 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-MotionControl Technical Report
Mar 03, 2026Character animation aims to generate lifelike videos by transferring motion dynamics from a driving video to a reference image. Recent strides in generative models have paved the way for high-fidelity character animation. In this work, we present Kling-MotionControl, a unified DiT-based framework engineered specifically for robust, precise, and expressive holistic character animation. Leveraging a divide-and-conquer strategy within a cohesive system, the model orchestrates heterogeneous motion representations tailored to the distinct characteristics of body, face, and hands, effectively reconciling large-scale structural stability with fine-grained articulatory expressiveness. To ensure robust cross-identity generalization, we incorporate adaptive identity-agnostic learning, facilitating natural motion retargeting for diverse characters ranging from realistic humans to stylized cartoons. Simultaneously, we guarantee faithful appearance preservation through meticulous identity injection and fusion designs, further supported by a subject library mechanism that leverages comprehensive reference contexts. To ensure practical utility, we implement an advanced acceleration framework utilizing multi-stage distillation, boosting inference speed by over 10x. Kling-MotionControl distinguishes itself through intelligent semantic motion understanding and precise text responsiveness, allowing for flexible control beyond visual inputs. Human preference evaluations demonstrate that Kling-MotionControl delivers superior performance compared to leading commercial and open-source solutions, achieving exceptional fidelity in holistic motion control, open domain generalization, and visual quality and coherence. These results establish Kling-MotionControl as a robust solution for high-quality, controllable, and lifelike character animation.
DiaDem: Advancing Dialogue Descriptions in Audiovisual Video Captioning for Multimodal Large Language Models
Jan 27, 2026Accurate dialogue description in audiovisual video captioning is crucial for downstream understanding and generation tasks. However, existing models generally struggle to produce faithful dialogue descriptions within audiovisual captions. To mitigate this limitation, we propose DiaDem, a powerful audiovisual video captioning model capable of generating captions with more precise dialogue descriptions while maintaining strong overall performance. We first synthesize a high-quality dataset for SFT, then employ a difficulty-partitioned two-stage GRPO strategy to further enhance dialogue descriptions. To enable systematic evaluation of dialogue description capabilities, we introduce DiaDemBench, a comprehensive benchmark designed to evaluate models across diverse dialogue scenarios, emphasizing both speaker attribution accuracy and utterance transcription fidelity in audiovisual captions. Extensive experiments on DiaDemBench reveal even commercial models still exhibit substantial room for improvement in dialogue-aware captioning. Notably, DiaDem not only outperforms the Gemini series in dialogue description accuracy but also achieves competitive performance on general audiovisual captioning benchmarks, demonstrating its overall effectiveness.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Mavors: Multi-granularity Video Representation for Multimodal Large Language Model
Apr 14, 2025



Long-context video understanding in multimodal large language models (MLLMs) faces a critical challenge: balancing computational efficiency with the retention of fine-grained spatio-temporal patterns. Existing approaches (e.g., sparse sampling, dense sampling with low resolution, and token compression) suffer from significant information loss in temporal dynamics, spatial details, or subtle interactions, particularly in videos with complex motion or varying resolutions. To address this, we propose $\mathbf{Mavors}$, a novel framework that introduces $\mathbf{M}$ulti-gr$\mathbf{a}$nularity $\mathbf{v}$ide$\mathbf{o}$ $\mathbf{r}$epre$\mathbf{s}$entation for holistic long-video modeling. Specifically, Mavors directly encodes raw video content into latent representations through two core components: 1) an Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers, and 2) an Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings. Moreover, the framework unifies image and video understanding by treating images as single-frame videos via sub-image decomposition. Experiments across diverse benchmarks demonstrate Mavors' superiority in maintaining both spatial fidelity and temporal continuity, significantly outperforming existing methods in tasks requiring fine-grained spatio-temporal reasoning.
HAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models
Feb 28, 2025

