 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM100: An Orchestrated Dataflow Architecture Powering General AI Computing
Apr 20, 2026As deep learning-based AI technologies gain momentum, the demand for general-purpose AI computing architectures continues to grow. While GPGPU-based architectures offer versatility for diverse AI workloads, they often fall short in efficiency and cost-effectiveness. Various Domain-Specific Architectures (DSAs) excel at particular AI tasks but struggle to extend across broader applications or adapt to the rapidly evolving AI landscape. M100 is Li Auto's response: a performant, cost-effective architecture for AI inference in Autonomous Driving (AD), Large Language Models (LLMs), and intelligent human interactions, domains crucial to today's most competitive automobile platforms. M100 employs a dataflow parallel architecture, where compiler-architecture co-design orchestrates not only computation but, more critically, data movement across time and space. Leveraging dataflow computing efficiency, our hardware-software co-design improves system performance while reducing hardware complexity and cost. M100 largely eliminates caching: tensor computations are driven by compiler- and runtime-managed data streams flowing between computing elements and on/off-chip memories, yielding greater efficiency and scalability than cache-based systems. Another key principle was selecting the right operational granularity for scheduling, issuing, and execution across compiler, firmware, and hardware. Recognizing commonalities in AI workloads, we chose the tensor as the fundamental data element. M100 demonstrates general AI computing capability across diverse inference applications, including UniAD (for AD) and LLaMA (for LLMs). Benchmarks show M100 outperforms GPGPU architectures in AD applications with higher utilization, representing a promising direction for future general AI computing.
Learning Translations via Matrix Completion
Jun 19, 2024



Bilingual Lexicon Induction is the task of learning word translations without bilingual parallel corpora. We model this task as a matrix completion problem, and present an effective and extendable framework for completing the matrix. This method harnesses diverse bilingual and monolingual signals, each of which may be incomplete or noisy. Our model achieves state-of-the-art performance for both high and low resource languages.
* This is a late posting of an old paper as Google Scholar somehow misses indexing the ACL anthology version of the paper
Layout2Rendering: AI-aided Greenspace design
Apr 21, 2024



In traditional human living environment landscape design, the establishment of three-dimensional models is an essential step for designers to intuitively present the spatial relationships of design elements, as well as a foundation for conducting landscape analysis on the site. Rapidly and effectively generating beautiful and realistic landscape spaces is a significant challenge faced by designers. Although generative design has been widely applied in related fields, they mostly generate three-dimensional models through the restriction of indicator parameters. However, the elements of landscape design are complex and have unique requirements, making it difficult to generate designs from the perspective of indicator limitations. To address these issues, this study proposes a park space generative design system based on deep learning technology. This system generates design plans based on the topological relationships of landscape elements, then vectorizes the plan element information, and uses Grasshopper to generate three-dimensional models while synchronously fine-tuning parameters, rapidly completing the entire process from basic site conditions to model effect analysis. Experimental results show that: (1) the system, with the aid of AI-assisted technology, can rapidly generate space green space schemes that meet the designer's perspective based on site conditions; (2) this study has vectorized and three-dimensionalized various types of landscape design elements based on semantic information; (3) the analysis and visualization module constructed in this study can perform landscape analysis on the generated three-dimensional models and produce node effect diagrams, allowing users to modify the design in real time based on the effects, thus enhancing the system's interactivity.
l1-norm regularized l1-norm best-fit lines
Mar 06, 2024



In this work, we propose an optimization framework for estimating a sparse robust one-dimensional subspace. Our objective is to minimize both the representation error and the penalty, in terms of the l1-norm criterion. Given that the problem is NP-hard, we introduce a linear relaxation-based approach. Additionally, we present a novel fitting procedure, utilizing simple ratios and sorting techniques. The proposed algorithm demonstrates a worst-case time complexity of $O(n^2 m \log n)$ and, in certain instances, achieves global optimality for the sparse robust subspace, thereby exhibiting polynomial time efficiency. Compared to extant methodologies, the proposed algorithm finds the subspace with the lowest discordance, offering a smoother trade-off between sparsity and fit. Its architecture affords scalability, evidenced by a 16-fold improvement in computational speeds for matrices of 2000x2000 over CPU version. Furthermore, this method is distinguished by several advantages, including its independence from initialization and deterministic and replicable procedures. Furthermore, this method is distinguished by several advantages, including its independence from initialization and deterministic and replicable procedures. The real-world example demonstrates the effectiveness of algorithm in achieving meaningful sparsity, underscoring its precise and useful application across various domains.
