 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Routing for Federated Learning over Dynamic Satellite Networks: Tractable or Not?
Apr 21, 2026Federated learning (FL) is a key paradigm for distributed model learning across decentralized data sources. Communication in each FL round typically consists of two phases: (i) distributing the global model from a server to clients, and (ii) collecting updated local models from clients to the server for aggregation. This paper focuses on a type of FL where communication between a client and the server is relay-based over dynamic networks, making routing optimization essential. A typical scenario is in-orbit FL, where satellites act as clients and communicate with a server (which can be a satellite, ground station, or aerial platform) via multi-hop inter-satellite links. This paper presents a comprehensive tractability analysis of routing optimization for in-orbit FL under different settings. For global model distribution, these include the number of models, the objective function, and routing schemes (unicast versus multicast, and splittable versus unsplittable flow). For local model collection, the settings consider the number of models, client selection, and flow splittability. For each case, we rigorously prove whether the global optimum is obtainable in polynomial time or the problem is NP-hard. Together, our analysis draws clear boundaries between tractable and intractable regimes for a broad spectrum of routing problems for in-orbit FL. For tractable cases, the derived efficient algorithms are directly applicable in practice. For intractable cases, we provide fundamental insights into their inherent complexity. These contributions fill a critical yet unexplored research gap, laying a foundation for principled routing design, evaluation, and deployment in satellite-based FL or similar distributed learning systems.
FusionFM: All-in-One Multi-Modal Image Fusion with Flow Matching
Nov 17, 2025Current multi-modal image fusion methods typically rely on task-specific models, leading to high training costs and limited scalability. While generative methods provide a unified modeling perspective, they often suffer from slow inference due to the complex sampling trajectories from noise to image. To address this, we formulate image fusion as a direct probabilistic transport from source modalities to the fused image distribution, leveraging the flow matching paradigm to improve sampling efficiency and structural consistency. To mitigate the lack of high-quality fused images for supervision, we collect fusion results from multiple state-of-the-art models as priors, and employ a task-aware selection function to select the most reliable pseudo-labels for each task. We further introduce a Fusion Refiner module that employs a divide-and-conquer strategy to systematically identify, decompose, and enhance degraded components in selected pseudo-labels. For multi-task scenarios, we integrate elastic weight consolidation and experience replay mechanisms to preserve cross-task performance and enhance continual learning ability from both parameter stability and memory retention perspectives. Our approach achieves competitive performance across diverse fusion tasks, while significantly improving sampling efficiency and maintaining a lightweight model design. The code will be available at: https://github.com/Ist-Zhy/FusionFM.
Forecasting Spoken Language Development in Children with Cochlear Implants Using Preimplantation MRI
Nov 09, 2025Cochlear implants (CI) significantly improve spoken language in children with severe-to-profound sensorineural hearing loss (SNHL), yet outcomes remain more variable than in children with normal hearing. This variability cannot be reliably predicted for individual children using age at implantation or residual hearing. This study aims to compare the accuracy of traditional machine learning (ML) to deep transfer learning (DTL) algorithms to predict post-CI spoken language development of children with bilateral SNHL using a binary classification model of high versus low language improvers. A total of 278 implanted children enrolled from three centers. The accuracy, sensitivity and specificity of prediction models based upon brain neuroanatomic features using traditional ML and DTL learning. DTL prediction models using bilinear attention-based fusion strategy achieved: accuracy of 92.39% (95% CI, 90.70%-94.07%), sensitivity of 91.22% (95% CI, 89.98%-92.47%), specificity of 93.56% (95% CI, 90.91%-96.21%), and area under the curve (AUC) of 0.977 (95% CI, 0.969-0.986). DTL outperformed traditional ML models in all outcome measures. DTL was significantly improved by direct capture of discriminative and task-specific information that are advantages of representation learning enabled by this approach over ML. The results support the feasibility of a single DTL prediction model for language prediction of children served by CI programs worldwide.
WECAR: An End-Edge Collaborative Inference and Training Framework for WiFi-Based Continuous Human Activity Recognition
Mar 09, 2025WiFi-based human activity recognition (HAR) holds significant promise for ubiquitous sensing in smart environments. A critical challenge lies in enabling systems to dynamically adapt to evolving scenarios, learning new activities without catastrophic forgetting of prior knowledge, while adhering to the stringent computational constraints of edge devices. Current approaches struggle to reconcile these requirements due to prohibitive storage demands for retaining historical data and inefficient parameter utilization. We propose WECAR, an end-edge collaborative inference and training framework for WiFi-based continuous HAR, which decouples computational workloads to overcome these limitations. In this framework, edge devices handle model training, lightweight optimization, and updates, while end devices perform efficient inference. WECAR introduces two key innovations, i.e., dynamic continual learning with parameter efficiency and hierarchical distillation for end deployment. For the former, we propose a transformer-based architecture enhanced by task-specific dynamic model expansion and stability-aware selective retraining. For the latter, we propose a dual-phase distillation mechanism that includes multi-head self-attention relation distillation and prefix relation distillation. We implement WECAR based on heterogeneous hardware using Jetson Nano as edge devices and the ESP32 as end devices, respectively. Our experiments across three public WiFi datasets reveal that WECAR not only outperforms several state-of-the-art methods in performance and parameter efficiency, but also achieves a substantial reduction in the model's parameter count post-optimization without sacrificing accuracy. This validates its practicality for resource-constrained environments.
Affinity-Graph-Guided Contractive Learning for Pretext-Free Medical Image Segmentation with Minimal Annotation
Oct 14, 2024



