 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostic Reinforcement Learning with Low-Rank MDPs and Rich Observations
Jun 22, 2021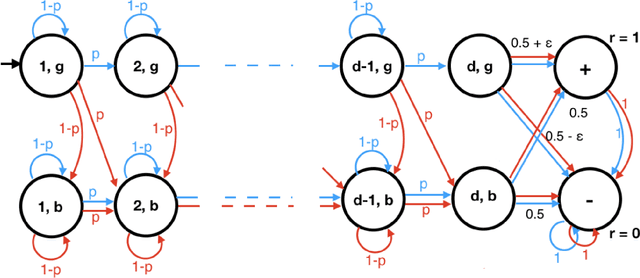
There have been many recent advances on provably efficient Reinforcement Learning (RL) in problems with rich observation spaces. However, all these works share a strong realizability assumption about the optimal value function of the true MDP. Such realizability assumptions are often too strong to hold in practice. In this work, we consider the more realistic setting of agnostic RL with rich observation spaces and a fixed class of policies $\Pi$ that may not contain any near-optimal policy. We provide an algorithm for this setting whose error is bounded in terms of the rank $d$ of the underlying MDP. Specifically, our algorithm enjoys a sample complexity bound of $\widetilde{O}\left((H^{4d} K^{3d} \log |\Pi|)/\epsilon^2\right)$ where $H$ is the length of episodes, $K$ is the number of actions and $\epsilon>0$ is the desired sub-optimality. We also provide a nearly matching lower bound for this agnostic setting that shows that the exponential dependence on rank is unavoidable, without further assumptions.
A Finer Calibration Analysis for Adversarial Robustness
May 06, 2021We present a more general analysis of $H$-calibration for adversarially robust classification. By adopting a finer definition of calibration, we can cover settings beyond the restricted hypothesis sets studied in previous work. In particular, our results hold for most common hypothesis sets used in machine learning. We both fix some previous calibration results (Bao et al., 2020) and generalize others (Awasthi et al., 2021). Moreover, our calibration results, combined with the previous study of consistency by Awasthi et al. (2021), also lead to more general $H$-consistency results covering common hypothesis sets.
Calibration and Consistency of Adversarial Surrogate Losses
May 04, 2021

