 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix2Key: Controllable Open-Vocabulary Retrieval with Semantic Decomposition and Self-Supervised Visual Dictionary Learning
Feb 26, 2026Composed Image Retrieval (CIR) uses a reference image plus a natural-language edit to retrieve images that apply the requested change while preserving other relevant visual content. Classic fusion pipelines typically rely on supervised triplets and can lose fine-grained cues, while recent zero-shot approaches often caption the reference image and merge the caption with the edit, which may miss implicit user intent and return repetitive results. We present Pix2Key, which represents both queries and candidates as open-vocabulary visual dictionaries, enabling intent-aware constraint matching and diversity-aware reranking in a unified embedding space. A self-supervised pretraining component, V-Dict-AE, further improves the dictionary representation using only images, strengthening fine-grained attribute understanding without CIR-specific supervision. On the DFMM-Compose benchmark, Pix2Key improves Recall@10 up to 3.2 points, and adding V-Dict-AE yields an additional 2.3-point gain while improving intent consistency and maintaining high list diversity.
ViT-Linearizer: Distilling Quadratic Knowledge into Linear-Time Vision Models
Mar 30, 2025



Vision Transformers (ViTs) have delivered remarkable progress through global self-attention, yet their quadratic complexity can become prohibitive for high-resolution inputs. In this work, we present ViT-Linearizer, a cross-architecture distillation framework that transfers rich ViT representations into a linear-time, recurrent-style model. Our approach leverages 1) activation matching, an intermediate constraint that encourages student to align its token-wise dependencies with those produced by the teacher, and 2) masked prediction, a contextual reconstruction objective that requires the student to predict the teacher's representations for unseen (masked) tokens, to effectively distill the quadratic self-attention knowledge into the student while maintaining efficient complexity. Empirically, our method provides notable speedups particularly for high-resolution tasks, significantly addressing the hardware challenges in inference. Additionally, it also elevates Mamba-based architectures' performance on standard vision benchmarks, achieving a competitive 84.3% top-1 accuracy on ImageNet with a base-sized model. Our results underscore the good potential of RNN-based solutions for large-scale visual tasks, bridging the gap between theoretical efficiency and real-world practice.
Scaling Laws in Patchification: An Image Is Worth 50,176 Tokens And More
Feb 06, 2025Since the introduction of Vision Transformer (ViT), patchification has long been regarded as a de facto image tokenization approach for plain visual architectures. By compressing the spatial size of images, this approach can effectively shorten the token sequence and reduce the computational cost of ViT-like plain architectures. In this work, we aim to thoroughly examine the information loss caused by this patchification-based compressive encoding paradigm and how it affects visual understanding. We conduct extensive patch size scaling experiments and excitedly observe an intriguing scaling law in patchification: the models can consistently benefit from decreased patch sizes and attain improved predictive performance, until it reaches the minimum patch size of 1x1, i.e., pixel tokenization. This conclusion is broadly applicable across different vision tasks, various input scales, and diverse architectures such as ViT and the recent Mamba models. Moreover, as a by-product, we discover that with smaller patches, task-specific decoder heads become less critical for dense prediction. In the experiments, we successfully scale up the visual sequence to an exceptional length of 50,176 tokens, achieving a competitive test accuracy of 84.6% with a base-sized model on the ImageNet-1k benchmark. We hope this study can provide insights and theoretical foundations for future works of building non-compressive vision models. Code is available at https://github.com/wangf3014/Patch_Scaling.
Causal Image Modeling for Efficient Visual Understanding
Oct 10, 2024



In this work, we present a comprehensive analysis of causal image modeling and introduce the Adventurer series models where we treat images as sequences of patch tokens and employ uni-directional language models to learn visual representations. This modeling paradigm allows us to process images in a recurrent formulation with linear complexity relative to the sequence length, which can effectively address the memory and computation explosion issues posed by high-resolution and fine-grained images. In detail, we introduce two simple designs that seamlessly integrate image inputs into the causal inference framework: a global pooling token placed at the beginning of the sequence and a flipping operation between every two layers. Extensive empirical studies demonstrate the significant efficiency and effectiveness of this causal image modeling paradigm. For example, our base-sized Adventurer model attains a competitive test accuracy of 84.0% on the standard ImageNet-1k benchmark with 216 images/s training throughput, which is 5.3 times more efficient than vision transformers to achieve the same result.
Mamba-R: Vision Mamba ALSO Needs Registers
May 23, 2024



