 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
Oct 14, 2021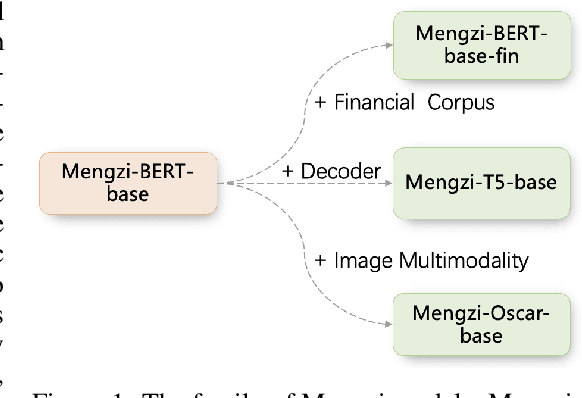

Although pre-trained models (PLMs) have achieved remarkable improvements in a wide range of NLP tasks, they are expensive in terms of time and resources. This calls for the study of training more efficient models with less computation but still ensures impressive performance. Instead of pursuing a larger scale, we are committed to developing lightweight yet more powerful models trained with equal or less computation and friendly to rapid deployment. This technical report releases our pre-trained model called Mengzi, which stands for a family of discriminative, generative, domain-specific, and multimodal pre-trained model variants, capable of a wide range of language and vision tasks. Compared with public Chinese PLMs, Mengzi is simple but more powerful. Our lightweight model has achieved new state-of-the-art results on the widely-used CLUE benchmark with our optimized pre-training and fine-tuning techniques. Without modifying the model architecture, our model can be easily employed as an alternative to existing PLMs. Our sources are available at https://github.com/Langboat/Mengzi.
Jointly Learning to Repair Code and Generate Commit Message
Sep 25, 2021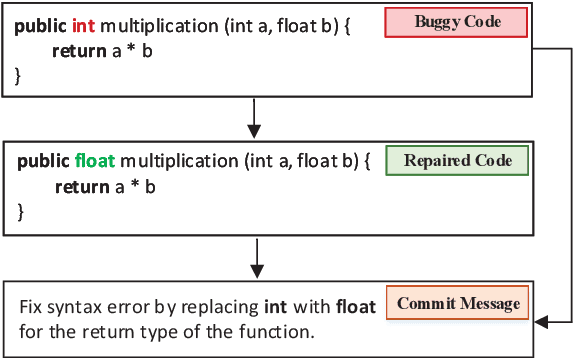
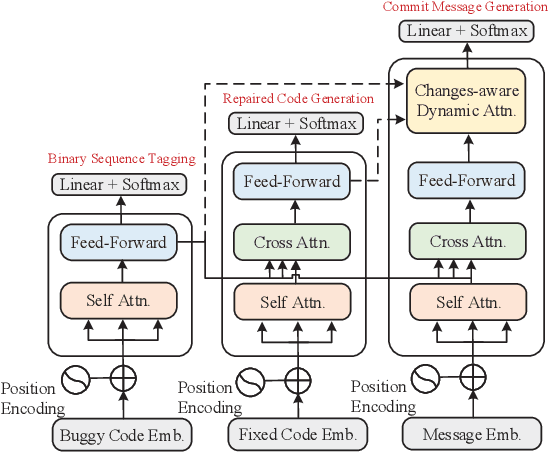
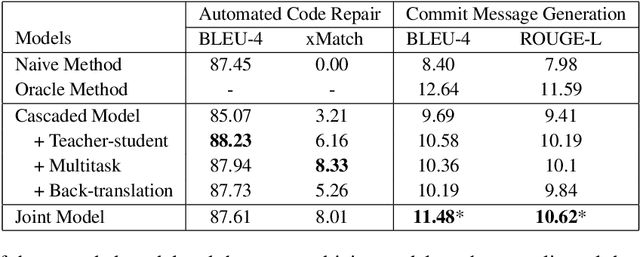
We propose a novel task of jointly repairing program codes and generating commit messages. Code repair and commit message generation are two essential and related tasks for software development. However, existing work usually performs the two tasks independently. We construct a multilingual triple dataset including buggy code, fixed code, and commit messages for this novel task. We provide the cascaded models as baseline, which are enhanced with different training approaches, including the teacher-student method, the multi-task method, and the back-translation method. To deal with the error propagation problem of the cascaded method, the joint model is proposed that can both repair the code and generate the commit message in a unified framework. Experimental results show that the enhanced cascaded model with teacher-student method and multitask-learning method achieves the best score on different metrics of automated code repair, and the joint model behaves better than the cascaded model on commit message generation.
