 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBipartite Ranking From Multiple Labels: On Loss Versus Label Aggregation
Apr 15, 2025
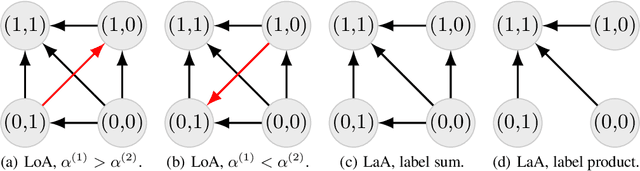

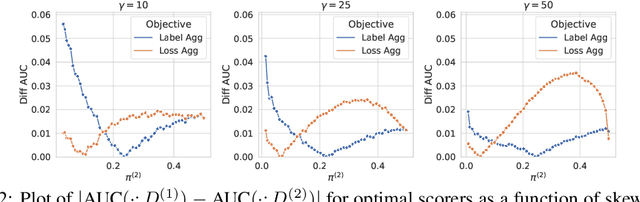
Bipartite ranking is a fundamental supervised learning problem, with the goal of learning a ranking over instances with maximal area under the ROC curve (AUC) against a single binary target label. However, one may often observe multiple binary target labels, e.g., from distinct human annotators. How can one synthesize such labels into a single coherent ranking? In this work, we formally analyze two approaches to this problem -- loss aggregation and label aggregation -- by characterizing their Bayes-optimal solutions. Based on this, we show that while both methods can yield Pareto-optimal solutions, loss aggregation can exhibit label dictatorship: one can inadvertently (and undesirably) favor one label over others. This suggests that label aggregation can be preferable to loss aggregation, which we empirically verify.
Automatic Engineering of Long Prompts
Nov 16, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in solving complex open-domain tasks, guided by comprehensive instructions and demonstrations provided in the form of prompts. However, these prompts can be lengthy, often comprising hundreds of lines and thousands of tokens, and their design often requires considerable human effort. Recent research has explored automatic prompt engineering for short prompts, typically consisting of one or a few sentences. However, the automatic design of long prompts remains a challenging problem due to its immense search space. In this paper, we investigate the performance of greedy algorithms and genetic algorithms for automatic long prompt engineering. We demonstrate that a simple greedy approach with beam search outperforms other methods in terms of search efficiency. Moreover, we introduce two novel techniques that utilize search history to enhance the effectiveness of LLM-based mutation in our search algorithm. Our results show that the proposed automatic long prompt engineering algorithm achieves an average of 9.2% accuracy gain on eight tasks in Big Bench Hard, highlighting the significance of automating prompt designs to fully harness the capabilities of LLMs.
FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients
Feb 16, 2022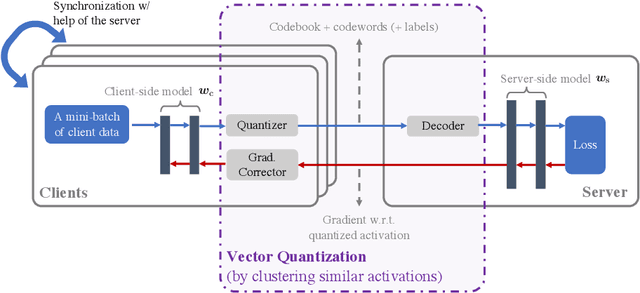

