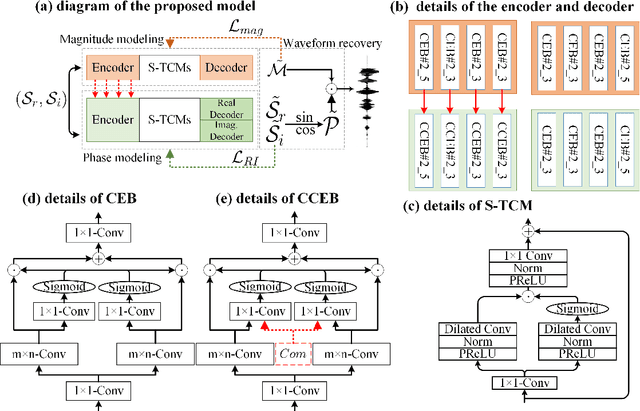
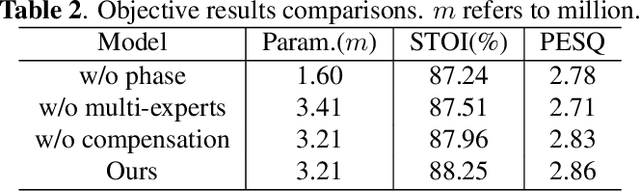
Recent single-channel speech enhancement methods usually convert waveform to the time-frequency domain and use magnitude/complex spectrum as the optimizing target. However, both magnitude-spectrum-based methods and complex-spectrum-based methods have their respective pros and cons. In this paper, we propose a unified two-branch framework to foster strengths and circumvent weaknesses of different paradigms. The proposed framework could take full advantage of the apparent spectral regularity in magnitude spectrogram and break the bottleneck that magnitude-based methods have suffered. Within each branch, we use collaborative expert block and its variants as substitutes for regular convolution layers. Experiments on TIMIT benchmark demonstrate that our method is superior to existing state-of-the-art ones.
Boost Neural Networks by Checkpoints
Oct 03, 2021
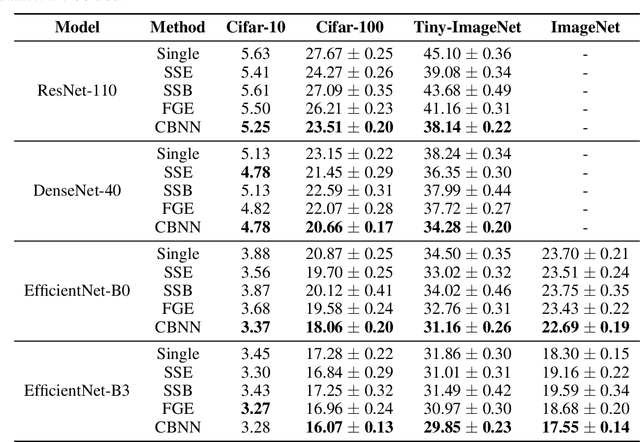
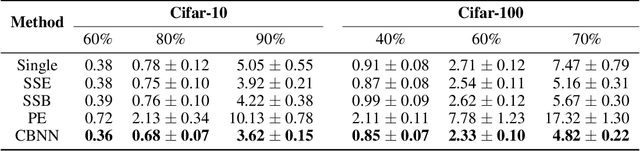
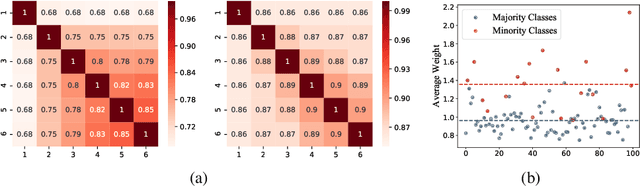
Training multiple deep neural networks (DNNs) and averaging their outputs is a simple way to improve the predictive performance. Nevertheless, the multiplied training cost prevents this ensemble method to be practical and efficient. Several recent works attempt to save and ensemble the checkpoints of DNNs, which only requires the same computational cost as training a single network. However, these methods suffer from either marginal accuracy improvements due to the low diversity of checkpoints or high risk of divergence due to the cyclical learning rates they adopted. In this paper, we propose a novel method to ensemble the checkpoints, where a boosting scheme is utilized to accelerate model convergence and maximize the checkpoint diversity. We theoretically prove that it converges by reducing exponential loss. The empirical evaluation also indicates our proposed ensemble outperforms single model and existing ensembles in terms of accuracy and efficiency. With the same training budget, our method achieves 4.16% lower error on Cifar-100 and 6.96% on Tiny-ImageNet with ResNet-110 architecture. Moreover, the adaptive sample weights in our method make it an effective solution to address the imbalanced class distribution. In the experiments, it yields up to 5.02% higher accuracy over single EfficientNet-B0 on the imbalanced datasets.
