 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-DPO: Vision-Language-Guided Finetuning for Preference-Aligned Autonomous Driving
May 19, 2026The rapid growth of autonomous driving datasets has enabled the scaling of powerful motion forecasting models. While large-scale pretraining provides strong performance, the standard imitation objective may not fully capture the complex nuances of human driving preferences. Meanwhile, recent advances in vision-language models (VLMs) have demonstrated impressive reasoning and commonsense understanding. Building on these capabilities, this paper presents VL-DPO, a vision-language-guided framework that aligns ego-vehicle motion forecasting models with human preferences. Our approach leverages a VLM as a zero-shot reasoner to automatically generate preference pairs from a pretrained model's rollouts, which are then used to finetune the model via Direct Preference Optimization (DPO). We finetune our models on the Waymo Open End-to-End Driving Dataset (WOD-E2E) and evaluate performance against held-out human preference annotations using rater feedback score (RFS) and average displacement error (ADE). Our experiments confirm that the VLM's trajectory selection is a high-quality proxy for human preference. Our final model, VL-DPO, yields an 11.94% increase in RFS and a 10.01% reduction in ADE over the pretrained model.
Scaling Laws of Motion Forecasting and Planning -- A Technical Report
Jun 09, 2025We study the empirical scaling laws of a family of encoder-decoder autoregressive transformer models on the task of joint motion forecasting and planning in the autonomous driving domain. Using a 500 thousand hours driving dataset, we demonstrate that, similar to language modeling, model performance improves as a power-law function of the total compute budget, and we observe a strong correlation between model training loss and model evaluation metrics. Most interestingly, closed-loop metrics also improve with scaling, which has important implications for the suitability of open-loop metrics for model development and hill climbing. We also study the optimal scaling of the number of transformer parameters and the training data size for a training compute-optimal model. We find that as the training compute budget grows, optimal scaling requires increasing the model size 1.5x as fast as the dataset size. We also study inference-time compute scaling, where we observe that sampling and clustering the output of smaller models makes them competitive with larger models, up to a crossover point beyond which a larger models becomes more inference-compute efficient. Overall, our experimental results demonstrate that optimizing the training and inference-time scaling properties of motion forecasting and planning models is a key lever for improving their performance to address a wide variety of driving scenarios. Finally, we briefly study the utility of training on general logged driving data of other agents to improve the performance of the ego-agent, an important research area to address the scarcity of robotics data for large capacity models training.