Discovering Representation Sprachbund For Multilingual Pre-Training
Sep 01, 2021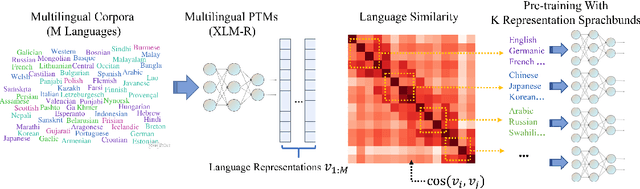

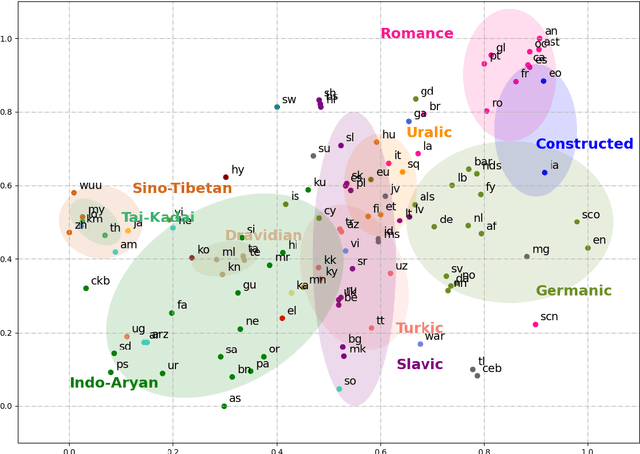

Multilingual pre-trained models have demonstrated their effectiveness in many multilingual NLP tasks and enabled zero-shot or few-shot transfer from high-resource languages to low resource ones. However, due to significant typological differences and contradictions between some languages, such models usually perform poorly on many languages and cross-lingual settings, which shows the difficulty of learning a single model to handle massive diverse languages well at the same time. To alleviate this issue, we present a new multilingual pre-training pipeline. We propose to generate language representation from multilingual pre-trained models and conduct linguistic analysis to show that language representation similarity reflect linguistic similarity from multiple perspectives, including language family, geographical sprachbund, lexicostatistics and syntax. Then we cluster all the target languages into multiple groups and name each group as a representation sprachbund. Thus, languages in the same representation sprachbund are supposed to boost each other in both pre-training and fine-tuning as they share rich linguistic similarity. We pre-train one multilingual model for each representation sprachbund. Experiments are conducted on cross-lingual benchmarks and significant improvements are achieved compared to strong baselines.
From LSAT: The Progress and Challenges of Complex Reasoning
Aug 02, 2021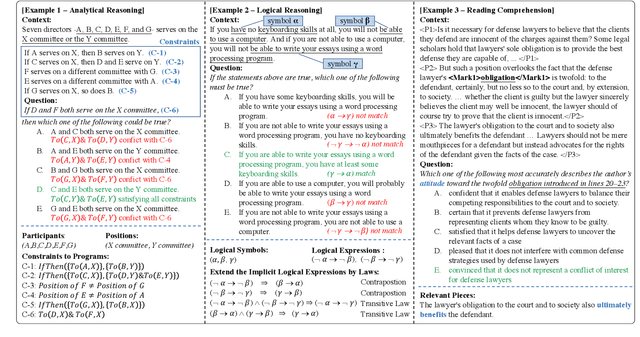
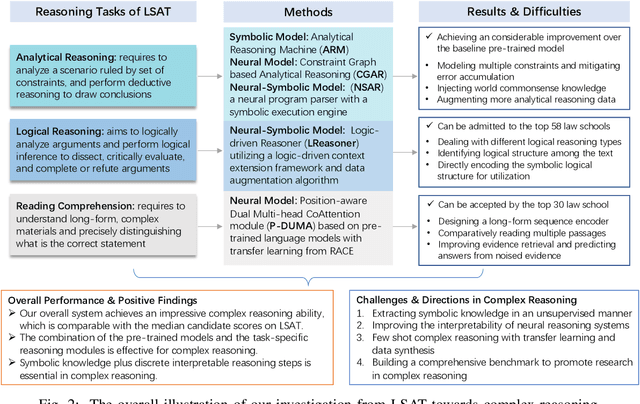
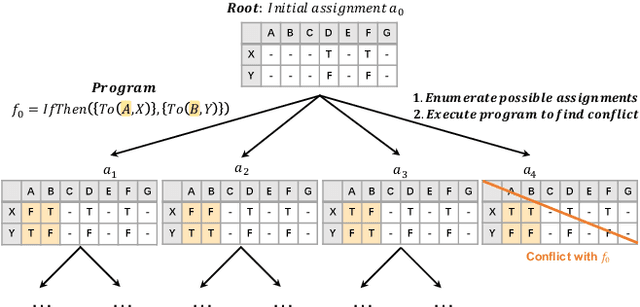
Complex reasoning aims to draw a correct inference based on complex rules. As a hallmark of human intelligence, it involves a degree of explicit reading comprehension, interpretation of logical knowledge and complex rule application. In this paper, we take a step forward in complex reasoning by systematically studying the three challenging and domain-general