 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Reward Adaptation for Robust Preference Modeling
May 28, 2026Reinforcement Learning from Human Feedback (RLHF) typically relies on static reward models to align Large Language Models with human preferences. However, human values are inherently diverse and heterogeneous, and a single reward model often lacks the robustness required to generalize to unseen preference domains. While existing multi-reward frameworks attempt to address this, they are often restricted to a fixed set of known domains and fail to adapt to unseen human distributions without costly retraining. In this work, we propose In-Context Reward Adaptation, a transformer-based framework designed to model diverse and unseen human preferences on the fly. By leveraging the in-context learning capabilities of transformers, our approach adaptively infers the underlying reward structure from a small set of preference demonstrations. We demonstrate that while a standard transformer architecture is insufficient for this task by characterizing an asymptotic bias to the ground-truth, incorporating human response time as an auxiliary input signal enables the model to successfully adapt to preferences from previously unseen domains. Our findings show that this approach provides a more robust foundation for preference modeling, allowing for the representation of heterogeneous rewards and preference distribution shift, and offering a scalable path toward more flexible human-AI alignment.
Modeling of Human Body-coupled Electric Field Interference in Unshielded Ultra-Low Field MRI
Feb 25, 2026Portable ultra-low field MRI (ULF-MRI) systems operated in unshielded environments are susceptible to electromagnetic interference (EMI). Subject presence in the imaging region will lead to substantial noise increases, yet the dominant coupling mechanism remains insufficiently characterized. We develop a lumped-parameter circuit model of the coupled environment-body-receiver system. The model indicates that ambient time-varying electric fields induce a body common-mode potential, which is converted into differential-mode noise through capacitive imbalance between the head and the receive-coil terminals, yielding strong dependence on subject position and geometry. Circuit analysis, simulations, and controlled experiments support the model, with predicted imbalance consistent with measured noise variations. Guided by this mechanism, we implement a capacitive low-impedance bypass to clamp the body potential, achieving an approximately 3.5-fold SNR improvement on a 50 mT prototype. The proposed model offers a compact circuit-based tool for analyzing and mitigating human body-coupled electric-field interference in portable ULF-MRI.
Memorization Dynamics in Knowledge Distillation for Language Models
Jan 21, 2026Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from large language models to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three large language model (LLM) families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
ToolGrad: Efficient Tool-use Dataset Generation with Textual "Gradients"
Aug 06, 2025Prior work synthesizes tool-use LLM datasets by first generating a user query, followed by complex tool-use annotations like DFS. This leads to inevitable annotation failures and low efficiency in data generation. We introduce ToolGrad, an agentic framework that inverts this paradigm. ToolGrad first constructs valid tool-use chains through an iterative process guided by textual "gradients", and then synthesizes corresponding user queries. This "answer-first" approach led to ToolGrad-5k, a dataset generated with more complex tool use, lower cost, and 100% pass rate. Experiments show that models trained on ToolGrad-5k outperform those on expensive baseline datasets and proprietary LLMs, even on OOD benchmarks.
Synthesizing and Adapting Error Correction Data for Mobile Large Language Model Applications
May 24, 2025Error correction is an important capability when applying large language models (LLMs) to facilitate user typing on mobile devices. In this paper, we use LLMs to synthesize a high-quality dataset of error correction pairs to evaluate and improve LLMs for mobile applications. We first prompt LLMs with error correction domain knowledge to build a scalable and reliable addition to the existing data synthesis pipeline. We then adapt the synthetic data distribution to match the mobile application domain by reweighting the samples. The reweighting model is learnt by predicting (a handful of) live A/B test metrics when deploying LLMs in production, given the LLM performance on offline evaluation data and scores from a small privacy-preserving on-device language model. Finally, we present best practices for mixing our synthetic data with other data sources to improve model performance on error correction in both offline evaluation and production live A/B testing.