The combination of semi-supervised learning (SemiSL) and contrastive learning (CL) has been successful in medical image segmentation with limited annotations. However, these works often rely on pretext tasks that lack the specificity required for pixel-level segmentation, and still face overfitting issues due to insufficient supervision signals resulting from too few annotations. Therefore, this paper proposes an affinity-graph-guided semi-supervised contrastive learning framework (Semi-AGCL) by establishing additional affinity-graph-based supervision signals between the student and teacher network, to achieve medical image segmentation with minimal annotations without pretext. The framework first designs an average-patch-entropy-driven inter-patch sampling method, which can provide a robust initial feature space without relying on pretext tasks. Furthermore, the framework designs an affinity-graph-guided loss function, which can improve the quality of the learned representation and the model generalization ability by exploiting the inherent structure of the data, thus mitigating overfitting. Our experiments indicate that with merely 10% of the complete annotation set, our model approaches the accuracy of the fully annotated baseline, manifesting a marginal deviation of only 2.52%. Under the stringent conditions where only 5% of the annotations are employed, our model exhibits a significant enhancement in performance surpassing the second best baseline by 23.09% on the dice metric and achieving an improvement of 26.57% on the notably arduous CRAG and ACDC datasets.
Online Learning for Intelligent Thermal Management of Interference-coupled and Passively Cooled Base Stations
Oct 11, 2024



Passively cooled base stations (PCBSs) have emerged to deliver better cost and energy efficiency. However, passive cooling necessitates intelligent thermal control via traffic management, i.e., the instantaneous data traffic or throughput of a PCBS directly impacts its thermal performance. This is particularly challenging for outdoor deployment of PCBSs because the heat dissipation efficiency is uncertain and fluctuates over time. What is more, the PCBSs are interference-coupled in multi-cell scenarios. Thus, a higher-throughput PCBS leads to higher interference to the other PCBSs, which, in turn, would require more resource consumption to meet their respective throughput targets. In this paper, we address online decision-making for maximizing the total downlink throughput for a multi-PCBS system subject to constraints related on operating temperature. We demonstrate that a reinforcement learning (RL) approach, specifically soft actor-critic (SAC), can successfully perform throughput maximization while keeping the PCBSs cool, by adapting the throughput to time-varying heat dissipation conditions. Furthermore, we design a denial and reward mechanism that effectively mitigates the risk of overheating during the exploration phase of RL. Simulation results show that our approach achieves up to 88.6% of the global optimum. This is very promising, as our approach operates without prior knowledge of future heat dissipation efficiency, which is required by the global optimum.
Progressive Domain Adaptation for Thermal Infrared Object Tracking
Jul 28, 2024



Due to the lack of large-scale labeled Thermal InfraRed (TIR) training datasets, most existing TIR trackers are trained directly on RGB datasets. However, tracking methods trained on RGB datasets suffer a significant drop-off in TIR data due to the domain shift issue. To this end, in this work, we propose a Progressive Domain Adaptation framework for TIR Tracking (PDAT), which transfers useful knowledge learned from RGB tracking to TIR tracking. The framework makes full use of large-scale labeled RGB datasets without requiring time-consuming and labor-intensive labeling of large-scale TIR data. Specifically, we first propose an adversarial-based global domain adaptation module to reduce domain gap on the feature level coarsely. Second, we design a clustering-based subdomain adaptation method to further align the feature distributions of the RGB and TIR datasets finely. These two domain adaptation modules gradually eliminate the discrepancy between the two domains, and thus learn domain-invariant fine-grained features through progressive training. Additionally, we collect a largescale TIR dataset with over 1.48 million unlabeled TIR images for training the proposed domain adaptation framework. Experimental results on five TIR tracking benchmarks show that the proposed method gains a nearly 6% success rate, demonstrating its effectiveness.
D2D-Assisted Mobile Edge Computing: Optimal Scheduling under Uncertain Processing Cycles and Intermittent Communications
Sep 08, 2023