tasks of the Law School Admission Test (LSAT), including analytical reasoning, logical reasoning and reading comprehension. We propose a hybrid reasoning system to integrate these three tasks and achieve impressive overall performance on the LSAT tests. The experimental results demonstrate that our system endows itself a certain complex reasoning ability, especially the fundamental reading comprehension and challenging logical reasoning capacities. Further analysis also shows the effectiveness of combining the pre-trained models with the task-specific reasoning module, and integrating symbolic knowledge into discrete interpretable reasoning steps in complex reasoning. We further shed a light on the potential future directions, like unsupervised symbolic knowledge extraction, model interpretability, few-shot learning and comprehensive benchmark for complex reasoning.
Learning to Ask Conversational Questions by Optimizing Levenshtein Distance
Jun 30, 2021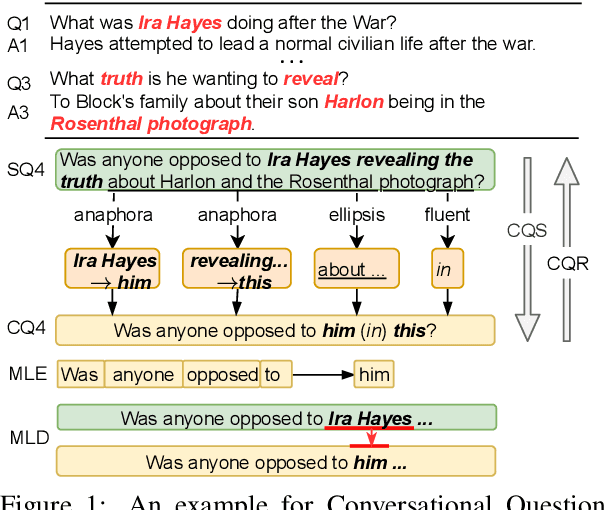
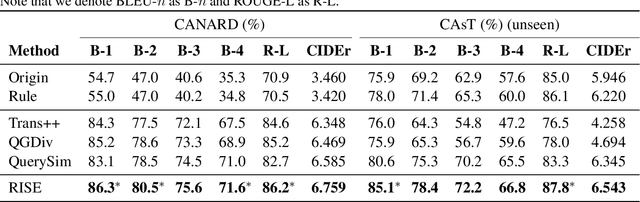
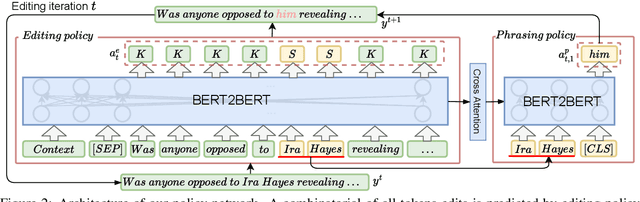
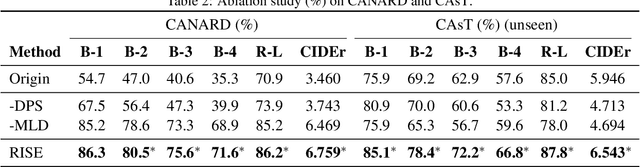
Conversational Question Simplification (CQS) aims to simplify self-contained questions into conversational ones by incorporating some conversational characteristics, e.g., anaphora and ellipsis. Existing maximum likelihood estimation (MLE) based methods often get trapped in easily learned tokens as all tokens are treated equally during training. In this work, we introduce a Reinforcement Iterative Sequence Editing (RISE) framework that optimizes the minimum Levenshtein distance (MLD) through explicit editing actions. RISE is able to pay attention to tokens that are related to conversational characteristics. To train RISE, we devise an Iterative Reinforce Training (IRT) algorithm with a Dynamic Programming based Sampling (DPS) process to improve exploration. Experimental results on two benchmark datasets show that RISE significantly outperforms state-of-the-art methods and generalizes well on unseen data.