Relational Learning with Gated and Attentive Neighbor Aggregator for Few-Shot Knowledge Graph Completion
Apr 27, 2021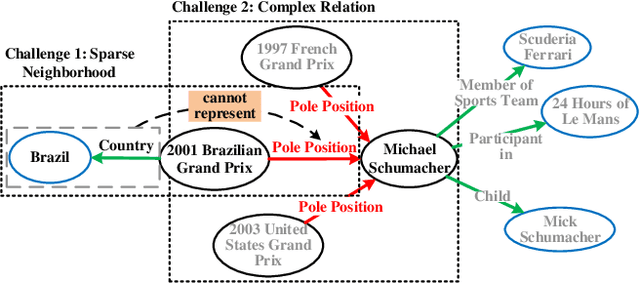

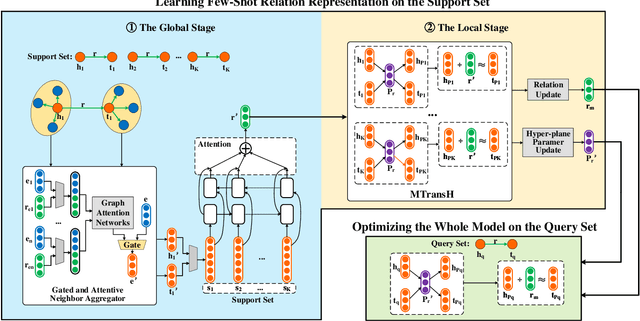
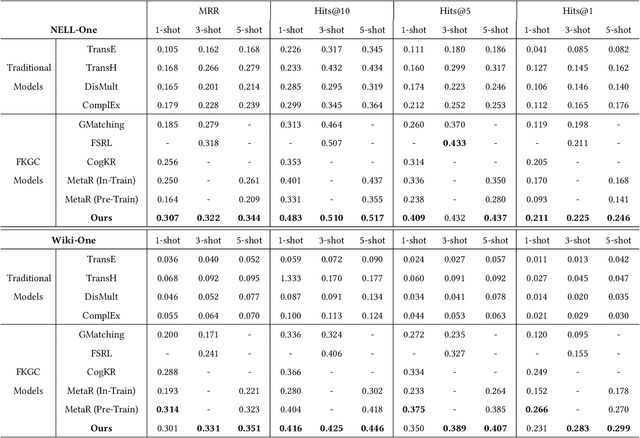
Aiming at expanding few-shot relations' coverage in knowledge graphs (KGs), few-shot knowledge graph completion (FKGC) has recently gained more research interests. Some existing models employ a few-shot relation's multi-hop neighbor information to enhance its semantic representation. However, noise neighbor information might be amplified when the neighborhood is excessively sparse and no neighbor is available to represent the few-shot relation. Moreover, modeling and inferring complex relations of one-to-many (1-N), many-to-one (N-1), and many-to-many (N-N) by previous knowledge graph completion approaches requires high model complexity and a large amount of training instances. Thus, inferring complex relations in the few-shot scenario is difficult for FKGC models due to limited training instances. In this paper, we propose a few-shot relational learning with global-local framework to address the above issues. At the global stage, a novel gated and attentive neighbor aggregator is built for accurately integrating the semantics of a few-shot relation's neighborhood, which helps filtering the noise neighbors even if a KG contains extremely sparse neighborhoods. For the local stage, a meta-learning based TransH (MTransH) method is designed to model complex relations and train our model in a few-shot learning fashion. Extensive experiments show that our model outperforms the state-of-the-art FKGC approaches on the frequently-used benchmark datasets NELL-One and Wiki-One. Compared with the strong baseline model MetaR, our model achieves 5-shot FKGC performance improvements of 8.0% on NELL-One and 2.8% on Wiki-One by the metric Hits@10.
Reinforced Molecular Optimization with Neighborhood-Controlled Grammars
Nov 14, 2020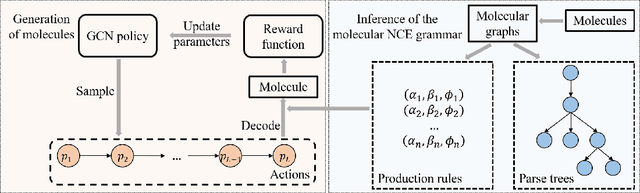
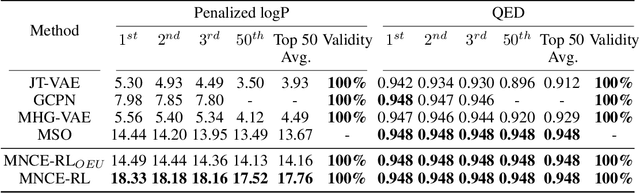
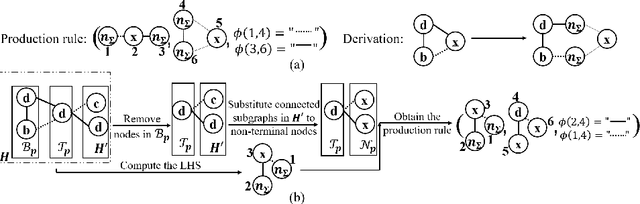
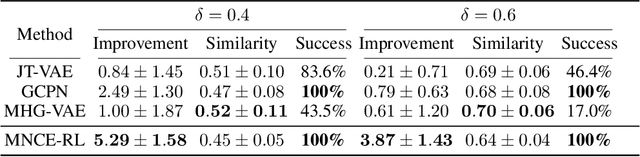
A major challenge in the pharmaceutical industry is to design novel molecules with specific desired properties, especially when the property evaluation is costly. Here, we propose MNCE-RL, a graph convolutional policy network for molecular optimization with molecular neighborhood-controlled embedding grammars through reinforcement learning. We extend the original neighborhood-controlled embedding grammars to make them applicable to molecular graph generation and design an efficient algorithm to infer grammatical production rules from given molecules. The use of grammars guarantees the validity of the generated molecular structures. By transforming molecular graphs to parse trees with the inferred grammars, the molecular structure generation task is modeled as a Markov decision process where a policy gradient strategy is utilized. In a series of experiments, we demonstrate that our approach achieves state-of-the-art performance in a diverse range of molecular optimization tasks and exhibits significant superiority in optimizing molecular properties with a limited number of property evaluations.
