 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More Fine-Tuning? An Experimental Evaluation of Prompt Tuning in Code Intelligence
Jul 24, 2022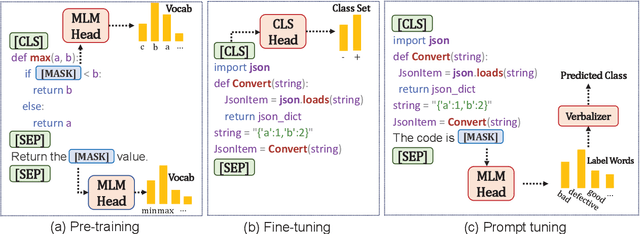
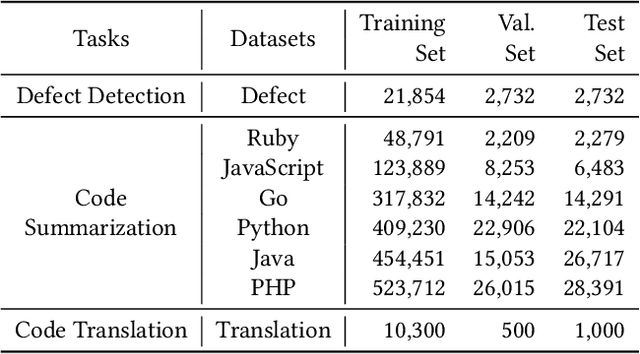
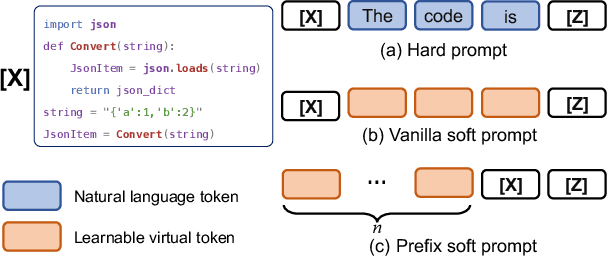
Pre-trained models have been shown effective in many code intelligence tasks. These models are pre-trained on large-scale unlabeled corpus and then fine-tuned in downstream tasks. However, as the inputs to pre-training and downstream tasks are in different forms, it is hard to fully explore the knowledge of pre-trained models. Besides, the performance of fine-tuning strongly relies on the amount of downstream data, while in practice, the scenarios with scarce data are common. Recent studies in the natural language processing (NLP) field show that prompt tuning, a new paradigm for tuning, alleviates the above issues and achieves promising results in various NLP tasks. In prompt tuning, the prompts inserted during tuning provide task-specific knowledge, which is especially beneficial for tasks with relatively scarce data. In this paper, we empirically evaluate the usage and effect of prompt tuning in code intelligence tasks. We conduct prompt tuning on popular pre-trained models CodeBERT and CodeT5 and experiment with three code intelligence tasks including defect prediction, code summarization, and code translation. Our experimental results show that prompt tuning consistently outperforms fine-tuning in all three tasks. In addition, prompt tuning shows great potential in low-resource scenarios, e.g., improving the BLEU scores of fine-tuning by more than 26\% on average for code summarization. Our results suggest that instead of fine-tuning, we could adapt prompt tuning for code intelligence tasks to achieve better performance, especially when lacking task-specific data.