MALib: A Parallel Framework for Population-based Multi-agent Reinforcement Learning
Jun 05, 2021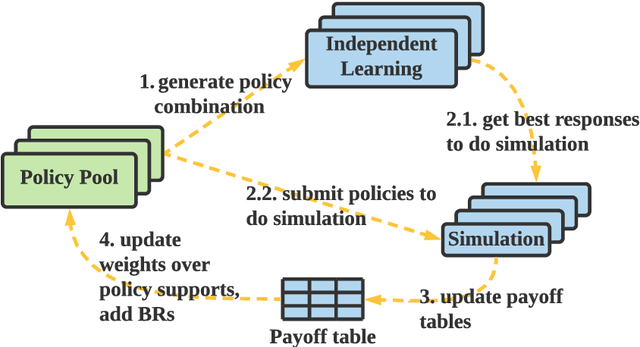

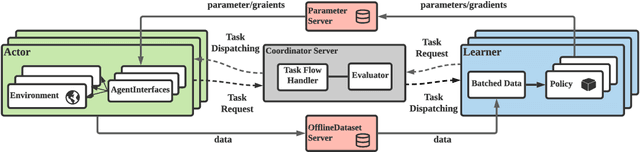

Population-based multi-agent reinforcement learning (PB-MARL) refers to the series of methods nested with reinforcement learning (RL) algorithms, which produces a self-generated sequence of tasks arising from the coupled population dynamics. By leveraging auto-curricula to induce a population of distinct emergent strategies, PB-MARL has achieved impressive success in tackling multi-agent tasks. Despite remarkable prior arts of distributed RL frameworks, PB-MARL poses new challenges for parallelizing the training frameworks due to the additional complexity of multiple nested workloads between sampling, training and evaluation involved with heterogeneous policy interactions. To solve these problems, we present MALib, a scalable and efficient computing framework for PB-MARL. Our framework is comprised of three key components: (1) a centralized task dispatching model, which supports the self-generated tasks and scalable training with heterogeneous policy combinations; (2) a programming architecture named Actor-Evaluator-Learner, which achieves high parallelism for both training and sampling, and meets the evaluation requirement of auto-curriculum learning; (3) a higher-level abstraction of MARL training paradigms, which enables efficient code reuse and flexible deployments on different distributed computing paradigms. Experiments on a series of complex tasks such as multi-agent Atari Games show that MALib achieves throughput higher than 40K FPS on a single machine with $32$ CPU cores; 5x speedup than RLlib and at least 3x speedup than OpenSpiel in multi-agent training tasks. MALib is publicly available at https://github.com/sjtu-marl/malib.
CoSQA: 20,000+ Web Queries for Code Search and Question Answering
May 27, 2021
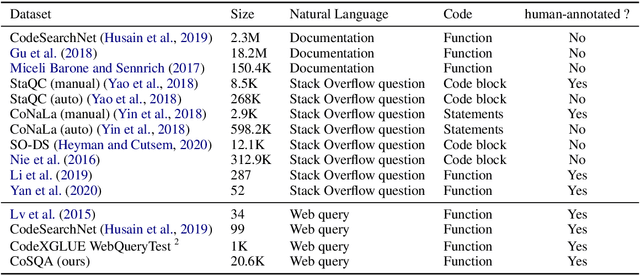

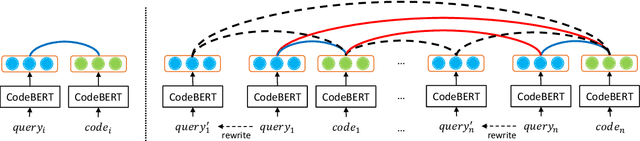
Finding codes given natural language query isb eneficial to the productivity of software developers. Future progress towards better semantic matching between query and code requires richer supervised training resources. To remedy this, we introduce the CoSQA dataset.It includes 20,604 labels for pairs of natural language queries and codes, each annotated by at least 3 human annotators. We further introduce a contrastive learning method dubbed CoCLR to enhance query-code matching, which works as a data augmenter to bring more artificially generated training instances. We show that evaluated on CodeXGLUE with the same CodeBERT model, training on CoSQA improves the accuracy of code question answering by 5.1%, and incorporating CoCLR brings a further improvement of 10.5%.
