 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimInsert: Seamless Video Object Insertion via Regional Sparse Attention Fusion
May 22, 2026Video object insertion requires ensuring spatio-temporal coherence and interactive realism, extending far beyond simple content placement. However, current approaches are often hindered by a reliance on explicit motion engineering or resource-intensive retraining, restricting their flexibility and generalization. To bridge this gap, we present \textit{SimInsert}, a training-free paradigm that efficiently decouples the task into intuitive single-frame editing and semantic motion description. By harnessing the robust generative priors of image-to-video diffusion models, SimInsert propagates edits temporally, strictly preserving background invariance while enabling plausible, text-driven interactions between the inserted object and the dynamic environment. Our approach hinges on non-invasive guidance mechanisms that enforce structural consistency, facilitate seamless boundary fusion, and counteract the fidelity drift that typically accumulates during the denoising trajectory. Extensive quantitative experiments validate our efficacy: SimInsert surpasses state-of-the-art methods with an 18.8\% gain in PSNR, 20.1\% in SSIM, and a 44.1\% decrease in LPIPS, offering a streamlined solution for high-fidelity video editing.
PhysLayer: Language-Guided Layered Animation with Depth-Aware Physics
Apr 26, 2026Existing image-to-video generation methods often produce physically implausible motions and lack precise control over object dynamics. While prior approaches have incorporated physics simulators, they remain confined to 2D planar motions and fail to capture depth-aware spatial interactions. We introduce PhysLayer, a novel framework enabling language-guided, depth-aware layered animation of static images. PhysLayer consists of three key components: First, a language-guided scene understanding module that utilizes vision foundation models to decompose scenes into depth-based layers by analyzing object composition, material properties, and physical parameters. Second, a depth-aware layered physics simulation that extends 2D rigid-body dynamics with depth motion and perspective-consistent scaling, enabling more realistic object interactions without requiring full 3D reconstruction. Third, a physics-guided video synthesis module that integrates simulated trajectories with scene-aware relighting for temporally coherent results. Experimental results demonstrate improvements in CLIP-Similarity (+2.2\%), FID score (+9.3\%), and Motion-FID (+3\%), with human evaluation showing enhanced physical plausibility (+24\%) and text-video alignment (+35\%). Our approach provides a practical balance between physical realism and computational efficiency for controllable image animation.
PhysCodeBench: Benchmarking Physics-Aware Symbolic Simulation of 3D Scenes via Self-Corrective Multi-Agent Refinement
Apr 26, 2026Physics-aware symbolic simulation of 3D scenes is critical for robotics, embodied AI, and scientific computing, requiring models to understand natural language descriptions of physical phenomena and translate them into executable simulation environments. While large language models (LLMs) excel at general code generation, they struggle with the semantic gap between physical descriptions and simulation implementation. We introduce PhysCodeBench, the first comprehensive benchmark for evaluating physics-aware symbolic simulation, comprising 700 manually-crafted diverse samples across mechanics, fluid dynamics, and soft-body physics with expert annotations. Our evaluation framework measures both code executability and physical accuracy through automated and visual assessment. Building on this, we propose a Self-Corrective Multi-Agent Refinement Framework (SMRF) with three specialized agents (simulation generator, error corrector, and simulation refiner) that collaborate iteratively with domain-specific validation to produce physically accurate simulations. SMRF achieves 67.7 points overall performance compared to 36.3 points for the best baseline among evaluated SOTA models, representing a 31.4-point improvement. Our analysis demonstrates that error correction is critical for accurate physics-aware symbolic simulation and that specialized multi-agent approaches significantly outperform single-agent methods across the tested physical domains.
FreeControl: Efficient, Training-Free Structural Control via One-Step Attention Extraction
Nov 07, 2025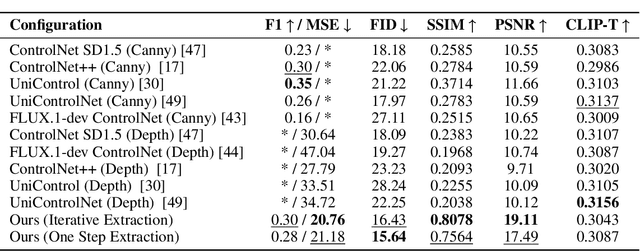
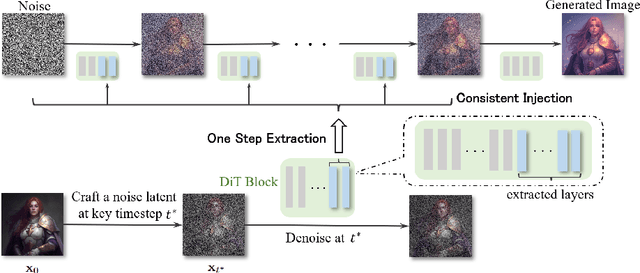
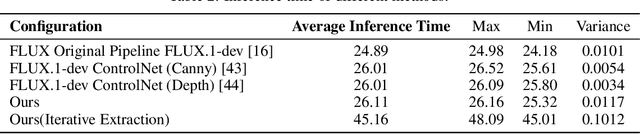