Retrieval-Augmented Multilingual Keyphrase Generation with Retriever-Generator Iterative Training
Jun 01, 2022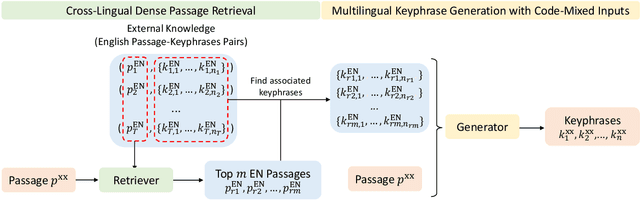
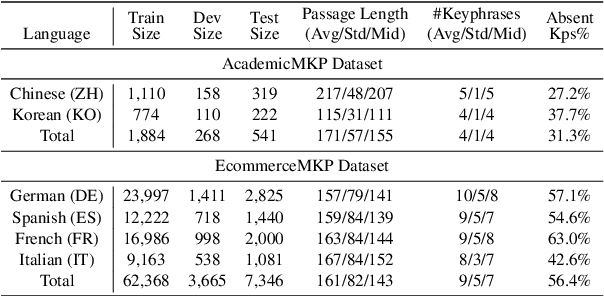
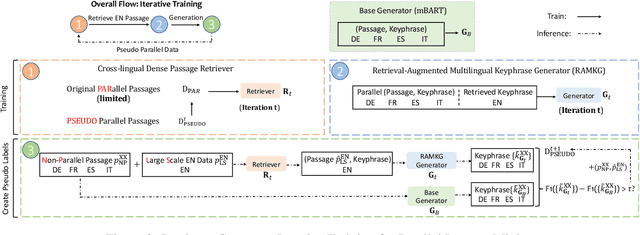
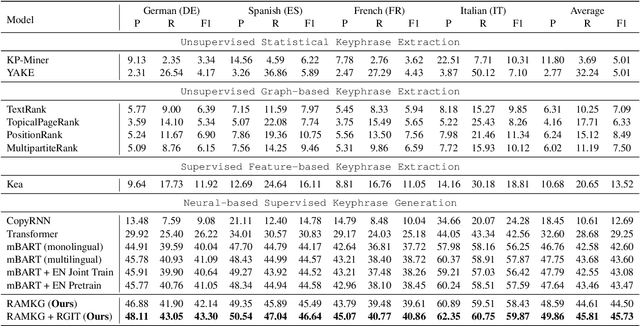
Keyphrase generation is the task of automatically predicting keyphrases given a piece of long text. Despite its recent flourishing, keyphrase generation on non-English languages haven't been vastly investigated. In this paper, we call attention to a new setting named multilingual keyphrase generation and we contribute two new datasets, EcommerceMKP and AcademicMKP, covering six languages. Technically, we propose a retrieval-augmented method for multilingual keyphrase generation to mitigate the data shortage problem in non-English languages. The retrieval-augmented model leverages keyphrase annotations in English datasets to facilitate generating keyphrases in low-resource languages. Given a non-English passage, a cross-lingual dense passage retrieval module finds relevant English passages. Then the associated English keyphrases serve as external knowledge for keyphrase generation in the current language. Moreover, we develop a retriever-generator iterative training algorithm to mine pseudo parallel passage pairs to strengthen the cross-lingual passage retriever. Comprehensive experiments and ablations show that the proposed approach outperforms all baselines.
Understanding and Mitigating the Uncertainty in Zero-Shot Translation
May 20, 2022
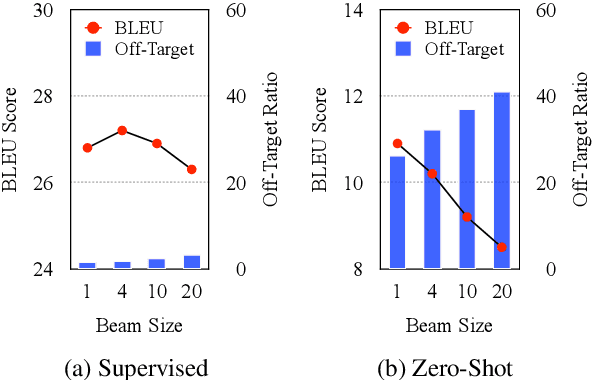
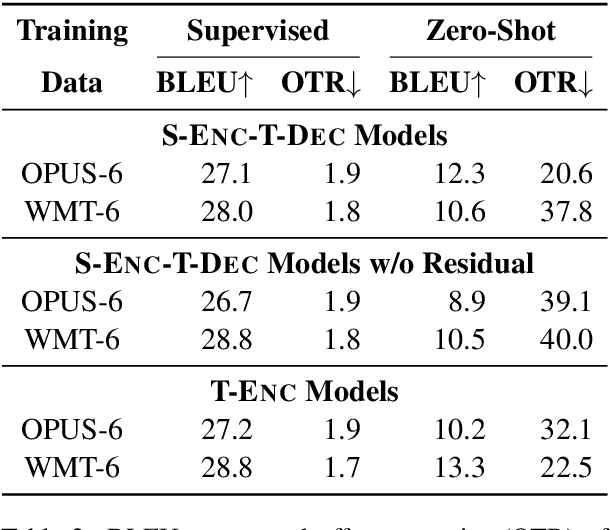
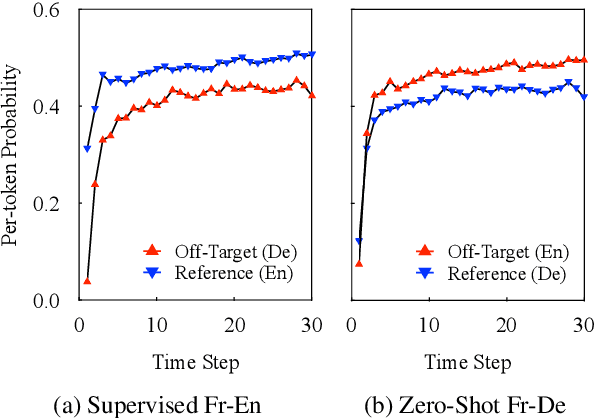
Zero-shot translation is a promising direction for building a comprehensive multilingual neural machine translation (MNMT) system. However, its quality is still not satisfactory due to off-target issues. In this paper, we aim to understand and alleviate the off-target issues from the perspective of uncertainty in zero-shot translation. By carefully examining the translation output and model confidence, we identify two uncertainties that are responsible for the off-target issues, namely, extrinsic data uncertainty and intrinsic model uncertainty. Based on the observations, we propose two light-weight and complementary approaches to denoise