 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest Time Training for Supervised Causal Learning
May 28, 2026Supervised Causal Learning (SCL) has shown promise in causal discovery by framing it as a supervised learning problem. However, it suffers from significant out-of-distribution generalization challenges. We reveal three limitations of previous SCL practices: a significant performance gap between synthetic benchmarks and real-world data, fragility to distribution shifts, and failure in compositional generalization, collectively questioning its real-world applicability. To address this, we propose Test-Time Training for Supervised Causal Learning (TTT-SCL), a novel framework that dynamically generates training sets explicitly aligned with any specific test instance. We demonstrate the correlation between TTT-SCL and score-based methods, and design an efficient module for generating training sets based on the classic scoring function. Experiments on synthetic benchmarks, pseudo-real and real-world datasets demonstrate that TTT-SCL significantly outperforms existing SCL and traditional causal discovery methods.
SheetBrain: A Neuro-Symbolic Agent for Accurate Reasoning over Complex and Large Spreadsheets
Oct 22, 2025Understanding and reasoning over complex spreadsheets remain fundamental challenges for large language models (LLMs), which often struggle with accurately capturing the complex structure of tables and ensuring reasoning correctness. In this work, we propose SheetBrain, a neuro-symbolic dual workflow agent framework designed for accurate reasoning over tabular data, supporting both spreadsheet question answering and manipulation tasks. SheetBrain comprises three core modules: an understanding module, which produces a comprehensive overview of the spreadsheet - including sheet summary and query-based problem insight to guide reasoning; an execution module, which integrates a Python sandbox with preloaded table-processing libraries and an Excel helper toolkit for effective multi-turn reasoning; and a validation module, which verifies the correctness of reasoning and answers, triggering re-execution when necessary. We evaluate SheetBrain on multiple public tabular QA and manipulation benchmarks, and introduce SheetBench, a new benchmark targeting large, multi-table, and structurally complex spreadsheets. Experimental results show that SheetBrain significantly improves accuracy on both existing benchmarks and the more challenging scenarios presented in SheetBench. Our code is publicly available at https://github.com/microsoft/SheetBrain.
Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025



Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
Bingo: Boosting Efficient Reasoning of LLMs via Dynamic and Significance-based Reinforcement Learning
Jun 09, 2025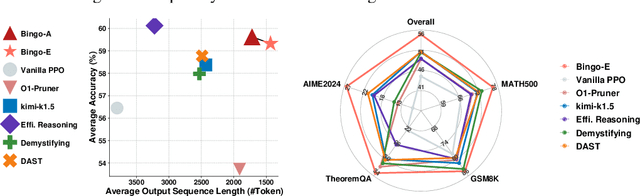
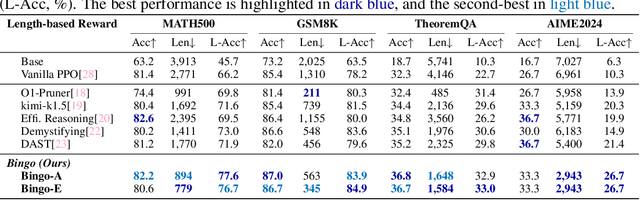
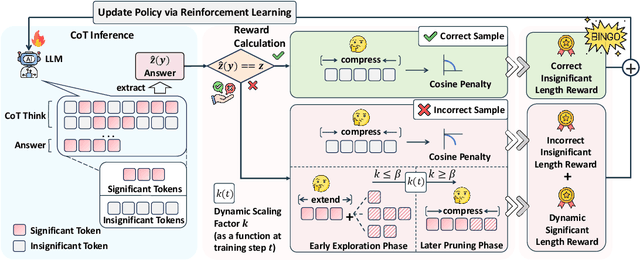
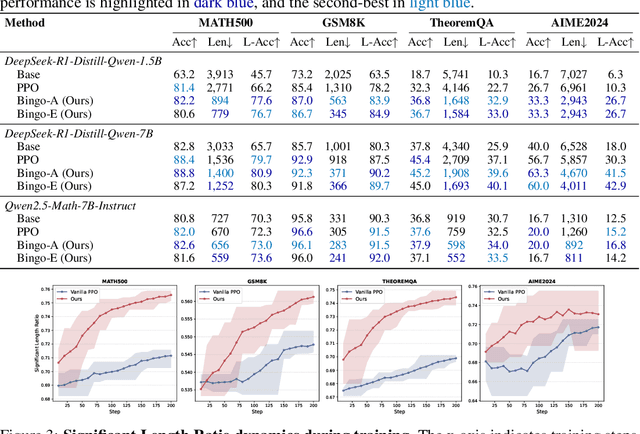
Large language models have demonstrated impressive reasoning capabilities, yet they often suffer from inefficiencies due to unnecessarily verbose or redundant outputs. While many works have explored reinforcement learning (RL) to enhance reasoning abilities, most primarily focus on improving accuracy, with limited attention to reasoning efficiency. Some existing approaches introduce direct length-based rewards to encourage brevity, but this often leads to noticeable drops in accuracy. In this paper, we propose Bingo, an RL framework that advances length-based reward design to boost efficient reasoning. Bingo incorporates two key mechanisms: a significance-aware length reward, which gradually guides the model to reduce only insignificant tokens, and a dynamic length reward, which initially encourages elaborate reasoning for hard questions but decays over time to improve overall efficiency. Experiments across multiple reasoning benchmarks show that Bingo improves both accuracy and efficiency. It outperforms the vanilla reward and several other length-based reward baselines in RL, achieving a favorable trade-off between accuracy and efficiency. These results underscore the potential of training LLMs explicitly for efficient reasoning.
MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025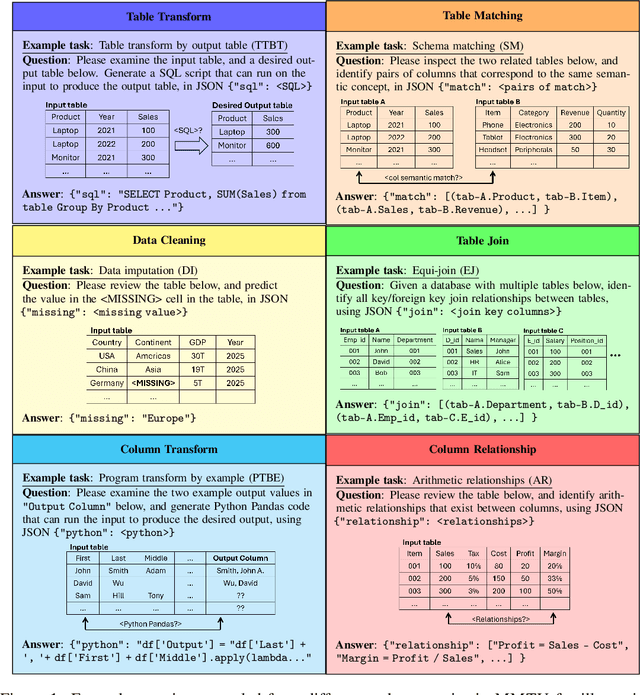


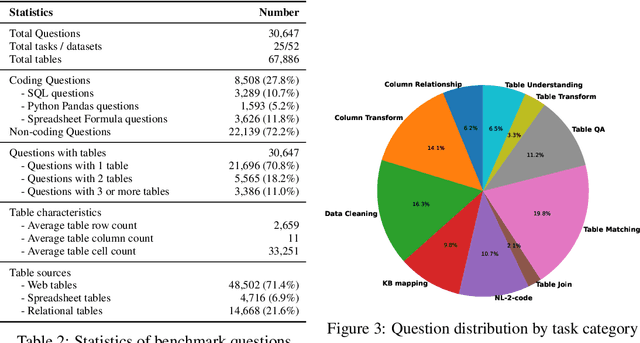
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
May 29, 2025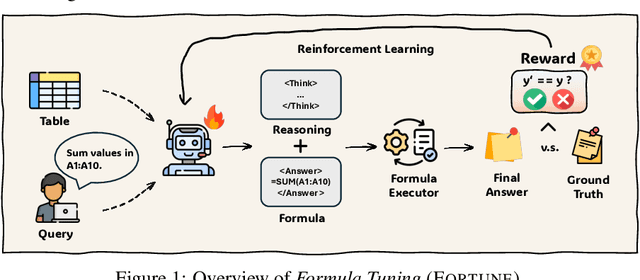