Controlling the spatial and semantic structure of diffusion-generated images remains a challenge. Existing methods like ControlNet rely on handcrafted condition maps and retraining, limiting flexibility and generalization. Inversion-based approaches offer stronger alignment but incur high inference cost due to dual-path denoising. We present FreeControl, a training-free framework for semantic structural control in diffusion models. Unlike prior methods that extract attention across multiple timesteps, FreeControl performs one-step attention extraction from a single, optimally chosen key timestep and reuses it throughout denoising. This enables efficient structural guidance without inversion or retraining. To further improve quality and stability, we introduce Latent-Condition Decoupling (LCD): a principled separation of the key timestep and the noised latent used in attention extraction. LCD provides finer control over attention quality and eliminates structural artifacts. FreeControl also supports compositional control via reference images assembled from multiple sources - enabling intuitive scene layout design and stronger prompt alignment. FreeControl introduces a new paradigm for test-time control, enabling structurally and semantically aligned, visually coherent generation directly from raw images, with the flexibility for intuitive compositional design and compatibility with modern diffusion models at approximately 5 percent additional cost.
OmniStyle: Filtering High Quality Style Transfer Data at Scale
May 20, 2025



In this paper, we introduce OmniStyle-1M, a large-scale paired style transfer dataset comprising over one million content-style-stylized image triplets across 1,000 diverse style categories, each enhanced with textual descriptions and instruction prompts. We show that OmniStyle-1M can not only enable efficient and scalable of style transfer models through supervised training but also facilitate precise control over target stylization. Especially, to ensure the quality of the dataset, we introduce OmniFilter, a comprehensive style transfer quality assessment framework, which filters high-quality triplets based on content preservation, style consistency, and aesthetic appeal. Building upon this foundation, we propose OmniStyle, a framework based on the Diffusion Transformer (DiT) architecture designed for high-quality and efficient style transfer. This framework supports both instruction-guided and image-guided style transfer, generating high resolution outputs with exceptional detail. Extensive qualitative and quantitative evaluations demonstrate OmniStyle's superior performance compared to existing approaches, highlighting its efficiency and versatility. OmniStyle-1M and its accompanying methodologies provide a significant contribution to advancing high-quality style transfer, offering a valuable resource for the research community.
From Zero to Detail: Deconstructing Ultra-High-Definition Image Restoration from Progressive Spectral Perspective
Mar 17, 2025Ultra-high-definition (UHD) image restoration faces significant challenges due to its high resolution, complex content, and intricate details. To cope with these challenges, we analyze the restoration process in depth through a progressive spectral perspective, and deconstruct the complex UHD restoration problem into three progressive stages: zero-frequency enhancement, low-frequency restoration, and high-frequency refinement. Building on this insight, we propose a novel framework, ERR, which comprises three collaborative sub-networks: the zero-frequency enhancer (ZFE), the low-frequency restorer (LFR), and the high-frequency refiner (HFR). Specifically, the ZFE integrates global priors to learn global mapping, while the LFR restores low-frequency information, emphasizing reconstruction of coarse-grained content. Finally, the HFR employs our designed frequency-windowed kolmogorov-arnold networks (FW-KAN) to refine textures and details, producing high-quality image restoration. Our approach significantly outperforms previous UHD methods across various tasks, with extensive ablation studies validating the effectiveness of each component. The code is available at \href{https://github.com/NJU-PCALab/ERR}{here}.
Inversion-Free Video Style Transfer with Trajectory Reset Attention Control and Content-Style Bridging
Mar 10, 2025