Similar to Vision Transformers, this paper identifies artifacts also present within the feature maps of Vision Mamba. These artifacts, corresponding to high-norm tokens emerging in low-information background areas of images, appear much more severe in Vision Mamba -- they exist prevalently even with the tiny-sized model and activate extensively across background regions. To mitigate this issue, we follow the prior solution of introducing register tokens into Vision Mamba. To better cope with Mamba blocks' uni-directional inference paradigm, two key modifications are introduced: 1) evenly inserting registers throughout the input token sequence, and 2) recycling registers for final decision predictions. We term this new architecture Mamba-R. Qualitative observations suggest, compared to vanilla Vision Mamba, Mamba-R's feature maps appear cleaner and more focused on semantically meaningful regions. Quantitatively, Mamba-R attains stronger performance and scales better. For example, on the ImageNet benchmark, our base-size Mamba-R attains 82.9% accuracy, significantly outperforming Vim-B's 81.8%; furthermore, we provide the first successful scaling to the large model size (i.e., with 341M parameters), attaining a competitive accuracy of 83.2% (84.5% if finetuned with 384x384 inputs). Additional validation on the downstream semantic segmentation task also supports Mamba-R's efficacy.
Dual Prompt Tuning for Domain-Aware Federated Learning
Oct 04, 2023



Federated learning is a distributed machine learning paradigm that allows multiple clients to collaboratively train a shared model with their local data. Nonetheless, conventional federated learning algorithms often struggle to generalize well due to the ubiquitous domain shift across clients. In this work, we consider a challenging yet realistic federated learning scenario where the training data of each client originates from different domains. We address the challenges of domain shift by leveraging the technique of prompt learning, and propose a novel method called Federated Dual Prompt Tuning (Fed-DPT). Specifically, Fed-DPT employs a pre-trained vision-language model and then applies both visual and textual prompt tuning to facilitate domain adaptation over decentralized data. Extensive experiments of Fed-DPT demonstrate its significant effectiveness in domain-aware federated learning. With a pre-trained CLIP model (ViT-Base as image encoder), the proposed Fed-DPT attains 68.4% average accuracy over six domains in the DomainNet dataset, which improves the original CLIP by a large margin of 14.8%.
Boost Neural Networks by Checkpoints
Oct 03, 2021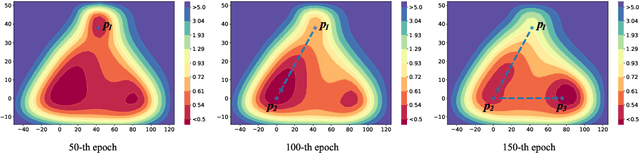
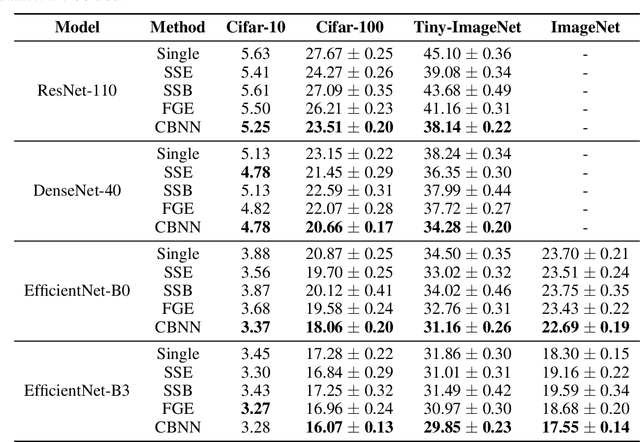
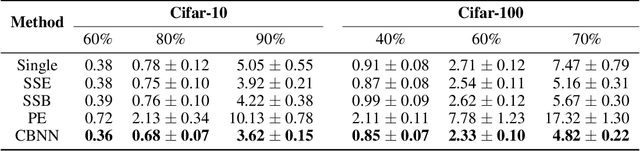
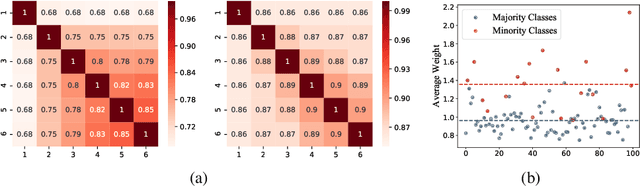
Training multiple deep neural networks (DNNs) and averaging their outputs is a simple way to improve the predictive performance. Nevertheless, the multiplied training cost prevents this ensemble method to be practical and efficient. Several recent works attempt to save and ensemble the checkpoints of DNNs, which only requires the same computational cost as training a single network. However, these methods suffer from either marginal accuracy improvements due to the low diversity of checkpoints or high risk of divergence due to the cyclical learning rates they adopted. In this paper, we propose a novel method to ensemble the checkpoints, where a boosting scheme is utilized to accelerate model convergence and maximize the checkpoint diversity. We theoretically prove that it converges by reducing exponential loss. The empirical evaluation also indicates our proposed ensemble outperforms single model and existing ensembles in terms of accuracy and efficiency. With the same training budget, our method achieves 4.16% lower error on Cifar-100 and 6.96% on Tiny-ImageNet with ResNet-110 architecture. Moreover, the adaptive sample weights in our method make it an effective solution to address the imbalanced class distribution. In the experiments, it yields up to 5.02% higher accuracy over single EfficientNet-B0 on the imbalanced datasets.