 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMoE: Unifying Attention and FFN with Shared Experts
May 12, 2025



Sparse Mixture of Experts (MoE) architectures have emerged as a promising approach for scaling Transformer models. While initial works primarily incorporated MoE into feed-forward network (FFN) layers, recent studies have explored extending the MoE paradigm to attention layers to enhance model performance. However, existing attention-based MoE layers require specialized implementations and demonstrate suboptimal performance compared to their FFN-based counterparts. In this paper, we aim to unify the MoE designs in attention and FFN layers by introducing a novel reformulation of the attention mechanism, revealing an underlying FFN-like structure within attention modules. Our proposed architecture, UMoE, achieves superior performance through attention-based MoE layers while enabling efficient parameter sharing between FFN and attention components.
Enhancing Multivariate Time Series Forecasting with Mutual Information-driven Cross-Variable and Temporal Modeling
Mar 01, 2024



Recent advancements have underscored the impact of deep learning techniques on multivariate time series forecasting (MTSF). Generally, these techniques are bifurcated into two categories: Channel-independence and Channel-mixing approaches. Although Channel-independence methods typically yield better results, Channel-mixing could theoretically offer improvements by leveraging inter-variable correlations. Nonetheless, we argue that the integration of uncorrelated information in channel-mixing methods could curtail the potential enhancement in MTSF model performance. To substantiate this claim, we introduce the Cross-variable Decorrelation Aware feature Modeling (CDAM) for Channel-mixing approaches, aiming to refine Channel-mixing by minimizing redundant information between channels while enhancing relevant mutual information. Furthermore, we introduce the Temporal correlation Aware Modeling (TAM) to exploit temporal correlations, a step beyond conventional single-step forecasting methods. This strategy maximizes the mutual information between adjacent sub-sequences of both the forecasted and target series. Combining CDAM and TAM, our novel framework significantly surpasses existing models, including those previously considered state-of-the-art, in comprehensive tests.
Enabling Intelligent Interactions between an Agent and an LLM: A Reinforcement Learning Approach
Jun 11, 2023



Large language models (LLMs) encode a vast amount of world knowledge acquired from massive text datasets. Recent studies have demonstrated that LLMs can assist an agent in solving complex sequential decision making tasks in embodied environments by providing high-level instructions. However, interacting with LLMs can be time-consuming, as in many practical scenarios, they require a significant amount of storage space that can only be deployed on remote cloud server nodes. Additionally, using commercial LLMs can be costly since they may charge based on usage frequency. In this paper, we explore how to enable intelligent cost-effective interactions between the agent and an LLM. We propose a reinforcement learning based mediator model that determines when it is necessary to consult LLMs for high-level instructions to accomplish a target task. Experiments on 4 MiniGrid environments that entail planning sub-goals demonstrate that our method can learn to solve target tasks with only a few necessary interactions with an LLM, significantly reducing interaction costs in testing environments, compared with baseline methods. Experimental results also suggest that by learning a mediator model to interact with the LLM, the agent's performance becomes more robust against partial observability of the environment. Our code is available at https://github.com/ZJLAB-AMMI/LLM4RL.
When Federated Learning Meets Pre-trained Language Models' Parameter-Efficient Tuning Methods
Dec 20, 2022



With increasing privacy concerns on data, recent studies have made significant progress using federated learning (FL) on privacy-sensitive natural language processing (NLP) tasks. Much literature suggests fully fine-tuning pre-trained language models (PLMs) in the FL paradigm can mitigate the data heterogeneity problem and close the performance gap with centralized training. However, large PLMs bring the curse of prohibitive communication overhead and local model adaptation costs for the FL system. To this end, we introduce various parameter-efficient tuning (PETuning) methods into federated learning. Specifically, we provide a holistic empirical study of representative PLMs tuning methods in FL. The experimental results cover the analysis of data heterogeneity levels, data scales, and different FL scenarios. Overall communication overhead can be significantly reduced by locally tuning and globally aggregating lightweight model parameters while maintaining acceptable performance in various FL settings. To facilitate the research of PETuning in FL, we also develop a federated tuning framework FedPETuning, which allows practitioners to exploit different PETuning methods under the FL training paradigm conveniently. The source code is available at \url{https://github.com/iezhuozhuo/FedETuning/tree/deltaTuning}.
Once is Enough: A Light-Weight Cross-Attention for Fast Sentence Pair Modeling
Oct 11, 2022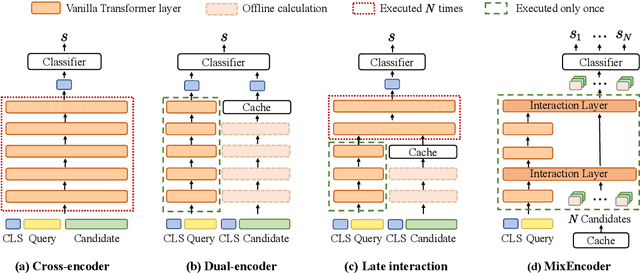

