 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Making Bias Non-Predictive: Training Robust LLM Judges via Reinforcement Learning
Feb 02, 2026Large language models (LLMs) increasingly serve as automated judges, yet they remain susceptible to cognitive biases -- often altering their reasoning when faced with spurious prompt-level cues such as consensus claims or authority appeals. Existing mitigations via prompting or supervised fine-tuning fail to generalize, as they modify surface behavior without changing the optimization objective that makes bias cues predictive. To address this gap, we propose Epistemic Independence Training (EIT), a reinforcement learning framework grounded in a key principle: to learn independence, bias cues must be made non-predictive of reward. EIT operationalizes this through a balanced conflict strategy where bias signals are equally likely to support correct and incorrect answers, combined with a reward design that penalizes bias-following without rewarding bias agreement. Experiments on Qwen3-4B demonstrate that EIT improves both accuracy and robustness under adversarial biases, while preserving performance when bias aligns with truth. Notably, models trained only on bandwagon bias generalize to unseen bias types such as authority and distraction, indicating that EIT induces transferable epistemic independence rather than bias-specific heuristics. Code and data are available at https://anonymous.4open.science/r/bias-mitigation-with-rl-BC47.
The Shadow Self: Intrinsic Value Misalignment in Large Language Model Agents
Jan 24, 2026Large language model (LLM) agents with extended autonomy unlock new capabilities, but also introduce heightened challenges for LLM safety. In particular, an LLM agent may pursue objectives that deviate from human values and ethical norms, a risk known as value misalignment. Existing evaluations primarily focus on responses to explicit harmful input or robustness against system failure, while value misalignment in realistic, fully benign, and agentic settings remains largely underexplored. To fill this gap, we first formalize the Loss-of-Control risk and identify the previously underexamined Intrinsic Value Misalignment (Intrinsic VM). We then introduce IMPRESS (Intrinsic Value Misalignment Probes in REalistic Scenario Set), a scenario-driven framework for systematically assessing this risk. Following our framework, we construct benchmarks composed of realistic, fully benign, and contextualized scenarios, using a multi-stage LLM generation pipeline with rigorous quality control. We evaluate Intrinsic VM on 21 state-of-the-art LLM agents and find that it is a common and broadly observed safety risk across models. Moreover, the misalignment rates vary by motives, risk types, model scales, and architectures. While decoding strategies and hyperparameters exhibit only marginal influence, contextualization and framing mechanisms significantly shape misalignment behaviors. Finally, we conduct human verification to validate our automated judgments and assess existing mitigation strategies, such as safety prompting and guardrails, which show instability or limited effectiveness. We further demonstrate key use cases of IMPRESS across the AI Ecosystem. Our code and benchmark will be publicly released upon acceptance.
Time Travel Engine: A Shared Latent Chronological Manifold Enables Historical Navigation in Large Language Models
Jan 10, 2026Time functions as a fundamental dimension of human cognition, yet the mechanisms by which Large Language Models (LLMs) encode chronological progression remain opaque. We demonstrate that temporal information in their latent space is organized not as discrete clusters but as a continuous, traversable geometry. We introduce the Time Travel Engine (TTE), an interpretability-driven framework that projects diachronic linguistic patterns onto a shared chronological manifold. Unlike surface-level prompting, TTE directly modulates latent representations to induce coherent stylistic, lexical, and conceptual shifts aligned with target eras. By parameterizing diachronic evolution as a continuous manifold within the residual stream, TTE enables fluid navigation through period-specific "zeitgeists" while restricting access to future knowledge. Furthermore, experiments across diverse architectures reveal topological isomorphism between the temporal subspaces of Chinese and English-indicating that distinct languages share a universal geometric logic of historical evolution. These findings bridge historical linguistics with mechanistic interpretability, offering a novel paradigm for controlling temporal reasoning in neural networks.
Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
Subsecond 3D Mesh Generation for Robot Manipulation
Dec 30, 20253D meshes are a fundamental representation widely used in computer science and engineering. In robotics, they are particularly valuable because they capture objects in a form that aligns directly with how robots interact with the physical world, enabling core capabilities such as predicting stable grasps, detecting collisions, and simulating dynamics. Although automatic 3D mesh generation methods have shown promising progress in recent years, potentially offering a path toward real-time robot perception, two critical challenges remain. First, generating high-fidelity meshes is prohibitively slow for real-time use, often requiring tens of seconds per object. Second, mesh generation by itself is insufficient. In robotics, a mesh must be contextually grounded, i.e., correctly segmented from the scene and registered with the proper scale and pose. Additionally, unless these contextual grounding steps remain efficient, they simply introduce new bottlenecks. In this work, we introduce an end-to-end system that addresses these challenges, producing a high-quality, contextually grounded 3D mesh from a single RGB-D image in under one second. Our pipeline integrates open-vocabulary object segmentation, accelerated diffusion-based mesh generation, and robust point cloud registration, each optimized for both speed and accuracy. We demonstrate its effectiveness in a real-world manipulation task, showing that it enables meshes to be used as a practical, on-demand representation for robotics perception and planning.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
MEPIC: Memory Efficient Position Independent Caching for LLM Serving
Dec 18, 2025Modern LLM applications such as deep-research assistants, coding agents, and Retrieval-Augmented Generation (RAG) systems, repeatedly process long prompt histories containing shared document or code chunks, creating significant pressure on the Key Value (KV) cache, which must operate within limited memory while sustaining high throughput and low latency. Prefix caching partially alleviates some of these costs by reusing KV cache for previously processed tokens, but limited by strict prefix matching. Position-independent caching (PIC) enables chunk-level reuse at arbitrary positions, but requires selective recomputation and positional-encoding (PE) adjustments. However, because these operations vary across queries, KV for the same chunk diverges across requests. Moreover, without page alignment, chunk KV layouts diverge in memory, preventing page sharing. These issues result in only modest HBM savings even when many requests reuse the same content. We present MEPIC, a memory-efficient PIC system that enables chunk KV reuse across positions, requests, and batches. MEPIC aligns chunk KV to paged storage, shifts recomputation from token- to block-level so only the first block is request-specific, removes positional encodings via Rotary Position Embedding (RoPE) fusion in the attention kernel, and makes remaining blocks fully shareable. These techniques eliminate most duplicate chunk KV in HBM, reducing usage by up to 2x over state-of-the-art PIC at comparable latency and accuracy, and up to 5x for long prompts, without any model changes.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025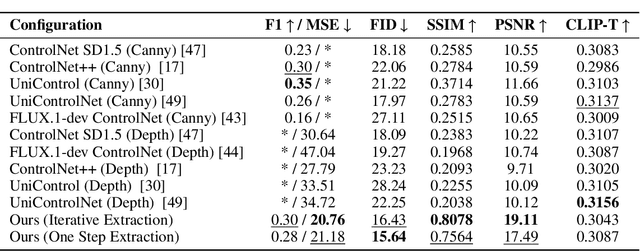
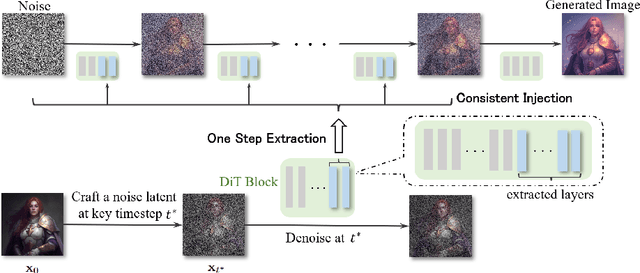
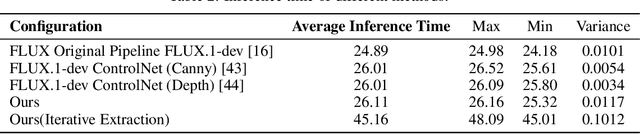

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.