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Nov 23, 2022Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
A Simple Approach to Improve Single-Model Deep Uncertainty via Distance-Awareness
May 01, 2022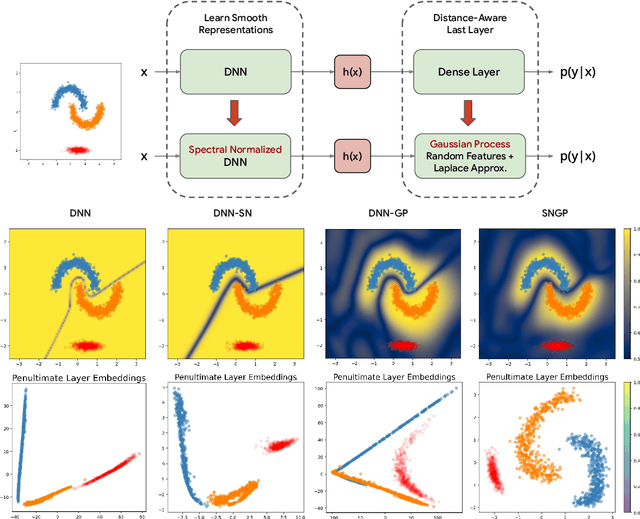
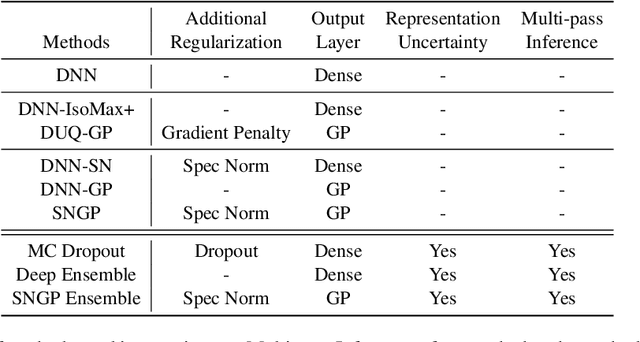
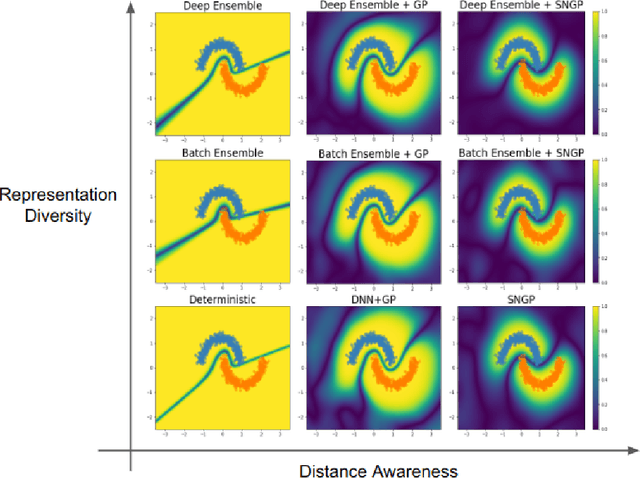
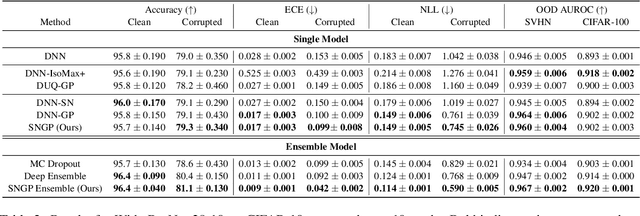
Accurate uncertainty quantification is a major challenge in deep learning, as neural networks can make overconfident errors and assign high confidence predictions to out-of-distribution (OOD) inputs. The most popular approaches to estimate predictive uncertainty in deep learning are methods that combine predictions from multiple neural networks, such as Bayesian neural networks (BNNs) and deep ensembles. However their practicality in real-time, industrial-scale applications are limited due to the high memory and computational cost. Furthermore, ensembles and BNNs do not necessarily fix all the issues with the underlying member networks. In this work, we study principled approaches to improve uncertainty property of a single network, based on a single, deterministic representation. By formalizing the uncertainty quantification as a minimax learning problem, we first identify distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs with two simple changes: (1) applying spectral normalization to hidden weights to enforce bi-Lipschitz smoothness in representations and (2) replacing the last output layer with a Gaussian process layer. On a suite of vision and language understanding benchmarks, SNGP outperforms other single-model approaches in prediction, calibration and out-of-domain detection. Furthermore, SNGP provides complementary benefits to popular techniques such as deep ensembles and data augmentation, making it a simple and scalable building block for probabilistic deep learning. Code is open-sourced at https://github.com/google/uncertainty-baselines
Sparse MoEs meet Efficient Ensembles
Oct 07, 2021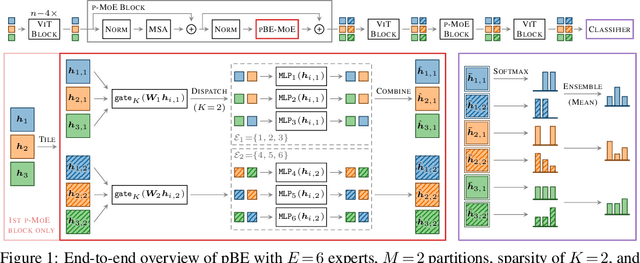

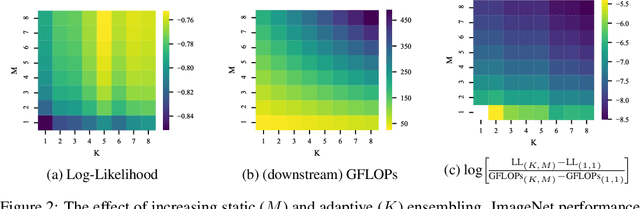
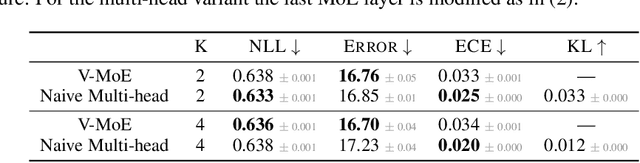
Machine learning models based on the aggregated outputs of submodels, either at the activation or prediction levels, lead to strong performance. We study the interplay of two popular classes of such models: ensembles of neural networks and sparse mixture of experts (sparse MoEs). First, we show that these two approaches have complementary features whose combination is beneficial. Then, we present partitioned batch ensembles, an efficient ensemble of sparse MoEs that takes the best of both classes of models. Extensive experiments on fine-tuned vision transformers demonstrate the accuracy, log-likelihood, few-shot learning, robustness, and uncertainty calibration improvements of our approach over several challenging baselines. Partitioned batch ensembles not only scale to models with up to 2.7B parameters, but also provide larger performance gains for larger models.