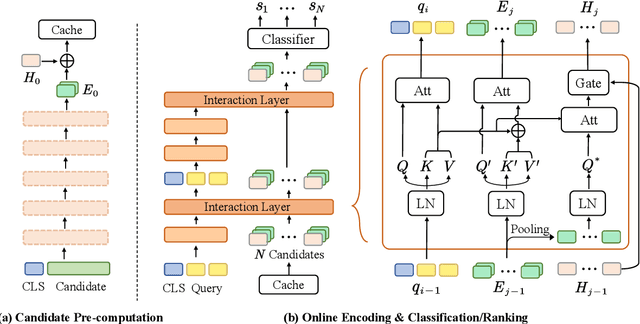
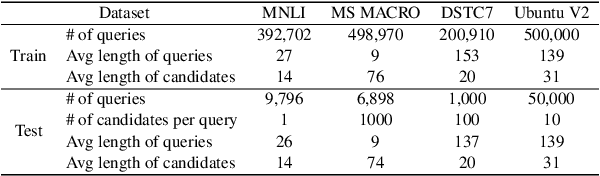
Transformer-based models have achieved great success on sentence pair modeling tasks, such as answer selection and natural language inference (NLI). These models generally perform cross-attention over input pairs, leading to prohibitive computational costs. Recent studies propose dual-encoder and late interaction architectures for faster computation. However, the balance between the expressive of cross-attention and computation speedup still needs better coordinated. To this end, this paper introduces a novel paradigm MixEncoder for efficient sentence pair modeling. MixEncoder involves a light-weight cross-attention mechanism. It conducts query encoding only once while modeling the query-candidate interaction in parallel. Extensive experiments conducted on four tasks demonstrate that our MixEncoder can speed up sentence pairing by over 113x while achieving comparable performance as the more expensive cross-attention models.
No More Fine-Tuning? An Experimental Evaluation of Prompt Tuning in Code Intelligence
Jul 24, 2022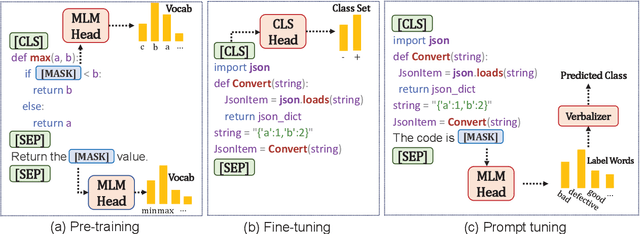
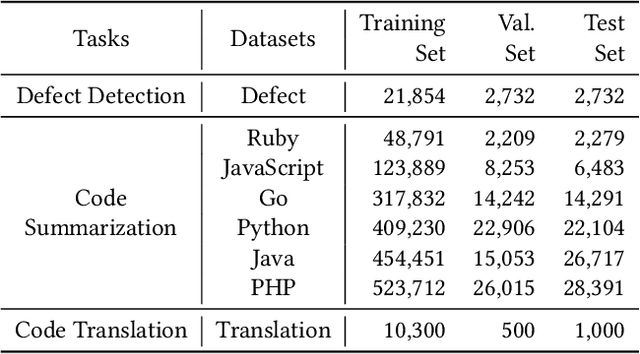
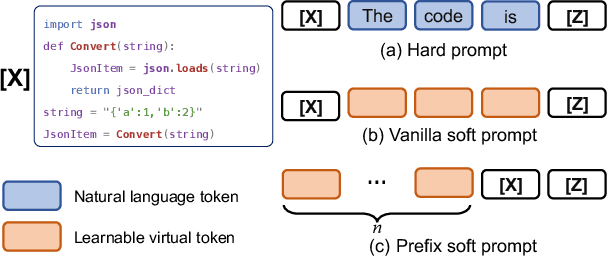
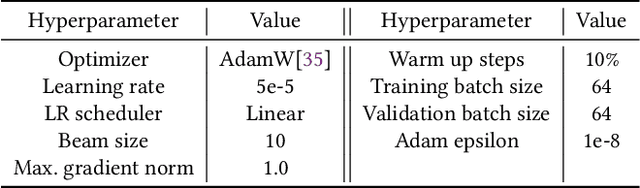
Pre-trained models have been shown effective in many code intelligence tasks. These models are pre-trained on large-scale unlabeled corpus and then fine-tuned in downstream tasks. However, as the inputs to pre-training and downstream tasks are in different forms, it is hard to fully explore the knowledge of pre-trained models. Besides, the performance of fine-tuning strongly relies on the amount of downstream data, while in practice, the scenarios with scarce data are common. Recent studies in the natural language processing (NLP) field show that prompt tuning, a new paradigm for tuning, alleviates the above issues and achieves promising results in various NLP tasks. In prompt tuning, the prompts inserted during tuning provide task-specific knowledge, which is especially beneficial for tasks with relatively scarce data. In this paper, we empirically evaluate the usage and effect of prompt tuning in code intelligence tasks. We conduct prompt tuning on popular pre-trained models CodeBERT and CodeT5 and experiment with three code intelligence tasks including defect prediction, code summarization, and code translation. Our experimental results show that prompt tuning consistently outperforms fine-tuning in all three tasks. In addition, prompt tuning shows great potential in low-resource scenarios, e.g., improving the BLEU scores of fine-tuning by more than 26\% on average for code summarization. Our results suggest that instead of fine-tuning, we could adapt prompt tuning for code intelligence tasks to achieve better performance, especially when lacking task-specific data.