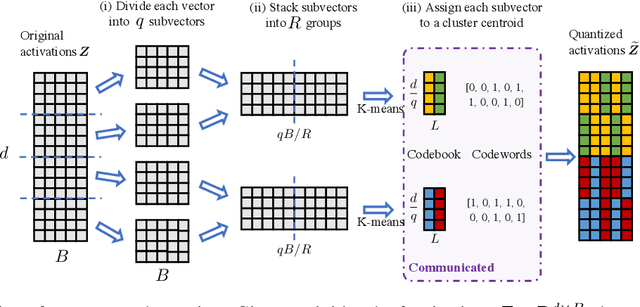
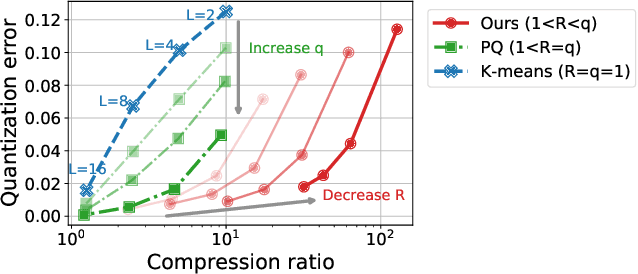
In classical federated learning, the clients contribute to the overall training by communicating local updates for the underlying model on their private data to a coordinating server. However, updating and communicating the entire model becomes prohibitively expensive when resource-constrained clients collectively aim to train a large machine learning model. Split learning provides a natural solution in such a setting, where only a small part of the model is stored and trained on clients while the remaining large part of the model only stays at the servers. However, the model partitioning employed in split learning introduces a significant amount of communication cost. This paper addresses this issue by compressing the additional communication using a novel clustering scheme accompanied by a gradient correction method. Extensive empirical evaluations on image and text benchmarks show that the proposed method can achieve up to $490\times$ communication cost reduction with minimal drop in accuracy, and enables a desirable performance vs. communication trade-off.
A Field Guide to Federated Optimization
Jul 14, 2021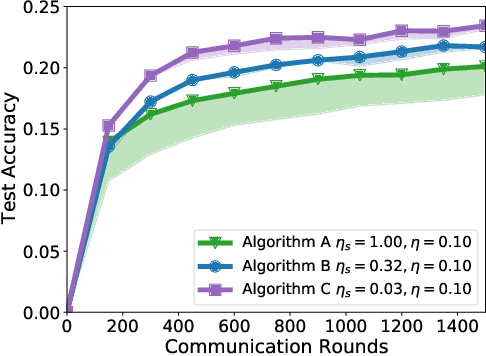


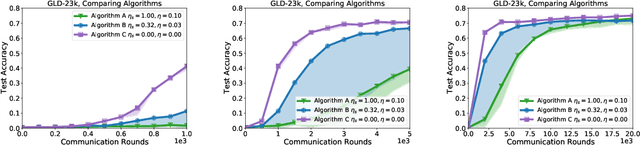
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Disentangling Sampling and Labeling Bias for Learning in Large-Output Spaces
May 12, 2021
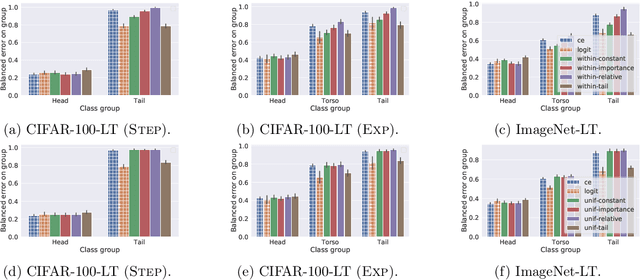

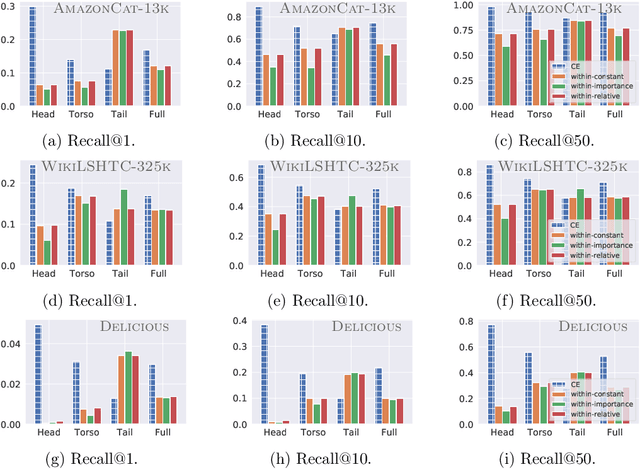
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Federated Learning with Only Positive Labels
Apr 21, 2020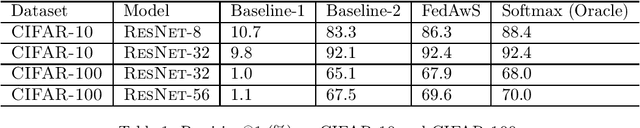