Variational Refinement for Importance Sampling Using the Forward Kullback-Leibler Divergence
Jun 30, 2021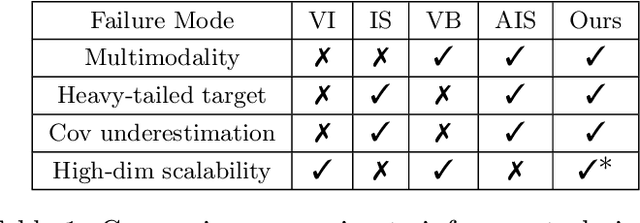

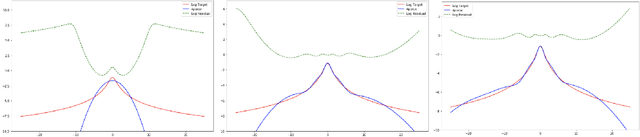
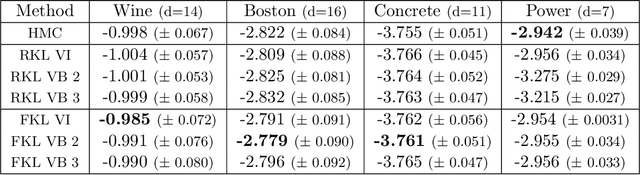
Variational Inference (VI) is a popular alternative to asymptotically exact sampling in Bayesian inference. Its main workhorse is optimization over a reverse Kullback-Leibler divergence (RKL), which typically underestimates the tail of the posterior leading to miscalibration and potential degeneracy. Importance sampling (IS), on the other hand, is often used to fine-tune and de-bias the estimates of approximate Bayesian inference procedures. The quality of IS crucially depends on the choice of the proposal distribution. Ideally, the proposal distribution has heavier tails than the target, which is rarely achievable by minimizing the RKL. We thus propose a novel combination of optimization and sampling techniques for approximate Bayesian inference by constructing an IS proposal distribution through the minimization of a forward KL (FKL) divergence. This approach guarantees asymptotic consistency and a fast convergence towards both the optimal IS estimator and the optimal variational approximation. We empirically demonstrate on real data that our method is competitive with variational boosting and MCMC.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021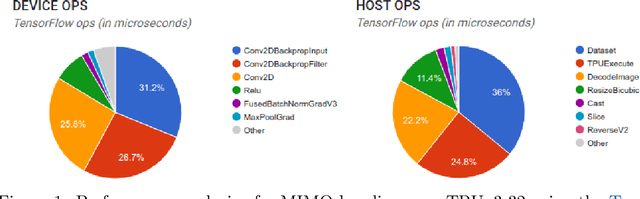
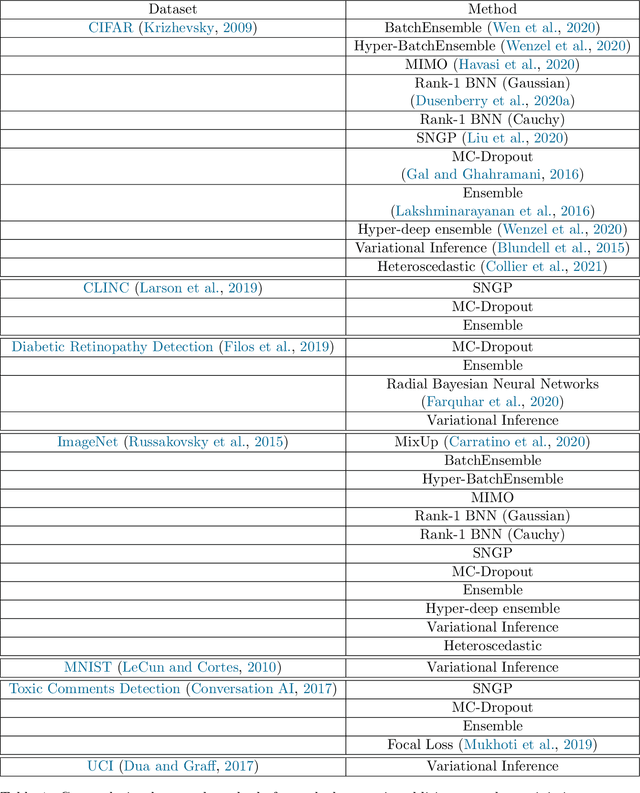