the training data for model training, and mask out the vocabulary of the off-target languages in inference. Extensive experiments on both balanced and unbalanced datasets show that our approaches significantly improve the performance of zero-shot translation over strong MNMT baselines. Qualitative analyses provide insights into where our approaches reduce off-target translations
AEON: A Method for Automatic Evaluation of NLP Test Cases
May 13, 2022
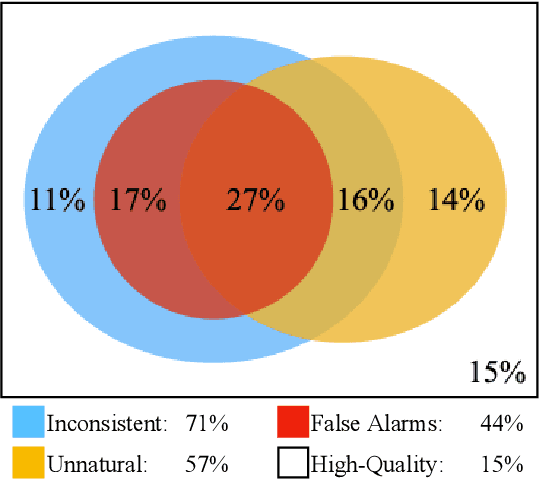
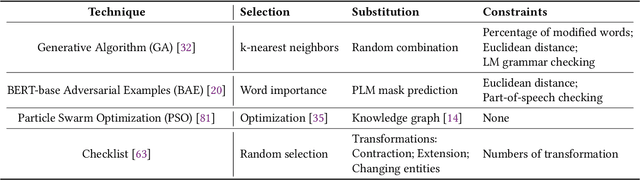
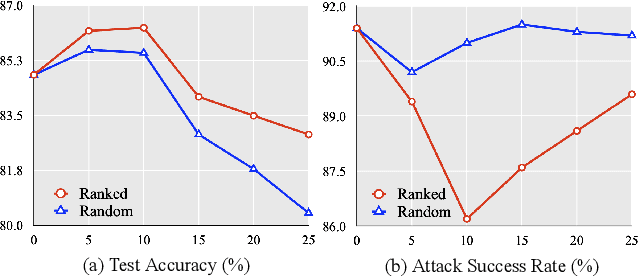
Due to the labor-intensive nature of manual test oracle construction, various automated testing techniques have been proposed to enhance the reliability of Natural Language Processing (NLP) software. In theory, these techniques mutate an existing test case (e.g., a sentence with its label) and assume the generated one preserves an equivalent or similar semantic meaning and thus, the same label. However, in practice, many of the generated test cases fail to preserve similar semantic meaning and are unnatural (e.g., grammar errors), which leads to a high false alarm rate and unnatural test cases. Our evaluation study finds that 44% of the test cases generated by the state-of-the-art (SOTA) approaches are false alarms. These test cases require extensive manual checking effort, and instead of improving NLP software, they can even degrade NLP software when utilized in model training. To address this problem, we propose AEON for Automatic Evaluation Of NLP test cases. For each generated test case, it outputs scores based on semantic similarity and language naturalness. We employ AEON to evaluate test cases generated by four popular testing techniques on five datasets across three typical NLP tasks. The results show that AEON aligns the best with human judgment. In particular, AEON achieves the best average precision in detecting semantic inconsistent test cases, outperforming the best baseline metric by 10%. In addition, AEON also has the highest average precision of finding unnatural test cases, surpassing the baselines by more than 15%. Moreover, model training with test cases prioritized by AEON leads to models that are more accurate and robust, demonstrating AEON's potential in improving NLP software.