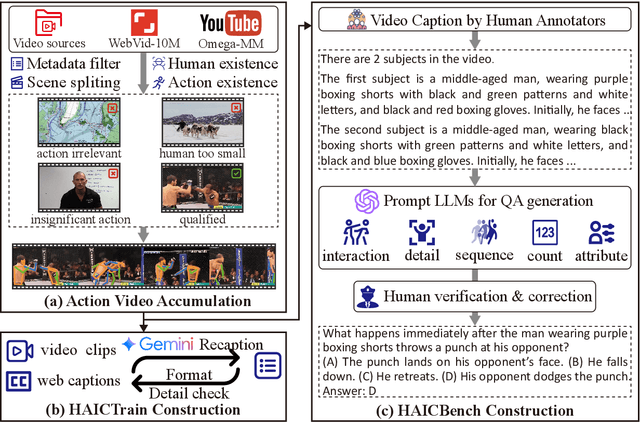
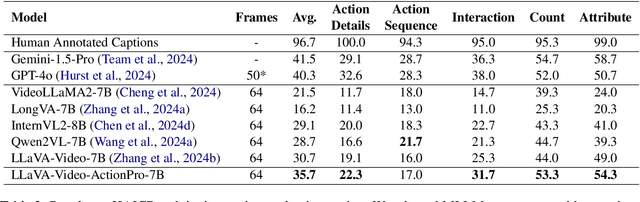
Recent Multi-modal Large Language Models (MLLMs) have made great progress in video understanding. However, their performance on videos involving human actions is still limited by the lack of high-quality data. To address this, we introduce a two-stage data annotation pipeline. First, we design strategies to accumulate videos featuring clear human actions from the Internet. Second, videos are annotated in a standardized caption format that uses human attributes to distinguish individuals and chronologically details their actions and interactions. Through this pipeline, we curate two datasets, namely HAICTrain and HAICBench. \textbf{HAICTrain} comprises 126K video-caption pairs generated by Gemini-Pro and verified for training purposes. Meanwhile, \textbf{HAICBench} includes 500 manually annotated video-caption pairs and 1,400 QA pairs, for a comprehensive evaluation of human action understanding. Experimental results demonstrate that training with HAICTrain not only significantly enhances human understanding abilities across 4 benchmarks, but can also improve text-to-video generation results. Both the HAICTrain and HAICBench are released at https://huggingface.co/datasets/KuaishouHAIC/HAIC.
Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
Oct 14, 2021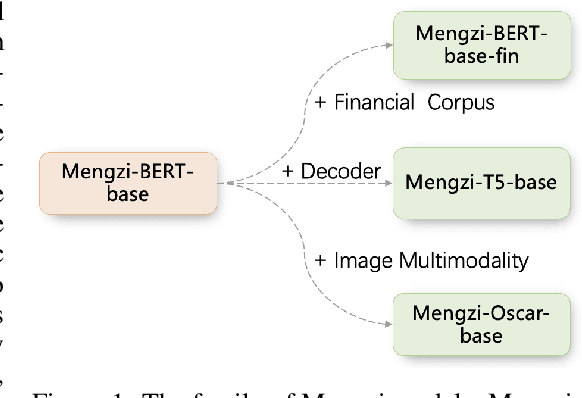
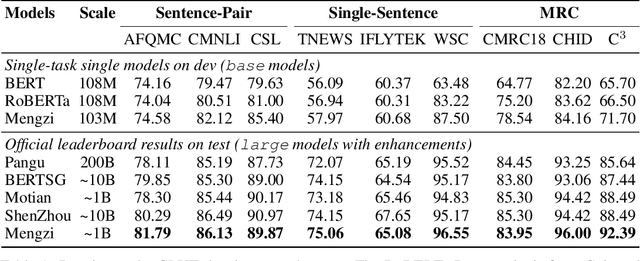

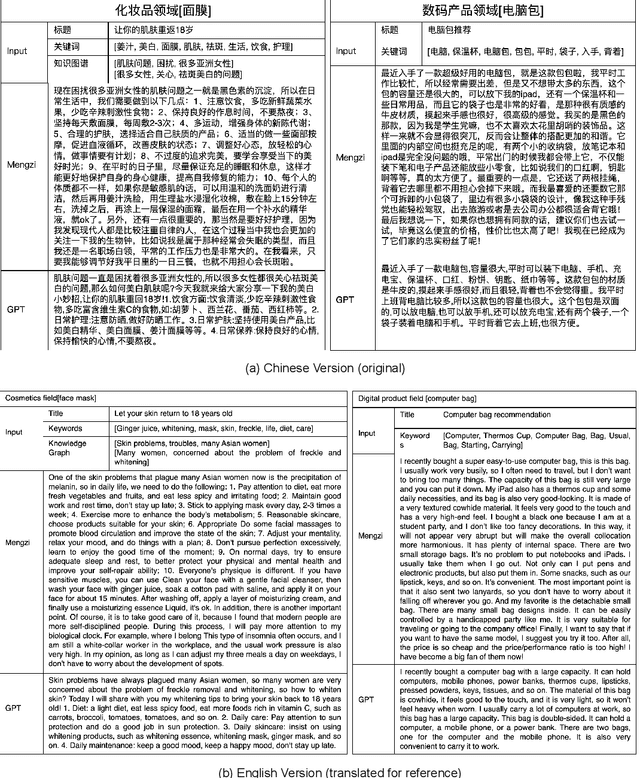
Although pre-trained models (PLMs) have achieved remarkable improvements in a wide range of NLP tasks, they are expensive in terms of time and resources. This calls for the study of training more efficient models with less computation but still ensures impressive performance. Instead of pursuing a larger scale, we are committed to developing lightweight yet more powerful models trained with equal or less computation and friendly to rapid deployment. This technical report releases our pre-trained model called Mengzi, which stands for a family of discriminative, generative, domain-specific, and multimodal pre-trained model variants, capable of a wide range of language and vision tasks. Compared with public Chinese PLMs, Mengzi is simple but more powerful. Our lightweight model has achieved new state-of-the-art results on the widely-used CLUE benchmark with our optimized pre-training and fine-tuning techniques. Without modifying the model architecture, our model can be easily employed as an alternative to existing PLMs. Our sources are available at https://github.com/Langboat/Mengzi.