Video style transfer aims to alter the style of a video while preserving its content. Previous methods often struggle with content leakage and style misalignment, particularly when using image-driven approaches that aim to transfer precise styles. In this work, we introduce Trajectory Reset Attention Control (TRAC), a novel method that allows for high-quality style transfer while preserving content integrity. TRAC operates by resetting the denoising trajectory and enforcing attention control, thus enhancing content consistency while significantly reducing the computational costs against inversion-based methods. Additionally, a concept termed Style Medium is introduced to bridge the gap between content and style, enabling a more precise and harmonious transfer of stylistic elements. Building upon these concepts, we present a tuning-free framework that offers a stable, flexible, and efficient solution for both image and video style transfer. Experimental results demonstrate that our proposed framework accommodates a wide range of stylized outputs, from precise content preservation to the production of visually striking results with vibrant and expressive styles.
One-Shot Learning for Pose-Guided Person Image Synthesis in the Wild
Sep 15, 2024



Current Pose-Guided Person Image Synthesis (PGPIS) methods depend heavily on large amounts of labeled triplet data to train the generator in a supervised manner. However, they often falter when applied to in-the-wild samples, primarily due to the distribution gap between the training datasets and real-world test samples. While some researchers aim to enhance model generalizability through sophisticated training procedures, advanced architectures, or by creating more diverse datasets, we adopt the test-time fine-tuning paradigm to customize a pre-trained Text2Image (T2I) model. However, naively applying test-time tuning results in inconsistencies in facial identities and appearance attributes. To address this, we introduce a Visual Consistency Module (VCM), which enhances appearance consistency by combining the face, text, and image embedding. Our approach, named OnePoseTrans, requires only a single source image to generate high-quality pose transfer results, offering greater stability than state-of-the-art data-driven methods. For each test case, OnePoseTrans customizes a model in around 48 seconds with an NVIDIA V100 GPU.
Barbie: Text to Barbie-Style 3D Avatars
Aug 17, 2024



Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. The code will be released for research purposes. Our project page is: https://2017211801.github.io/barbie.github.io/.
Anywhere: A Multi-Agent Framework for Reliable and Diverse Foreground-Conditioned Image Inpainting
Apr 29, 2024Recent advancements in image inpainting, particularly through diffusion modeling, have yielded promising outcomes. However, when tested in scenarios involving the completion of images based on the foreground objects, current methods that aim to inpaint an image in an end-to-end manner encounter challenges such as "over-imagination", inconsistency between foreground and background, and limited diversity. In response, we introduce Anywhere, a pioneering multi-agent framework designed to address these issues. Anywhere utilizes a sophisticated pipeline framework comprising various agents such as Visual Language Model (VLM), Large Language Model (LLM), and image generation models. This framework consists of three principal components: the prompt generation module, the image generation module, and the outcome analyzer. The prompt generation module conducts a semantic analysis of the input foreground image, leveraging VLM to predict relevant language descriptions and LLM to recommend optimal language prompts. In the image generation module, we employ a text-guided canny-to-image generation model to create a template image based on the edge map of the foreground image and language prompts, and an image refiner to produce the outcome by blending the input foreground and the template image. The outcome analyzer employs VLM to evaluate image content rationality, aesthetic score, and foreground-background relevance, triggering prompt and image regeneration as needed. Extensive experiments demonstrate that our Anywhere framework excels in foreground-conditioned image inpainting, mitigating "over-imagination", resolving foreground-background discrepancies, and enhancing diversity. It successfully elevates foreground-conditioned image inpainting to produce more reliable and diverse results.