Text Revision by On-the-Fly Representation Optimization
Apr 15, 2022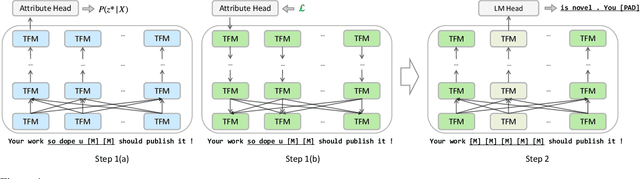
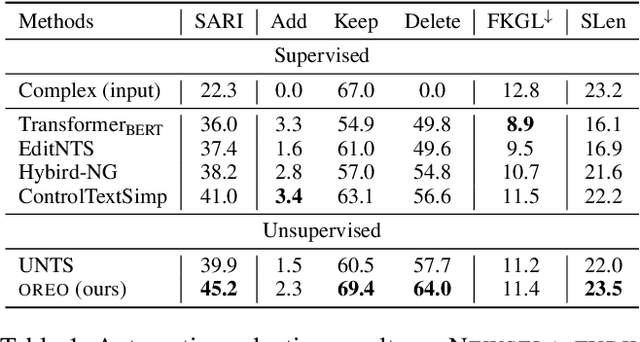
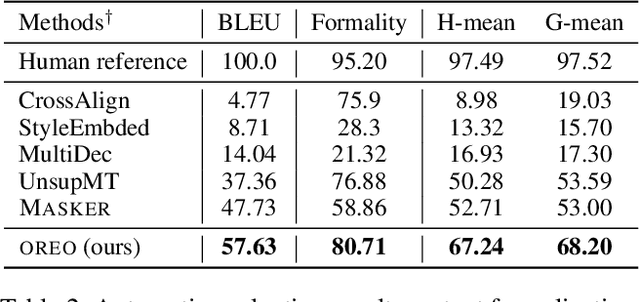
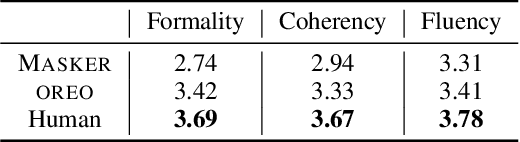
Text revision refers to a family of natural language generation tasks, where the source and target sequences share moderate resemblance in surface form but differentiate in attributes, such as text formality and simplicity. Current state-of-the-art methods formulate these tasks as sequence-to-sequence learning problems, which rely on large-scale parallel training corpus. In this paper, we present an iterative in-place editing approach for text revision, which requires no parallel data. In this approach, we simply fine-tune a pre-trained Transformer with masked language modeling and attribute classification. During inference, the editing at each iteration is realized by two-step span replacement. At the first step, the distributed representation of the text optimizes on the fly towards an attribute function. At the second step, a text span is masked and another new one is proposed conditioned on the optimized representation. The empirical experiments on two typical and important text revision tasks, text formalization and text simplification, show the effectiveness of our approach. It achieves competitive and even better performance than state-of-the-art supervised methods on text simplification, and gains better performance than strong unsupervised methods on text formalization \footnote{Code and model are available at \url{https://github.com/jingjingli01/OREO}}.