Model-based Multi-agent Policy Optimization with Adaptive Opponent-wise Rollouts
May 19, 2021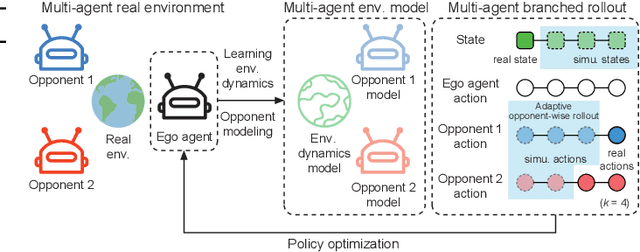
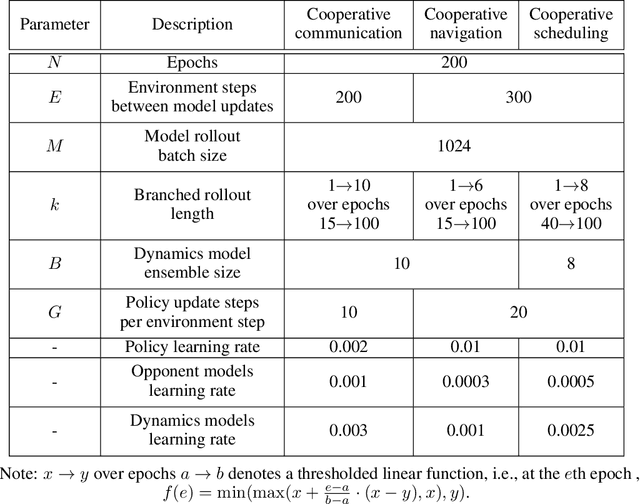
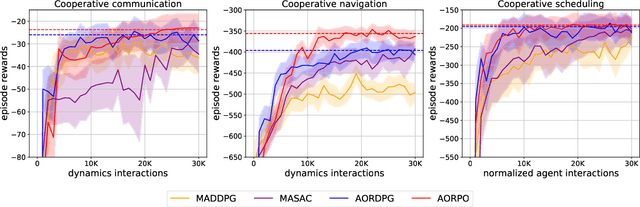
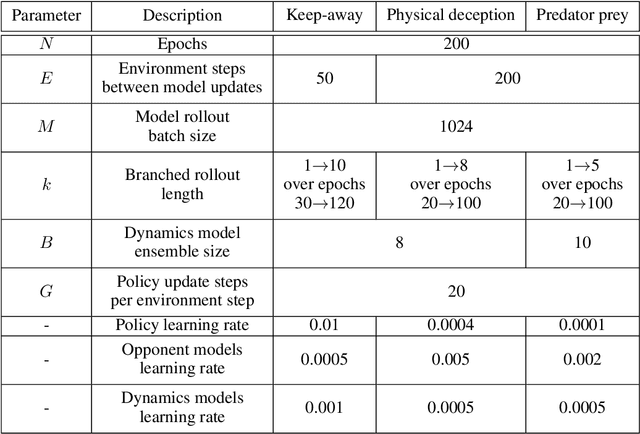
This paper investigates the model-based methods in multi-agent reinforcement learning (MARL). We specify the dynamics sample complexity and the opponent sample complexity in MARL, and conduct a theoretic analysis of return discrepancy upper bound. To reduce the upper bound with the intention of low sample complexity during the whole learning process, we propose a novel decentralized model-based MARL method, named Adaptive Opponent-wise Rollout Policy Optimization (AORPO). In AORPO, each agent builds its multi-agent environment model, consisting of a dynamics model and multiple opponent models, and trains its policy with the adaptive opponent-wise rollout. We further prove the theoretic convergence of AORPO under reasonable assumptions. Empirical experiments on competitive and cooperative tasks demonstrate that AORPO can achieve improved sample efficiency with comparable asymptotic performance over the compared MARL methods.