An Optimization Framework for Differentially Private Sparse Fine-Tuning
Mar 17, 2025
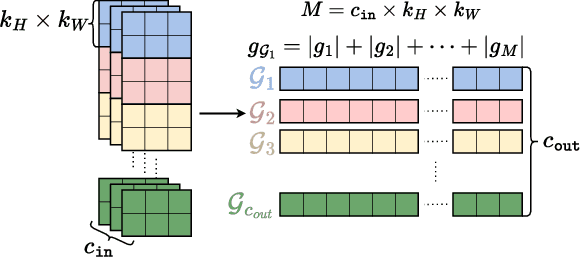
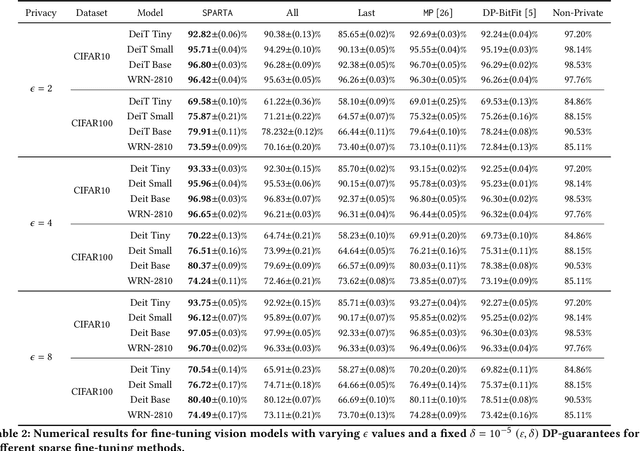
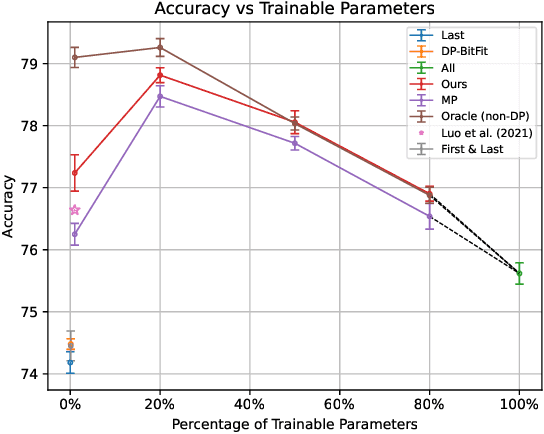
Differentially private stochastic gradient descent (DP-SGD) is broadly considered to be the gold standard for training and fine-tuning neural networks under differential privacy (DP). With the increasing availability of high-quality pre-trained model checkpoints (e.g., vision and language models), fine-tuning has become a popular strategy. However, despite recent progress in understanding and applying DP-SGD for private transfer learning tasks, significant challenges remain -- most notably, the performance gap between models fine-tuned with DP-SGD and their non-private counterparts. Sparse fine-tuning on private data has emerged as an alternative to full-model fine-tuning; recent work has shown that privately fine-tuning only a small subset of model weights and keeping the rest of the weights fixed can lead to better performance. In this work, we propose a new approach for sparse fine-tuning of neural networks under DP. Existing work on private sparse finetuning often used fixed choice of trainable weights (e.g., updating only the last layer), or relied on public model's weights to choose the subset of weights to modify. Such choice of weights remains suboptimal. In contrast, we explore an optimization-based approach, where our selection method makes use of the private gradient information, while using off the shelf privacy accounting techniques. Our numerical experiments on several computer vision models and datasets show that our selection method leads to better prediction accuracy, compared to full-model private fine-tuning or existing private sparse fine-tuning approaches.
