 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCGBandit: One-shot acceleration of transient PDE solvers via online-learned preconditioners
Sep 10, 2025



Data-driven acceleration of scientific computing workflows has been a high-profile aim of machine learning (ML) for science, with numerical simulation of transient partial differential equations (PDEs) being one of the main applications. The focus thus far has been on methods that require classical simulations to train, which when combined with the data-hungriness and optimization challenges of neural networks has caused difficulties in demonstrating a convincing advantage against strong classical baselines. We consider an alternative paradigm in which the learner uses a classical solver's own data to accelerate it, enabling a one-shot speedup of the simulation. Concretely, since transient PDEs often require solving a sequence of related linear systems, the feedback from repeated calls to a linear solver such as preconditioned conjugate gradient (PCG) can be used by a bandit algorithm to online-learn an adaptive sequence of solver configurations (e.g. preconditioners). The method we develop, PCGBandit, is implemented directly on top of the popular open source software OpenFOAM, which we use to show its effectiveness on a set of fluid and magnetohydrodynamics (MHD) problems.
SureMap: Simultaneous Mean Estimation for Single-Task and Multi-Task Disaggregated Evaluation
Nov 14, 2024



Disaggregated evaluation -- estimation of performance of a machine learning model on different subpopulations -- is a core task when assessing performance and group-fairness of AI systems. A key challenge is that evaluation data is scarce, and subpopulations arising from intersections of attributes (e.g., race, sex, age) are often tiny. Today, it is common for multiple clients to procure the same AI model from a model developer, and the task of disaggregated evaluation is faced by each customer individually. This gives rise to what we call the multi-task disaggregated evaluation problem, wherein multiple clients seek to conduct a disaggregated evaluation of a given model in their own data setting (task). In this work we develop a disaggregated evaluation method called SureMap that has high estimation accuracy for both multi-task and single-task disaggregated evaluations of blackbox models. SureMap's efficiency gains come from (1) transforming the problem into structured simultaneous Gaussian mean estimation and (2) incorporating external data, e.g., from the AI system creator or from their other clients. Our method combines maximum a posteriori (MAP) estimation using a well-chosen prior together with cross-validation-free tuning via Stein's unbiased risk estimate (SURE). We evaluate SureMap on disaggregated evaluation tasks in multiple domains, observing significant accuracy improvements over several strong competitors.
Specialized Foundation Models Struggle to Beat Supervised Baselines
Nov 05, 2024



Following its success for vision and text, the "foundation model" (FM) paradigm -- pretraining large models on massive data, then fine-tuning on target tasks -- has rapidly expanded to domains in the sciences, engineering, healthcare, and beyond. Has this achieved what the original FMs accomplished, i.e. the supplanting of traditional supervised learning in their domains? To answer we look at three modalities -- genomics, satellite imaging, and time series -- with multiple recent FMs and compare them to a standard supervised learning workflow: model development, hyperparameter tuning, and training, all using only data from the target task. Across these three specialized domains, we find that it is consistently possible to train simple supervised models -- no more complicated than a lightly modified wide ResNet or UNet -- that match or even outperform the latest foundation models. Our work demonstrates that the benefits of large-scale pretraining have yet to be realized in many specialized areas, reinforces the need to compare new FMs to strong, well-tuned baselines, and introduces two new, easy-to-use, open-source, and automated workflows for doing so.
Learning to Relax: Setting Solver Parameters Across a Sequence of Linear System Instances
Oct 03, 2023Solving a linear system $Ax=b$ is a fundamental scientific computing primitive for which numerous solvers and preconditioners have been developed. These come with parameters whose optimal values depend on the system being solved and are often impossible or too expensive to identify; thus in practice sub-optimal heuristics are used. We consider the common setting in which many related linear systems need to be solved, e.g. during a single numerical simulation. In this scenario, can we sequentially choose parameters that attain a near-optimal overall number of iterations, without extra matrix computations? We answer in the affirmative for Successive Over-Relaxation (SOR), a standard solver whose parameter $\omega$ has a strong impact on its runtime. For this method, we prove that a bandit online learning algorithm -- using only the number of iterations as feedback -- can select parameters for a sequence of instances such that the overall cost approaches that of the best fixed $\omega$ as the sequence length increases. Furthermore, when given additional structural information, we show that a contextual bandit method asymptotically achieves the performance of the instance-optimal policy, which selects the best $\omega$ for each instance. Our work provides the first learning-theoretic treatment of high-precision linear system solvers and the first end-to-end guarantees for data-driven scientific computing, demonstrating theoretically the potential to speed up numerical methods using well-understood learning algorithms.
Meta-Learning Adversarial Bandit Algorithms
Jul 05, 2023We study online meta-learning with bandit feedback, with the goal of improving performance across multiple tasks if they are similar according to some natural similarity measure. As the first to target the adversarial online-within-online partial-information setting, we design meta-algorithms that combine outer learners to simultaneously tune the initialization and other hyperparameters of an inner learner for two important cases: multi-armed bandits (MAB) and bandit linear optimization (BLO). For MAB, the meta-learners initialize and set hyperparameters of the Tsallis-entropy generalization of Exp3, with the task-averaged regret improving if the entropy of the optima-in-hindsight is small. For BLO, we learn to initialize and tune online mirror descent (OMD) with self-concordant barrier regularizers, showing that task-averaged regret varies directly with an action space-dependent measure they induce. Our guarantees rely on proving that unregularized follow-the-leader combined with two levels of low-dimensional hyperparameter tuning is enough to learn a sequence of affine functions of non-Lipschitz and sometimes non-convex Bregman divergences bounding the regret of OMD.
Cross-Modal Fine-Tuning: Align then Refine
Feb 11, 2023