Improving Adversarial Transferability via Neuron Attribution-Based Attacks
Mar 31, 2022
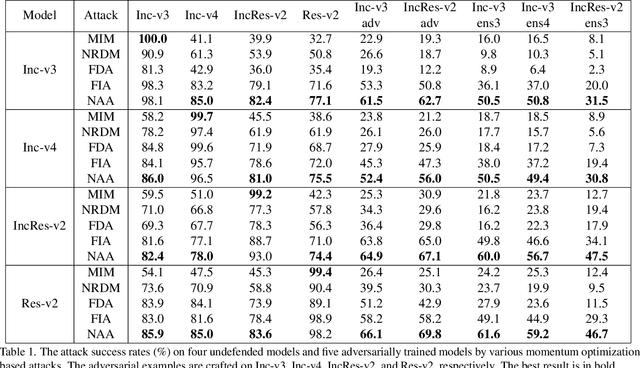
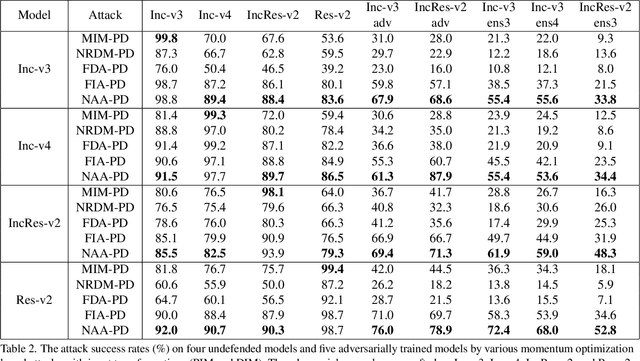
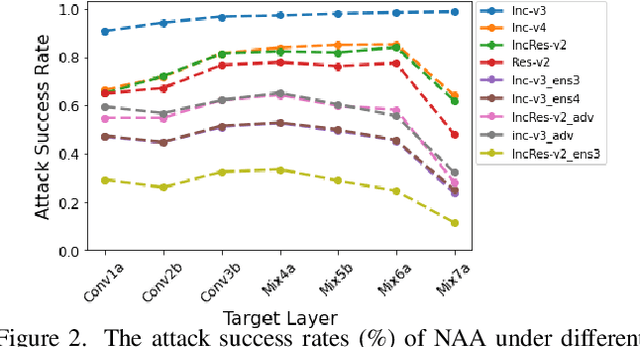
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples. It is thus imperative to devise effective attack algorithms to identify the deficiencies of DNNs beforehand in security-sensitive applications. To efficiently tackle the black-box setting where the target model's particulars are unknown, feature-level transfer-based attacks propose to contaminate the intermediate feature outputs of local models, and then directly employ the crafted adversarial samples to attack the target model. Due to the transferability of features, feature-level attacks have shown promise in synthesizing more transferable adversarial samples. However, existing feature-level attacks generally employ inaccurate neuron importance estimations, which deteriorates their transferability. To overcome such pitfalls, in this paper, we propose the Neuron Attribution-based Attack (NAA), which conducts feature-level attacks with more accurate neuron importance estimations. Specifically, we first completely attribute a model's output to each neuron in a middle layer. We then derive an approximation scheme of neuron attribution to tremendously reduce the computation overhead. Finally, we weight neurons based on their attribution results and launch feature-level attacks. Extensive experiments confirm the superiority of our approach to the state-of-the-art benchmarks.
Accelerating Code Search with Deep Hashing and Code Classification
Mar 31, 2022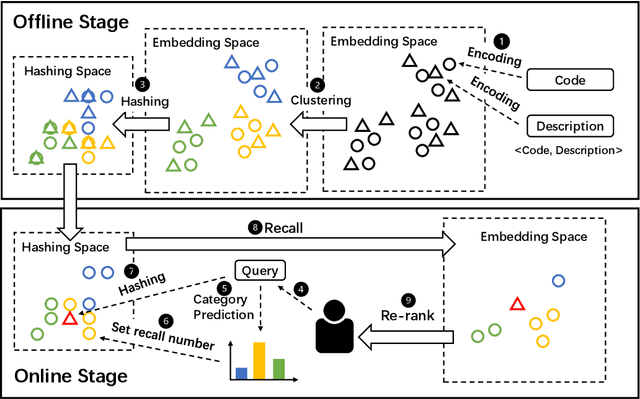
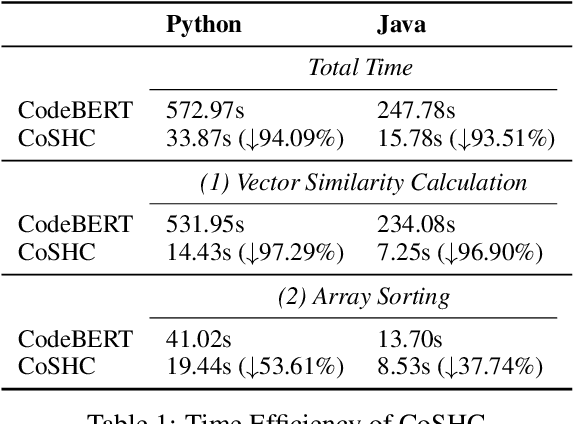
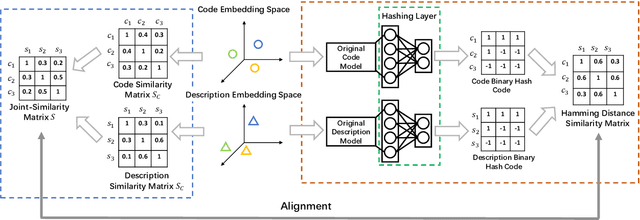
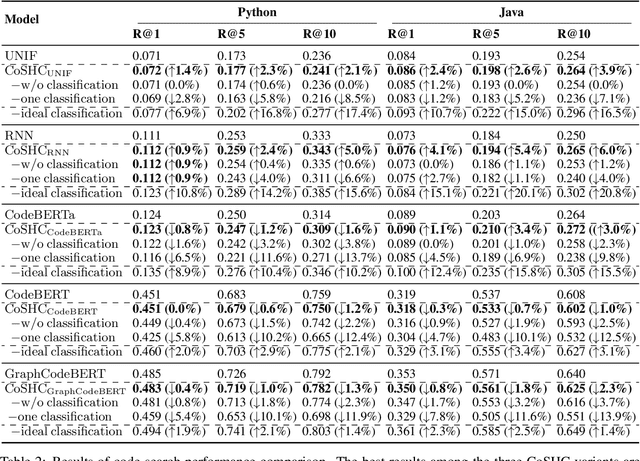
Code search is to search reusable code snippets from source code corpus based on natural languages queries. Deep learning-based methods of code search have shown promising results. However, previous methods focus on retrieval accuracy but lacked attention to the efficiency of the retrieval process. We propose a novel method CoSHC to accelerate code search with deep hashing and code classification, aiming to perform