A Graph-Matching Approach for Cross-view Registration of Over-view 2 and Street-view based Point Clouds
Feb 14, 2022In this paper, based on the assumption that the object boundaries (e.g., buildings) from the over-view data should coincide with footprints of fa\c{c}ade 3D points generated from street-view photogrammetric images, we aim to address this problem by proposing a fully automated geo-registration method for cross-view data, which utilizes semantically segmented object boundaries as view-invariant features under a global optimization framework through graph-matching: taking the over-view point clouds generated from stereo/multi-stereo satellite images and the street-view point clouds generated from monocular video images as the inputs, the proposed method models segments of buildings as nodes of graphs, both detected from the satellite-based and street-view based point clouds, thus to form the registration as a graph-matching problem to allow non-rigid matches; to enable a robust solution and fully utilize the topological relations between these segments, we propose to address the graph-matching problem on its conjugate graph solved through a belief-propagation algorithm. The matched nodes will be subject to a further optimization to allow precise-registration, followed by a constrained bundle adjustment on the street-view image to keep 2D29 3D consistencies, which yields well-registered street-view images and point clouds to the satellite point clouds.
* 24 pages, 12 figures
Cross-Domain Data Integration for Named Entity Disambiguation in Biomedical Text
Oct 15, 2021Named entity disambiguation (NED), which involves mapping textual mentions to structured entities, is particularly challenging in the medical domain due to the presence of rare entities. Existing approaches are limited by the presence of coarse-grained structural resources in biomedical knowledge bases as well as the use of training datasets that provide low coverage over uncommon resources. In this work, we address these issues by proposing a cross-domain data integration method that transfers structural knowledge from a general text knowledge base to the medical domain. We utilize our integration scheme to augment structural resources and generate a large biomedical NED dataset for pretraining. Our pretrained model with injected structural knowledge achieves state-of-the-art performance on two benchmark medical NED datasets: MedMentions and BC5CDR. Furthermore, we improve disambiguation of rare entities by up to 57 accuracy points.
Graph-based Incident Aggregation for Large-Scale Online Service Systems
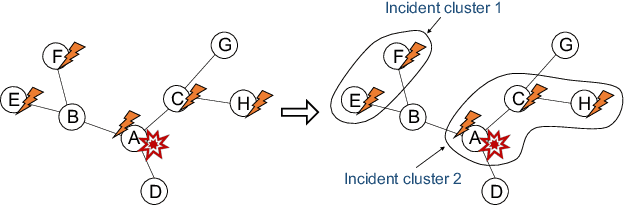
Aug 27, 2021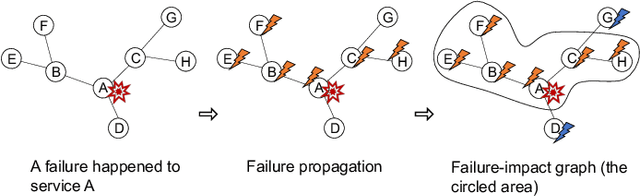
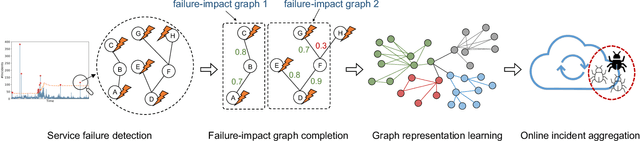
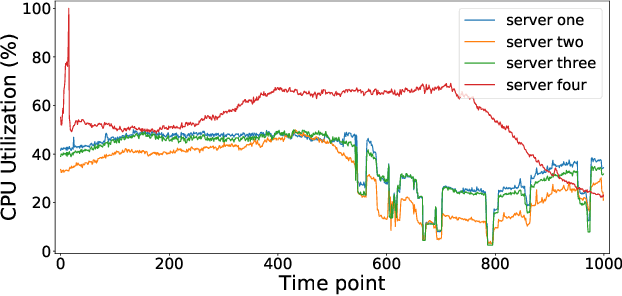
As online service systems continue to grow in terms of complexity and volume, how service incidents are managed will significantly impact company revenue and user trust. Due to the cascading effect, cloud failures often come with an overwhelming number of incidents from dependent services and devices. To pursue efficient incident management, related incidents should be quickly aggregated to narrow down the problem scope. To this end, in this paper, we propose GRLIA, an incident aggregation framework based on graph representation learning over the cascading graph of cloud failures. A representation vector is learned for each unique type of incident in an unsupervised and unified manner, which is able to simultaneously encode the topological and temporal correlations among incidents. Thus, it can be easily employed for online incident aggregation. In particular, to learn the correlations more accurately, we try to recover the complete scope of failures' cascading impact by leveraging fine-grained system monitoring data, i.e., Key Performance Indicators (KPIs). The proposed framework is evaluated with real-world incident data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that GRLIA is effective and outperforms existing methods. Furthermore, our framework has been successfully deployed in industrial practice.