Adversarial robustness is an increasingly critical property of classifiers in applications. The design of robust algorithms relies on surrogate losses since the optimization of the adversarial loss with most hypothesis sets is NP-hard. But which surrogate losses should be used and when do they benefit from theoretical guarantees? We present an extensive study of this question, including a detailed analysis of the H-calibration and H-consistency of adversarial surrogate losses. We show that, under some general assumptions, convex loss functions, or the supremum-based convex losses often used in applications, are not H-calibrated for important hypothesis sets such as generalized linear models or one-layer neural networks. We then give a characterization of H-calibration and prove that some surrogate losses are indeed H-calibrated for the adversarial loss, with these hypothesis sets. Next, we show that H-calibration is not sufficient to guarantee consistency and prove that, in the absence of any distributional assumption, no continuous surrogate loss is consistent in the adversarial setting. This, in particular, proves that a claim presented in a COLT 2020 publication is inaccurate. (Calibration results there are correct modulo subtle definition differences, but the consistency claim does not hold.) Next, we identify natural conditions under which some surrogate losses that we describe in detail are H-consistent for hypothesis sets such as generalized linear models and one-layer neural networks. We also report a series of empirical results with simulated data, which show that many H-calibrated surrogate losses are indeed not H-consistent, and validate our theoretical assumptions.
Communication-Efficient Agnostic Federated Averaging
Apr 06, 2021
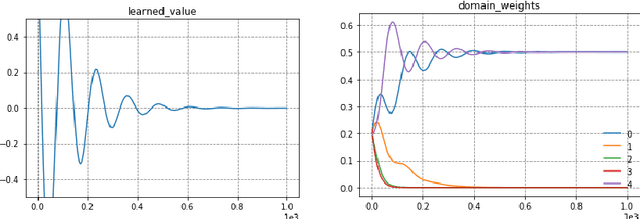
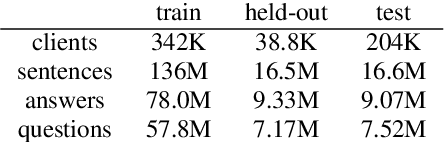
In distributed learning settings such as federated learning, the training algorithm can be potentially biased towards different clients. Mohri et al. (2019) proposed a domain-agnostic learning algorithm, where the model is optimized for any target distribution formed by a mixture of the client distributions in order to overcome this bias. They further proposed an algorithm for the cross-silo federated learning setting, where the number of clients is small. We consider this problem in the cross-device setting, where the number of clients is much larger. We propose a communication-efficient distributed algorithm called Agnostic Federated Averaging (or AgnosticFedAvg) to minimize the domain-agnostic objective proposed in Mohri et al. (2019), which is amenable to other private mechanisms such as secure aggregation. We highlight two types of naturally occurring domains in federated learning and argue that AgnosticFedAvg performs well on both. To demonstrate the practical effectiveness of AgnosticFedAvg, we report positive results for large-scale language modeling tasks in both simulation and live experiments, where the latter involves training language models for Spanish virtual keyboard for millions of user devices.
Learning with User-Level Privacy
Mar 02, 2021We propose and analyze algorithms to solve a range of learning tasks under user-level differential privacy constraints. Rather than guaranteeing only the privacy of individual samples, user-level DP protects a user's entire contribution ($m \ge 1$ samples), providing more stringent but more realistic protection against information leaks. We show that for high-dimensional mean estimation, empirical risk minimization with smooth losses, stochastic convex optimization, and learning hypothesis class with finite metric entropy, the privacy cost decreases as $O(1/\sqrt{m})$ as users provide more samples. In contrast, when increasing the number of users $n$, the privacy cost decreases at a faster $O(1/n)$ rate. We complement these results with lower bounds showing the worst-case optimality of our algorithm for mean estimation and stochastic convex optimization. Our algorithms rely on novel techniques for private mean estimation in arbitrary dimension with error scaling as the concentration radius $\tau$ of the distribution rather than the entire range. Under uniform convergence, we derive an algorithm that privately answers a sequence of $K$ adaptively chosen queries with privacy cost proportional to $\tau$, and apply it to solve the learning tasks we consider.
Multiple-Source Adaptation with Domain Classifiers
Aug 25, 2020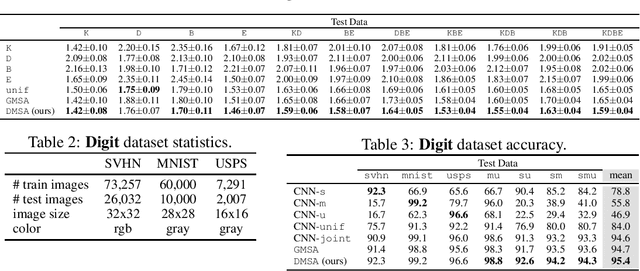
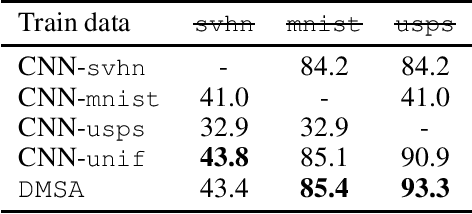
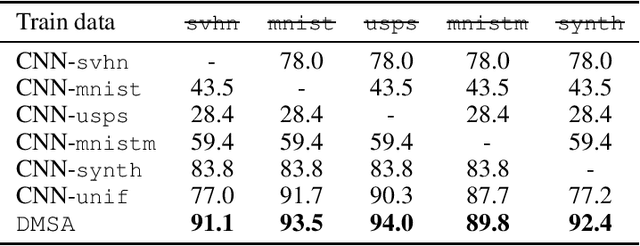
We consider the multiple-source adaptation (MSA) problem and improve a previously proposed MSA solution, where accurate density estimation per domain is required to obtain favorable learning guarantees. In this work, we replace the difficult task of density estimation per domain with a much easier task of domain classification, and show that the two solutions are equivalent given the true densities and domain classifier, yet the newer approach benefits from more favorable guarantees when densities and domain classifier are estimated from finite samples. Our experiments with real-world applications demonstrate that the new discriminative MSA solution outperforms the previous solution with density estimation, as well as other domain adaptation baselines.
Beyond Individual and Group Fairness
Aug 21, 2020