an efficient code search without sacrificing too much accuracy. To evaluate the effectiveness of CoSHC, we apply our method to five code search models. Extensive experimental results indicate that compared with previous code search baselines, CoSHC can save more than 90% of retrieval time meanwhile preserving at least 99% of retrieval accuracy.
FlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows
Feb 14, 2022



Despite recent progress in open-domain dialogue evaluation, how to develop automatic metrics remains an open problem. We explore the potential of dialogue evaluation featuring dialog act information, which was hardly explicitly modeled in previous methods. However, defined at the utterance level in general, dialog act is of coarse granularity, as an utterance can contain multiple segments possessing different functions. Hence, we propose segment act, an extension of dialog act from utterance level to segment level, and crowdsource a large-scale dataset for it. To utilize segment act flows, sequences of segment acts, for evaluation, we develop the first consensus-based dialogue evaluation framework, FlowEval. This framework provides a reference-free approach for dialog evaluation by finding pseudo-references. Extensive experiments against strong baselines on three benchmark datasets demonstrate the effectiveness and other desirable characteristics of our FlowEval, pointing out a potential path for better dialogue evaluation.
Towards Efficient Post-training Quantization of Pre-trained Language Models
Sep 30, 2021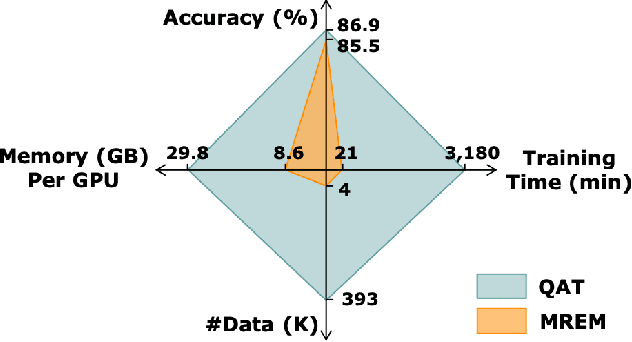
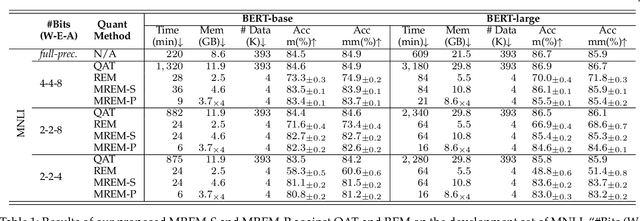
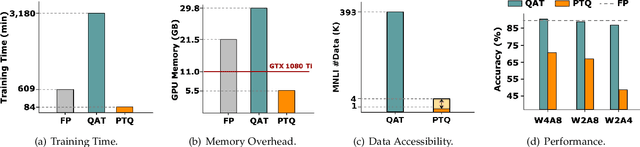
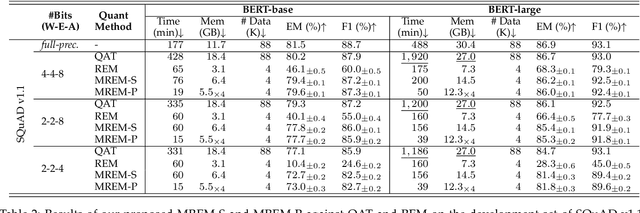
Network quantization has gained increasing attention with the rapid growth of large pre-trained language models~(PLMs). However, most existing quantization methods for PLMs follow quantization-aware training~(QAT) that requires end-to-end training with full access to the entire dataset. Therefore, they suffer from slow training, large memory overhead, and data security issues. In this paper, we study post-training quantization~(PTQ) of PLMs, and propose module-wise quantization error minimization~(MREM), an