Managing ML Pipelines: Feature Stores and the Coming Wave of Embedding Ecosystems
Aug 11, 2021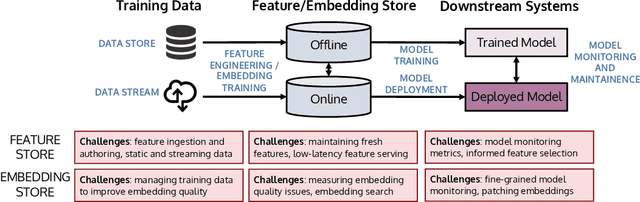
The industrial machine learning pipeline requires iterating on model features, training and deploying models, and monitoring deployed models at scale. Feature stores were developed to manage and standardize the engineer's workflow in this end-to-end pipeline, focusing on traditional tabular feature data. In recent years, however, model development has shifted towards using self-supervised pretrained embeddings as model features. Managing these embeddings and the downstream systems that use them introduces new challenges with respect to managing embedding training data, measuring embedding quality, and monitoring downstream models that use embeddings. These challenges are largely unaddressed in standard feature stores. Our goal in this tutorial is to introduce the feature store system and discuss the challenges and current solutions to managing these new embedding-centric pipelines.
A volumetric change detection framework using UAV oblique photogrammetry - A case study of ultra-high-resolution monitoring of progressive building collapse
Aug 05, 2021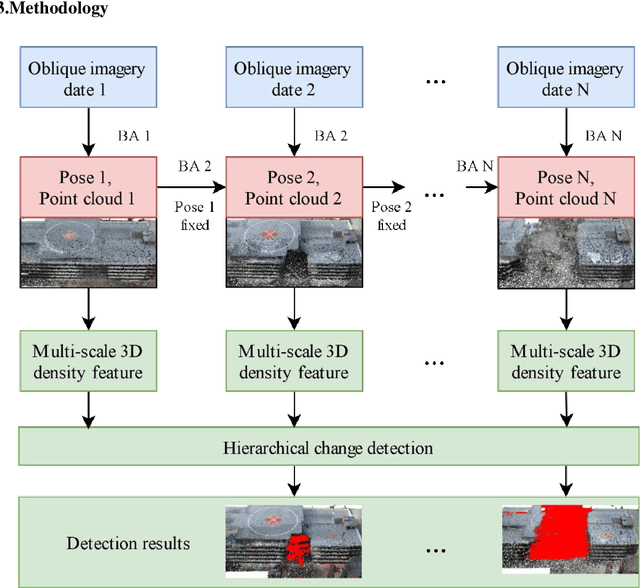

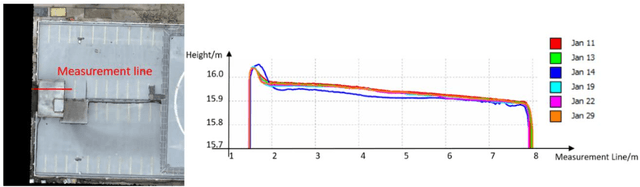
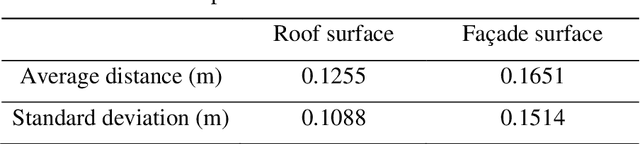
In this paper, we present a case study that performs an unmanned aerial vehicle (UAV) based fine-scale 3D change detection and monitoring of progressive collapse performance of a building during a demolition event. Multi-temporal oblique photogrammetry images are collected with 3D point clouds generated at different stages of the demolition. The geometric accuracy of the generated point clouds has been evaluated against both airborne and terrestrial LiDAR point clouds, achieving an average distance of 12 cm and 16 cm for roof and facade respectively. We propose a hierarchical volumetric change detection framework that unifies multi-temporal UAV images for pose estimation (free of ground control points), reconstruction, and a coarse-to-fine 3D density change analysis. This work has provided a solution capable of addressing change detection on full 3D time-series datasets where dramatic scene content changes are presented progressively. Our change detection results on the building demolition event have been evaluated against the manually marked ground-truth changes and have achieved an F-1 score varying from 0.78 to 0.92, with consistently high precision (0.92 - 0.99). Volumetric changes through the demolition progress are derived from change detection and have shown to favorably reflect the qualitative and quantitative building demolition progression.