Fine-tuning large-scale pretrained models has led to tremendous progress in well-studied modalities such as vision and NLP. However, similar gains have not been observed in many other modalities due to a lack of relevant pretrained models. In this work, we propose ORCA, a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. Through extensive experiments, we show that ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities, outperforming a wide range of hand-designed, AutoML, general-purpose, and task-specific methods. We highlight the importance of data alignment via a series of ablation studies and demonstrate ORCA's utility in data-limited regimes.
On Noisy Evaluation in Federated Hyperparameter Tuning
Jan 05, 2023Hyperparameter tuning is critical to the success of federated learning applications. Unfortunately, appropriately selecting hyperparameters is challenging in federated networks. Issues of scale, privacy, and heterogeneity introduce noise in the tuning process and make it difficult to evaluate the performance of various hyperparameters. In this work, we perform the first systematic study on the effect of noisy evaluation in federated hyperparameter tuning. We first identify and rigorously explore key sources of noise, including client subsampling, data and systems heterogeneity, and data privacy. Surprisingly, our results indicate that even small amounts of noise can significantly impact tuning methods-reducing the performance of state-of-the-art approaches to that of naive baselines. To address noisy evaluation in such scenarios, we propose a simple and effective approach that leverages public proxy data to boost the evaluation signal. Our work establishes general challenges, baselines, and best practices for future work in federated hyperparameter tuning.
Private Algorithms with Private Predictions
Oct 20, 2022



When applying differential privacy to sensitive data, a common way of getting improved performance is to use external information such as other sensitive data, public data, or human priors. We propose to use the algorithms with predictions framework -- previously applied largely to improve time complexity or competitive ratios -- as a powerful way of designing and analyzing privacy-preserving methods that can take advantage of such external information to improve utility. For four important tasks -- quantile release, its extension to multiple quantiles, covariance estimation, and data release -- we construct prediction-dependent differentially private methods whose utility scales with natural measures of prediction quality. The analyses enjoy several advantages, including minimal assumptions about the data, natural ways of adding robustness to noisy predictions, and novel "meta" algorithms that can learn predictions from other (potentially sensitive) data. Overall, our results demonstrate how to enable differentially private algorithms to make use of and learn noisy predictions, which holds great promise for improving utility while preserving privacy across a variety of tasks.
Provably tuning the ElasticNet across instances
Jul 20, 2022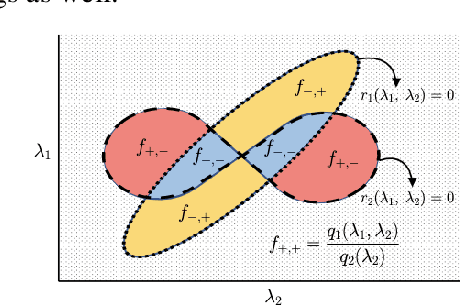
An important unresolved challenge in the theory of regularization is to set the regularization coefficients of popular techniques like the ElasticNet with general provable guarantees. We consider the problem of tuning the regularization parameters of Ridge regression, LASSO, and the ElasticNet across multiple problem instances, a setting that encompasses both cross-validation and multi-task hyperparameter optimization. We obtain a novel structural result for the ElasticNet which characterizes the loss as a function of the tuning parameters as a piecewise-rational function with algebraic boundaries. We use this to bound the structural complexity of the regularized loss functions and show generalization guarantees for tuning the ElasticNet regression coefficients in the statistical setting. We also consider the more challenging online learning setting, where we show vanishing average expected regret relative to the optimal parameter pair. We further extend our results to tuning classification algorithms obtained by thresholding regression fits regularized by Ridge, LASSO, or ElasticNet. Our results are the first general learning-theoretic guarantees for this important class of problems that avoid strong assumptions on the data distribution. Furthermore, our guarantees hold for both validation and popular information criterion objectives.
Meta-Learning Adversarial Bandits
May 27, 2022We study online learning with bandit feedback across multiple tasks, with the goal of improving average performance across tasks if they are similar according to some natural task-similarity measure. As the first to target the adversarial setting, we design a unified meta-algorithm that yields setting-specific guarantees for two important cases: multi-armed bandits (MAB) and bandit linear optimization (BLO). For MAB, the meta-algorithm tunes the initialization, step-size, and entropy parameter of the Tsallis-entropy generalization of the well-known Exp3 method, with the task-averaged regret provably improving if the entropy of the distribution over estimated optima-in-hindsight is small. For BLO, we learn the initialization, step-size, and boundary-offset of online mirror descent (OMD) with self-concordant barrier regularizers, showing that task-averaged regret varies directly with a measure induced by these functions on the interior of the action space. Our adaptive guarantees rely on proving that unregularized follow-the-leader combined with multiplicative weights is enough to online learn a non-smooth and non-convex sequence of affine functions of Bregman divergences that upper-bound the regret of OMD.