efficient solution to mitigate these issues. By partitioning the PLM into multiple modules, we minimize the reconstruction error incurred by quantization for each module. In addition, we design a new model parallel training strategy such that each module can be trained locally on separate computing devices without waiting for preceding modules, which brings nearly the theoretical training speed-up (e.g., $4\times$ on $4$ GPUs). Experiments on GLUE and SQuAD benchmarks show that our proposed PTQ solution not only performs close to QAT, but also enjoys significant reductions in training time, memory overhead, and data consumption.
Graph-based Incident Aggregation for Large-Scale Online Service Systems
Aug 27, 2021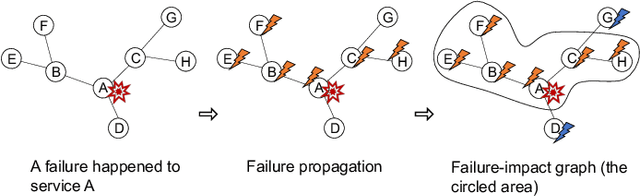
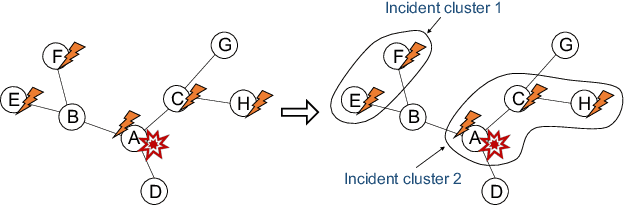
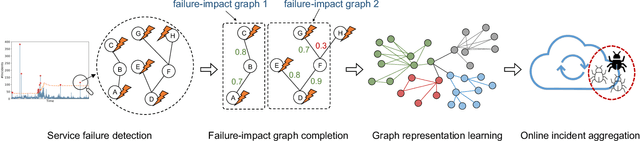
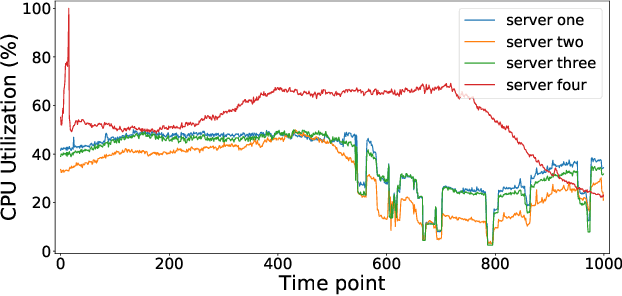
As online service systems continue to grow in terms of complexity and volume, how service incidents are managed will significantly impact company revenue and user trust. Due to the cascading effect, cloud failures often come with an overwhelming number of incidents from dependent services and devices. To pursue efficient incident management, related incidents should be quickly aggregated to narrow down the problem scope. To this end, in this paper, we propose GRLIA, an incident aggregation framework based on graph representation learning over the cascading graph of cloud failures. A representation vector is learned for each unique type of incident in an unsupervised and unified manner, which is able to simultaneously encode the topological and temporal correlations among incidents. Thus, it can be easily employed for online incident aggregation. In particular, to learn the correlations more accurately, we try to recover the complete scope of failures' cascading impact by leveraging fine-grained system monitoring data, i.e., Key Performance Indicators (KPIs). The proposed framework is evaluated with real-world incident data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that GRLIA is effective and outperforms existing methods. Furthermore, our framework has been successfully deployed in industrial practice.