* 12 pages;two figures; NeurIPS 2020
LSOTB-TIR:A Large-Scale High-Diversity Thermal Infrared Object Tracking Benchmark
Aug 03, 2020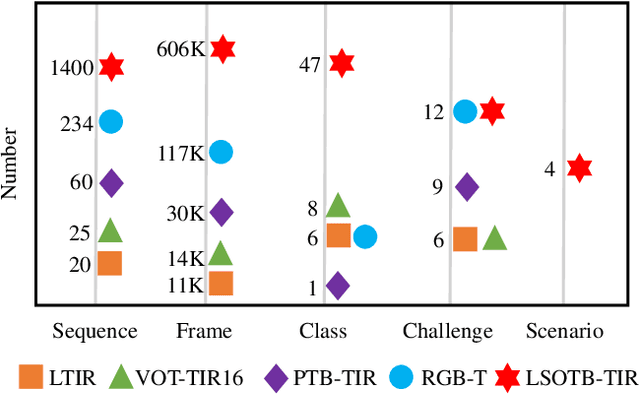
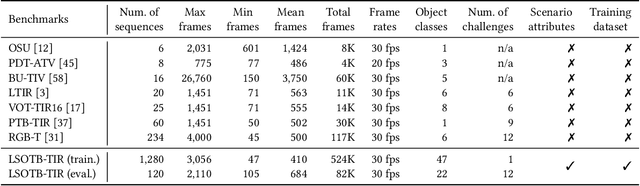
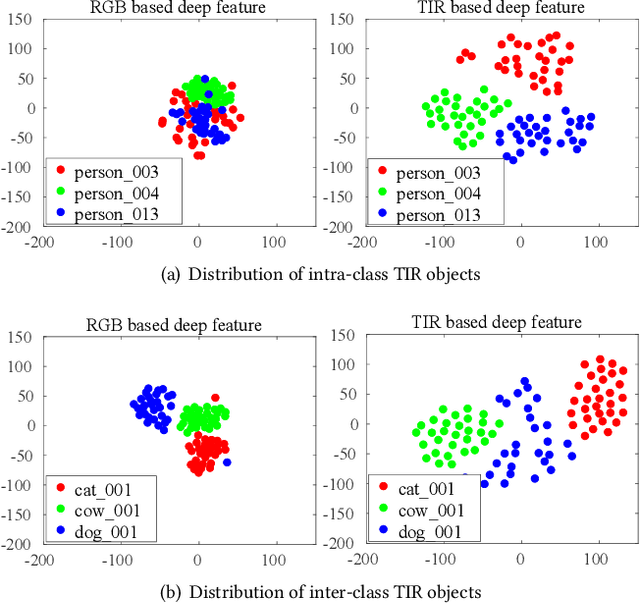
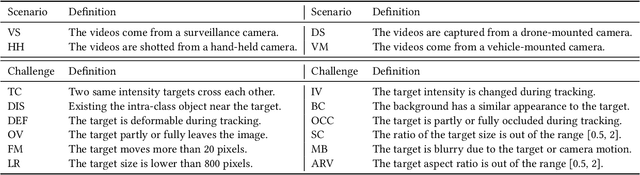
In this paper, we present a Large-Scale and high-diversity general Thermal InfraRed (TIR) Object Tracking Benchmark, called LSOTBTIR, which consists of an evaluation dataset and a training dataset with a total of 1,400 TIR sequences and more than 600K frames. We annotate the bounding box of objects in every frame of all sequences and generate over 730K bounding boxes in total. To the best of our knowledge, LSOTB-TIR is the largest and most diverse TIR object tracking benchmark to date. To evaluate a tracker on different attributes, we define 4 scenario attributes and 12 challenge attributes in the evaluation dataset. By releasing LSOTB-TIR, we encourage the community to develop deep learning based TIR trackers and evaluate them fairly and comprehensively. We evaluate and analyze more than 30 trackers on LSOTB-TIR to provide a series of baselines, and the results show that deep trackers achieve promising performance. Furthermore, we re-train several representative deep trackers on LSOTB-TIR, and their results demonstrate that the proposed training dataset significantly improves the performance of deep TIR trackers. Codes and dataset are available at https://github.com/QiaoLiuHit/LSOTB-TIR.