Tables are a fundamental structure for organizing and analyzing data, making effective table understanding a critical capability for intelligent systems. While large language models (LMs) demonstrate strong general reasoning abilities, they continue to struggle with accurate numerical or symbolic reasoning over tabular data, especially in complex scenarios. Spreadsheet formulas provide a powerful and expressive medium for representing executable symbolic operations, encoding rich reasoning patterns that remain largely underutilized. In this paper, we propose Formula Tuning (Fortune), a reinforcement learning (RL) framework that trains LMs to generate executable spreadsheet formulas for question answering over general tabular data. Formula Tuning reduces the reliance on supervised formula annotations by using binary answer correctness as a reward signal, guiding the model to learn formula derivation through reasoning. We provide a theoretical analysis of its advantages and demonstrate its effectiveness through extensive experiments on seven table reasoning benchmarks. Formula Tuning substantially enhances LM performance, particularly on multi-step numerical and symbolic reasoning tasks, enabling a 7B model to outperform O1 on table understanding. This highlights the potential of formula-driven RL to advance symbolic table reasoning in LMs.
TwT: Thinking without Tokens by Habitual Reasoning Distillation with Multi-Teachers' Guidance
Mar 31, 2025



Large Language Models (LLMs) have made significant strides in problem-solving by incorporating reasoning processes. However, this enhanced reasoning capability results in an increased number of output tokens during inference, leading to higher computational costs. To address this challenge, we propose TwT (Thinking without Tokens), a method that reduces inference-time costs through habitual reasoning distillation with multi-teachers' guidance, while maintaining high performance. Our approach introduces a Habitual Reasoning Distillation method, which internalizes explicit reasoning into the model's habitual behavior through a Teacher-Guided compression strategy inspired by human cognition. Additionally, we propose Dual-Criteria Rejection Sampling (DCRS), a technique that generates a high-quality and diverse distillation dataset using multiple teacher models, making our method suitable for unsupervised scenarios. Experimental results demonstrate that TwT effectively reduces inference costs while preserving superior performance, achieving up to a 13.6% improvement in accuracy with fewer output tokens compared to other distillation methods, offering a highly practical solution for efficient LLM deployment.
TablePilot; Recommending Human-Preferred Tabular Data Analysis with Large Language Models
Mar 17, 2025Tabular data analysis is crucial in many scenarios, yet efficiently identifying the most relevant data analysis queries and results for a new table remains a significant challenge. The complexity of tabular data, diverse analytical operations, and the demand for high-quality analysis make the process tedious. To address these challenges, we aim to recommend query-code-result triplets tailored for new tables in tabular data analysis workflows. In this paper, we present TablePilot, a pioneering tabular data analysis framework leveraging large language models to autonomously generate comprehensive and superior analytical results without relying on user profiles or prior interactions. The framework incorporates key designs in analysis preparation and analysis optimization to enhance accuracy. Additionally, we propose Rec-Align, a novel method to further improve recommendation quality and better align with human preferences. Experiments on DART, a dataset specifically designed for comprehensive tabular data analysis recommendation, demonstrate the effectiveness of our framework. Based on GPT-4o, the tuned TablePilot achieves 77.0% top-5 recommendation recall. Human evaluations further highlight its effectiveness in optimizing tabular data analysis workflows.
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
Mar 06, 2025



Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.
Extract Information from Hybrid Long Documents Leveraging LLMs: A Framework and Dataset
Dec 28, 2024



Large Language Models (LLMs) demonstrate exceptional performance in textual understanding and tabular reasoning tasks. However, their ability to comprehend and analyze hybrid text, containing textual and tabular data, remains unexplored. The hybrid text often appears in the form of hybrid long documents (HLDs), which far exceed the token limit of LLMs. Consequently, we apply an Automated Information Extraction framework (AIE) to enable LLMs to process the HLDs and carry out experiments to analyse four important aspects of information extraction from HLDs. Given the findings: 1) The effective way to select and summarize the useful part of a HLD. 2) An easy table serialization way is enough for LLMs to understand tables. 3) The naive AIE has adaptability in many complex scenarios. 4) The useful prompt engineering to enhance LLMs on HLDs. To address the issue of dataset scarcity in HLDs and support future work, we also propose the Financial Reports Numerical Extraction (FINE) dataset. The dataset and code are publicly available in the attachments.