A Unified Framework of Bundle Adjustment and Feature Matching for High-Resolution Satellite Images
Jul 01, 2021
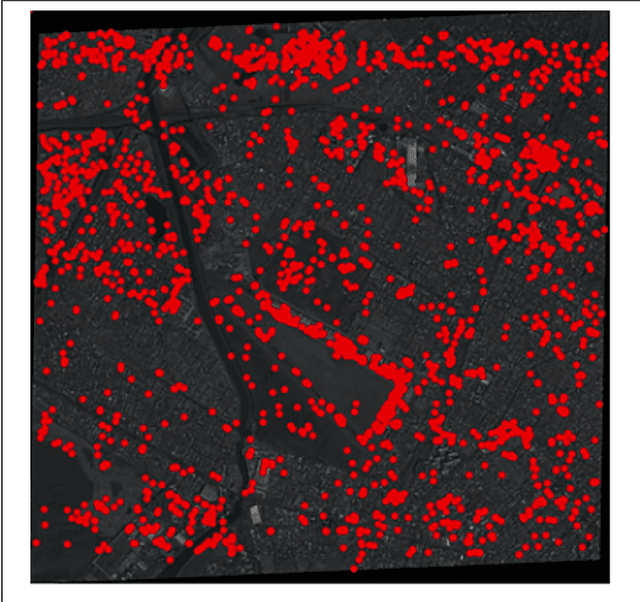
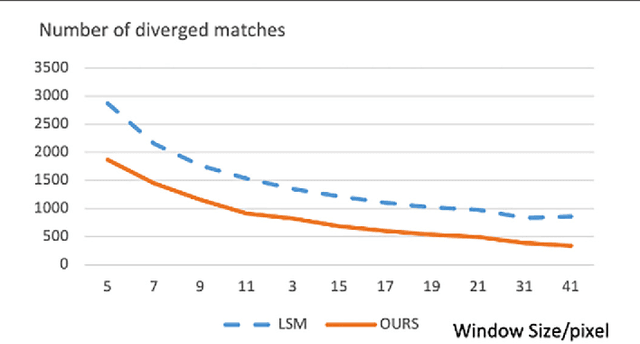
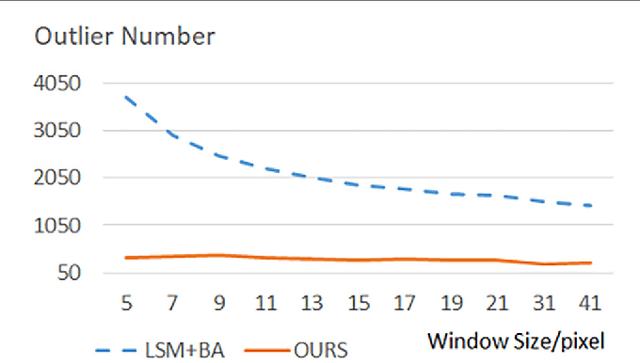
Bundle adjustment (BA) is a technique for refining sensor orientations of satellite images, while adjustment accuracy is correlated with feature matching results. Feature match-ing often contains high uncertainties in weak/repeat textures, while BA results are helpful in reducing these uncertainties. To compute more accurate orientations, this article incorpo-rates BA and feature matching in a unified framework and formulates the union as the optimization of a global energy function so that the solutions of the BA and feature matching are constrained with each other. To avoid a degeneracy in the optimization, we propose a comprised solution by breaking the optimization of the global energy function into two-step suboptimizations and compute the local minimums of each suboptimization in an incremental manner. Experiments on multi-view high-resolution satellite images show that our proposed method outperforms state-of-the-art orientation techniques with or without accurate least-squares matching.