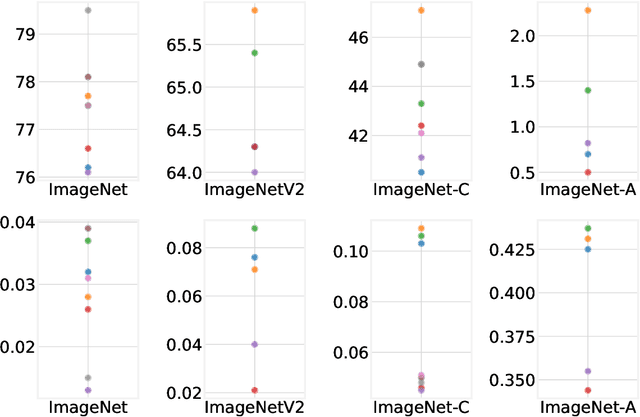
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
Combining Ensembles and Data Augmentation can Harm your Calibration
Oct 19, 2020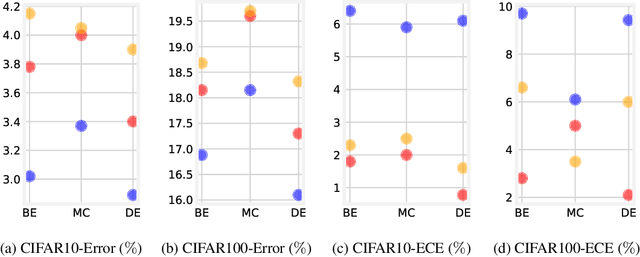
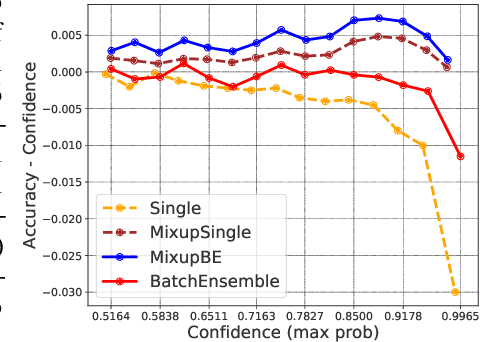
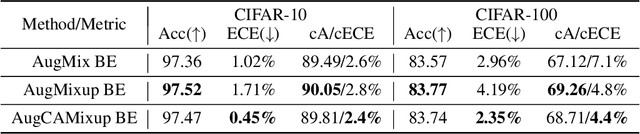
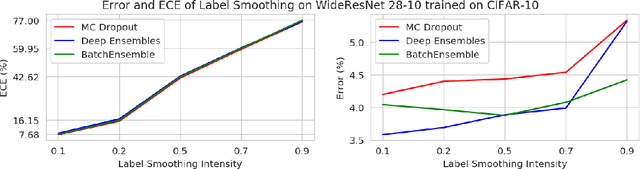
Ensemble methods which average over multiple neural network predictions are a simple approach to improve a model's calibration and robustness. Similarly, data augmentation techniques, which encode prior information in the form of invariant feature transformations, are effective for improving calibration and robustness. In this paper, we show a surprising pathology: combining ensembles and data augmentation can harm model calibration. This leads to a trade-off in practice, whereby improved accuracy by combining the two techniques comes at the expense of calibration. On the other hand, selecting only one of the techniques ensures good uncertainty estimates at the expense of accuracy. We investigate this pathology and identify a compounding under-confidence among methods which marginalize over sets of weights and data augmentation techniques which soften labels. Finally, we propose a simple correction, achieving the best of both worlds with significant accuracy and calibration gains over using only ensembles or data augmentation individually. Applying the correction produces new state-of-the art in uncertainty calibration across CIFAR-10, CIFAR-100, and ImageNet.