Mobile edge computing (MEC) has been regarded as a promising approach to deal with explosive computation requirements by enabling cloud computing capabilities at the edge of networks. Existing models of MEC impose some strong assumptions on the known processing cycles and unintermittent communications. However, practical MEC systems are constrained by various uncertainties and intermittent communications, rendering these assumptions impractical. In view of this, we investigate how to schedule task offloading in MEC systems with uncertainties. First, we derive a closed-form expression of the average offloading success probability in a device-to-device (D2D) assisted MEC system with uncertain computation processing cycles and intermittent communications. Then, we formulate a task offloading maximization problem (TOMP), and prove that the problem is NP-hard. For problem solving, if the problem instance exhibits a symmetric structure, we propose a task scheduling algorithm based on dynamic programming (TSDP). By solving this problem instance, we derive a bound to benchmark sub-optimal algorithm. For general scenarios, by reformulating the problem, we propose a repeated matching algorithm (RMA). Finally, in performance evaluations, we validate the accuracy of the closed-form expression of the average offloading success probability by Monte Carlo simulations, as well as the effectiveness of the proposed algorithms.
Active Learning for Deep Visual Tracking
Oct 17, 2021


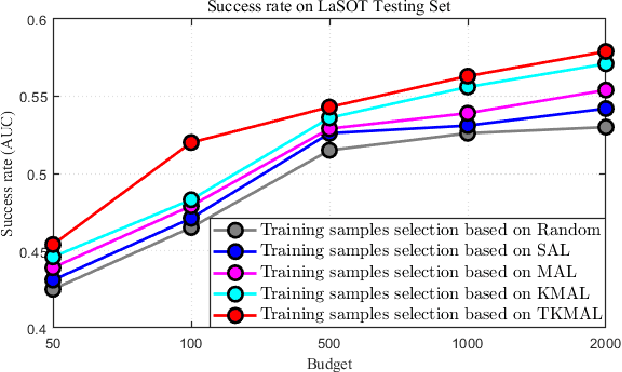
Convolutional neural networks (CNNs) have been successfully applied to the single target tracking task in recent years. Generally, training a deep CNN model requires numerous labeled training samples, and the number and quality of these samples directly affect the representational capability of the trained model. However, this approach is restrictive in practice, because manually labeling such a large number of training samples is time-consuming and prohibitively expensive. In this paper, we propose an active learning method for deep visual tracking, which selects and annotates the unlabeled samples to train the deep CNNs model. Under the guidance of active learning, the tracker based on the trained deep CNNs model can achieve competitive tracking performance while reducing the labeling cost. More specifically, to ensure the diversity of selected samples, we propose an active learning method based on multi-frame collaboration to select those training samples that should be and need to be annotated. Meanwhile, considering the representativeness of these selected samples, we adopt a nearest neighbor discrimination method based on the average nearest neighbor distance to screen isolated samples and low-quality samples. Therefore, the training samples subset selected based on our method requires only a given budget to maintain the diversity and representativeness of the entire sample set. Furthermore, we adopt a Tversky loss to improve the bounding box estimation of our tracker, which can ensure that the tracker achieves more accurate target states. Extensive experimental results confirm that our active learning-based tracker (ALT) achieves competitive tracking accuracy and speed compared with state-of-the-art trackers on the seven most challenging evaluation benchmarks.
SiamCorners: Siamese Corner Networks for Visual Tracking
Apr 15, 2021
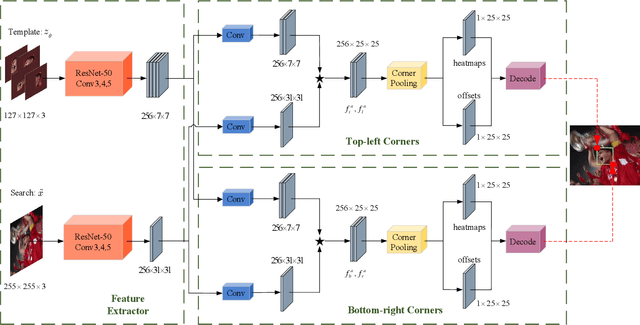


The current Siamese network based on region proposal network (RPN) has attracted great attention in visual tracking due to its excellent accuracy and high efficiency. However, the design of the RPN involves the selection of the number, scale, and aspect ratios of anchor boxes, which will affect the applicability and convenience of the model. Furthermore, these anchor boxes require complicated calculations, such as calculating their intersection-over-union (IoU) with ground truth bounding boxes.Due to the problems related to anchor boxes, we propose a simple yet effective anchor-free tracker (named Siamese corner networks, SiamCorners), which is end-to-end trained offline on large-scale image pairs. Specifically, we introduce a modified corner pooling layer to convert the bounding box estimate of the target into a pair of corner predictions (the bottom-right and the top-left corners). By tracking a target as a pair of corners, we avoid the need to design the anchor boxes. This will make the entire tracking algorithm more flexible and simple than anchorbased trackers. In our network design, we further introduce a layer-wise feature aggregation strategy that enables the corner pooling module to predict multiple corners for a tracking target in deep networks. We then introduce a new penalty term that is used to select an optimal tracking box in these candidate corners. Finally, SiamCorners achieves experimental results that are comparable to the state-of-art tracker while maintaining a high running speed. In particular, SiamCorners achieves a 53.7% AUC on NFS30 and a 61.4% AUC on UAV123, while still running at 42 frames per second (FPS).