We present a new data-driven model of fairness that, unlike existing static definitions of individual or group fairness is guided by the unfairness complaints received by the system. Our model supports multiple fairness criteria and takes into account their potential incompatibilities. We consider both a stochastic and an adversarial setting of our model. In the stochastic setting, we show that our framework can be naturally cast as a Markov Decision Process with stochastic losses, for which we give efficient vanishing regret algorithmic solutions. In the adversarial setting, we design efficient algorithms with competitive ratio guarantees. We also report the results of experiments with our algorithms and the stochastic framework on artificial datasets, to demonstrate their effectiveness empirically.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020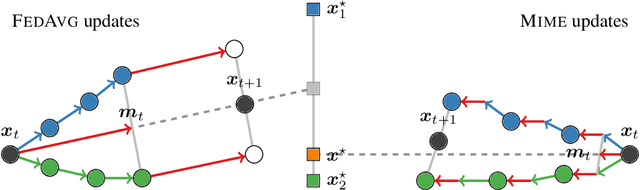

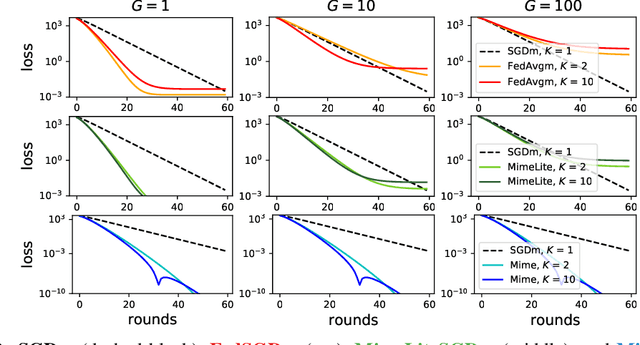

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
On the Rademacher Complexity of Linear Hypothesis Sets
Jul 21, 2020

Linear predictors form a rich class of hypotheses used in a variety of learning algorithms. We present a tight analysis of the empirical Rademacher complexity of the family of linear hypothesis classes with weight vectors bounded in $\ell_p$-norm for any $p \geq 1$. This provides a tight analysis of generalization using these hypothesis sets and helps derive sharp data-dependent learning guarantees. We give both upper and lower bounds on the Rademacher complexity of these families and show that our bounds improve upon or match existing bounds, which are known only for $1 \leq p \leq 2$.
A Theory of Multiple-Source Adaptation with Limited Target Labeled Data
Jul 19, 2020
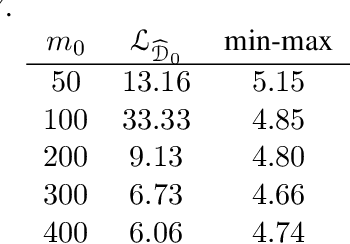
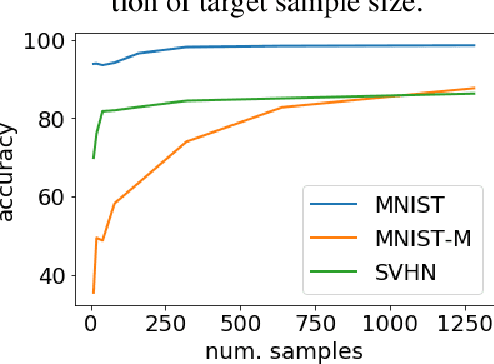
We study multiple-source domain adaptation, when the learner has access to abundant labeled data from multiple-source domains and limited labeled data from the target domain. We analyze existing algorithms for this problem, and propose a novel algorithm based on model selection. Our algorithms are efficient, and experiments on real data-sets empirically demonstrate their benefits.