Efficient and Scalable Bayesian Neural Nets with Rank-1 Factors
May 14, 2020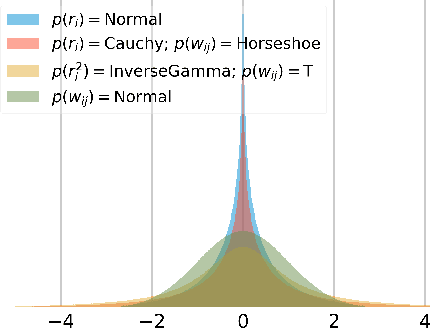
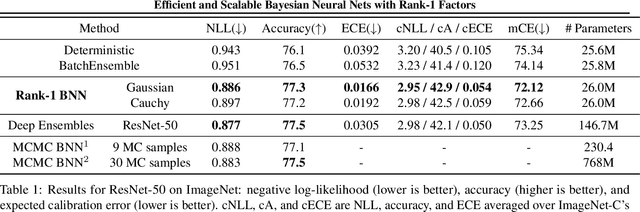
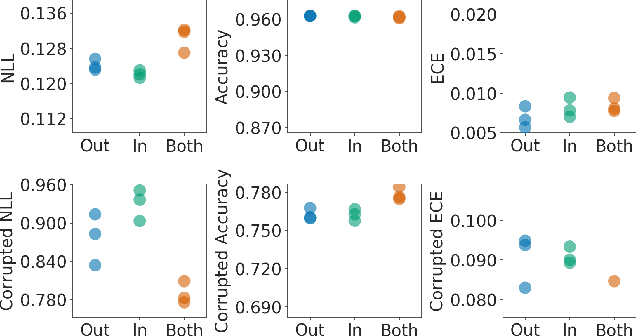
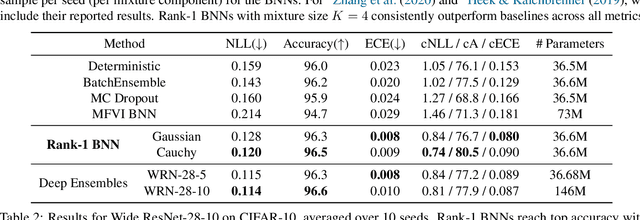
Bayesian neural networks (BNNs) demonstrate promising success in improving the robustness and uncertainty quantification of modern deep learning. However, they generally struggle with underfitting at scale and parameter efficiency. On the other hand, deep ensembles have emerged as alternatives for uncertainty quantification that, while outperforming BNNs on certain problems, also suffer from efficiency issues. It remains unclear how to combine the strengths of these two approaches and remediate their common issues. To tackle this challenge, we propose a rank-1 parameterization of BNNs, where each weight matrix involves only a distribution on a rank-1 subspace. We also revisit the use of mixture approximate posteriors to capture multiple modes, where unlike typical mixtures, this approach admits a significantly smaller memory increase (e.g., only a 0.4% increase for a ResNet-50 mixture of size 10). We perform a systematic empirical study on the choices of prior, variational posterior, and methods to improve training. For ResNet-50 on ImageNet, Wide ResNet 28-10 on CIFAR-10/100, and an RNN on MIMIC-III, rank-1 BNNs achieve state-of-the-art performance across log-likelihood, accuracy, and calibration on the test sets and out-of-distribution variants.