Leveraging Structural Information to Improve Point Line Visual-Inertial Odometry
May 10, 2021
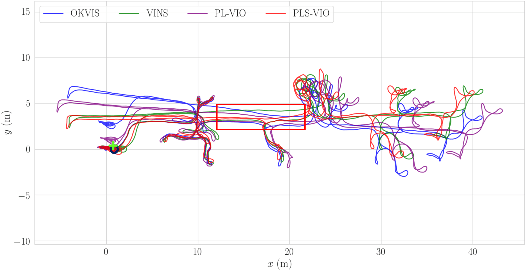
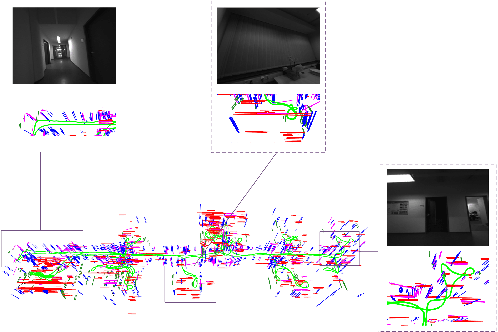

Leveraging line features can help to improve the localization accuracy of point-based monocular Visual-Inertial Odometry (VIO) system, as lines provide additional constraints. Moreover, in an artificial environment, some straight lines are parallel to each other. In this paper, we designed a VIO system based on points and straight lines, which divides straight lines into structural straight lines (that is, straight lines parallel to each other) and non-structural straight lines. In addition, unlike the orthogonal representation using four parameters to represent the 3D straight line, we only used two parameters to minimize the representation of the structural straight line and the non-structural straight line. Furthermore, we designed a straight line matching strategy based on sampling points to improve the efficiency and success rate of straight line matching. The effectiveness of our method is verified on both public datasets of EuRoc and TUM VI benchmark and compared with other state-of-the-art algorithms.
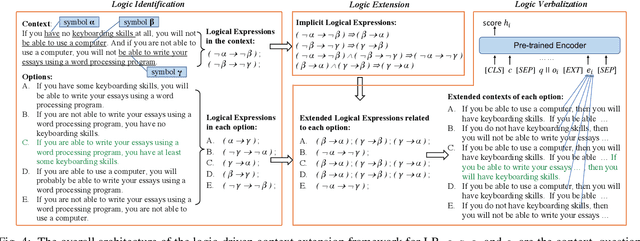
Logic-Driven Context Extension and Data Augmentation for Logical Reasoning of Text
May 08, 2021

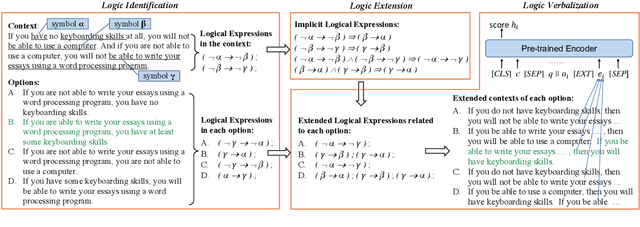
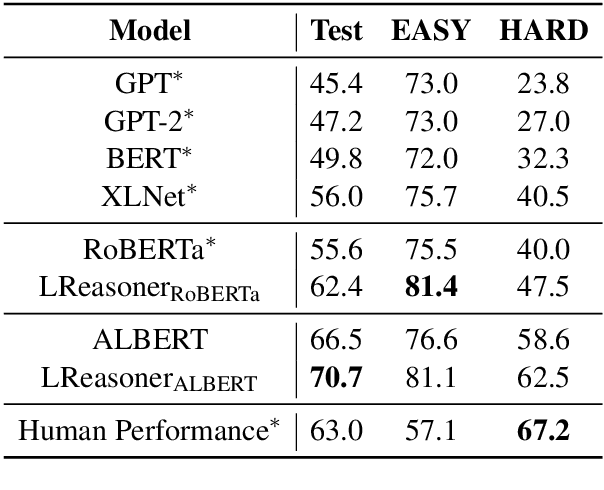
Logical reasoning of text requires understanding critical logical information in the text and performing inference over them. Large-scale pre-trained models for logical reasoning mainly focus on word-level semantics of text while struggling to capture symbolic logic. In this paper, we propose to understand logical symbols and expressions in the text to arrive at the answer. Based on such logical information, we not only put forward a context extension framework but also propose a data augmentation algorithm. The former extends the context to cover implicit logical expressions following logical equivalence laws. The latter augments literally similar but logically different instances to better capture logical information, especially logical negative and conditional relationships. We conduct experiments on ReClor dataset. The results show that our method achieves the state-of-the-art performance, and both logic-driven context extension framework and data augmentation algorithm can help improve the accuracy. And our multi-model ensemble system is the first to surpass human performance on both EASY set and HARD set of ReClor.