Synthesizing Privacy-Preserving Text Data via Finetuning without Finetuning Billion-Scale LLMs
Mar 16, 2025Synthetic data offers a promising path to train models while preserving data privacy. Differentially private (DP) finetuning of large language models (LLMs) as data generator is effective, but is impractical when computation resources are limited. Meanwhile, prompt-based methods such as private evolution, depend heavily on the manual prompts, and ineffectively use private information in their iterative data selection process. To overcome these limitations, we propose CTCL (Data Synthesis with ConTrollability and CLustering), a novel framework for generating privacy-preserving synthetic data without extensive prompt engineering or billion-scale LLM finetuning. CTCL pretrains a lightweight 140M conditional generator and a clustering-based topic model on large-scale public data. To further adapt to the private domain, the generator is DP finetuned on private data for fine-grained textual information, while the topic model extracts a DP histogram representing distributional information. The DP generator then samples according to the DP histogram to synthesize a desired number of data examples. Evaluation across five diverse domains demonstrates the effectiveness of our framework, particularly in the strong privacy regime. Systematic ablation validates the design of each framework component and highlights the scalability of our approach.
Initialization Matters: Unraveling the Impact of Pre-Training on Federated Learning
Feb 11, 2025Initializing with pre-trained models when learning on downstream tasks is becoming standard practice in machine learning. Several recent works explore the benefits of pre-trained initialization in a federated learning (FL) setting, where the downstream training is performed at the edge clients with heterogeneous data distribution. These works show that starting from a pre-trained model can substantially reduce the adverse impact of data heterogeneity on the test performance of a model trained in a federated setting, with no changes to the standard FedAvg training algorithm. In this work, we provide a deeper theoretical understanding of this phenomenon. To do so, we study the class of two-layer convolutional neural networks (CNNs) and provide bounds on the training error convergence and test error of such a network trained with FedAvg. We introduce the notion of aligned and misaligned filters at initialization and show that the data heterogeneity only affects learning on misaligned filters. Starting with a pre-trained model typically results in fewer misaligned filters at initialization, thus producing a lower test error even when the model is trained in a federated setting with data heterogeneity. Experiments in synthetic settings and practical FL training on CNNs verify our theoretical findings.
HASSLE-free: A unified Framework for Sparse plus Low-Rank Matrix Decomposition for LLMs
Feb 02, 2025The impressive capabilities of large foundation models come at a cost of substantial computing resources to serve them. Compressing these pre-trained models is of practical interest as it can democratize deploying them to the machine learning community at large by lowering the costs associated with inference. A promising compression scheme is to decompose foundation models' dense weights into a sum of sparse plus low-rank matrices. In this paper, we design a unified framework coined HASSLE-free for (semi-structured) sparse plus low-rank matrix decomposition of foundation models. Our framework introduces the local layer-wise reconstruction error objective for this decomposition, we demonstrate that prior work solves a relaxation of this optimization problem; and we provide efficient and scalable methods to minimize the exact introduced optimization problem. HASSLE-free substantially outperforms state-of-the-art methods in terms of the introduced objective and a wide range of LLM evaluation benchmarks. For the Llama3-8B model with a 2:4 sparsity component plus a 64-rank component decomposition, a compression scheme for which recent work shows important inference acceleration on GPUs, HASSLE-free reduces the test perplexity by 12% for the WikiText-2 dataset and reduces the gap (compared to the dense model) of the average of eight popular zero-shot tasks by 15% compared to existing methods.
Federated Learning in Practice: Reflections and Projections
Oct 11, 2024

Federated Learning (FL) is a machine learning technique that enables multiple entities to collaboratively learn a shared model without exchanging their local data. Over the past decade, FL systems have achieved substantial progress, scaling to millions of devices across various learning domains while offering meaningful differential privacy (DP) guarantees. Production systems from organizations like Google, Apple, and Meta demonstrate the real-world applicability of FL. However, key challenges remain, including verifying server-side DP guarantees and coordinating training across heterogeneous devices, limiting broader adoption. Additionally, emerging trends such as large (multi-modal) models and blurred lines between training, inference, and personalization challenge traditional FL frameworks. In response, we propose a redefined FL framework that prioritizes privacy principles rather than rigid definitions. We also chart a path forward by leveraging trusted execution environments and open-source ecosystems to address these challenges and facilitate future advancements in FL.