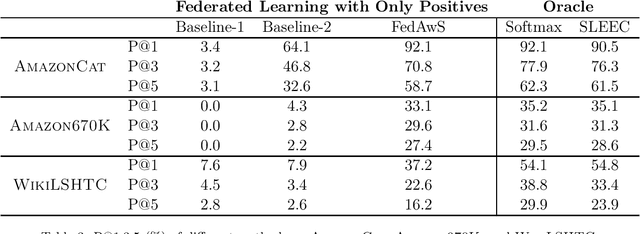

We consider learning a multi-class classification model in the federated setting, where each user has access to the positive data associated with only a single class. As a result, during each federated learning round, the users need to locally update the classifier without having access to the features and the model parameters for the negative classes. Thus, naively employing conventional decentralized learning such as the distributed SGD or Federated Averaging may lead to trivial or extremely poor classifiers. In particular, for the embedding based classifiers, all the class embeddings might collapse to a single point. To address this problem, we propose a generic framework for training with only positive labels, namely Federated Averaging with Spreadout (FedAwS), where the server imposes a geometric regularizer after each round to encourage classes to be spreadout in the embedding space. We show, both theoretically and empirically, that FedAwS can almost match the performance of conventional learning where users have access to negative labels. We further extend the proposed method to the settings with large output spaces.
Pre-training Tasks for Embedding-based Large-scale Retrieval
Feb 10, 2020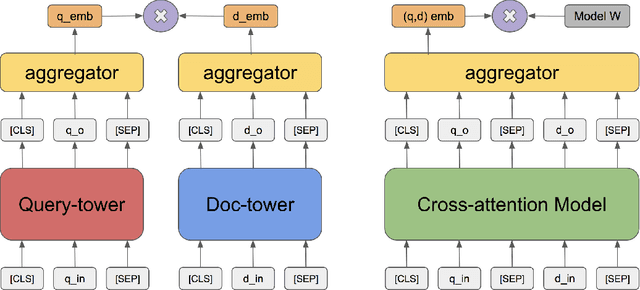
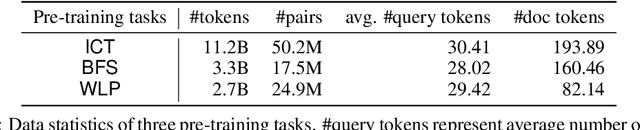

We consider the large-scale query-document retrieval problem: given a query (e.g., a question), return the set of relevant documents (e.g., paragraphs containing the answer) from a large document corpus. This problem is often solved in two steps. The retrieval phase first reduces the solution space, returning a subset of candidate documents. The scoring phase then re-ranks the documents. Critically, the retrieval algorithm not only desires high recall but also requires to be highly efficient, returning candidates in time sublinear to the number of documents. Unlike the scoring phase witnessing significant advances recently due to the BERT-style pre-training tasks on cross-attention models, the retrieval phase remains less well studied. Most previous works rely on classic Information Retrieval (IR) methods such as BM-25 (token matching + TF-IDF weights). These models only accept sparse handcrafted features and can not be optimized for different downstream tasks of interest. In this paper, we conduct a comprehensive study on the embedding-based retrieval models. We show that the key ingredient of learning a strong embedding-based Transformer model is the set of pre-training tasks. With adequately designed paragraph-level pre-training tasks, the Transformer models can remarkably improve over the widely-used BM-25 as well as embedding models without Transformers. The paragraph-level pre-training tasks we studied are Inverse Cloze Task (ICT), Body First Selection (BFS), Wiki Link Prediction (WLP), and the combination of all three.
Advances and Open Problems in Federated Learning
Dec 10, 2019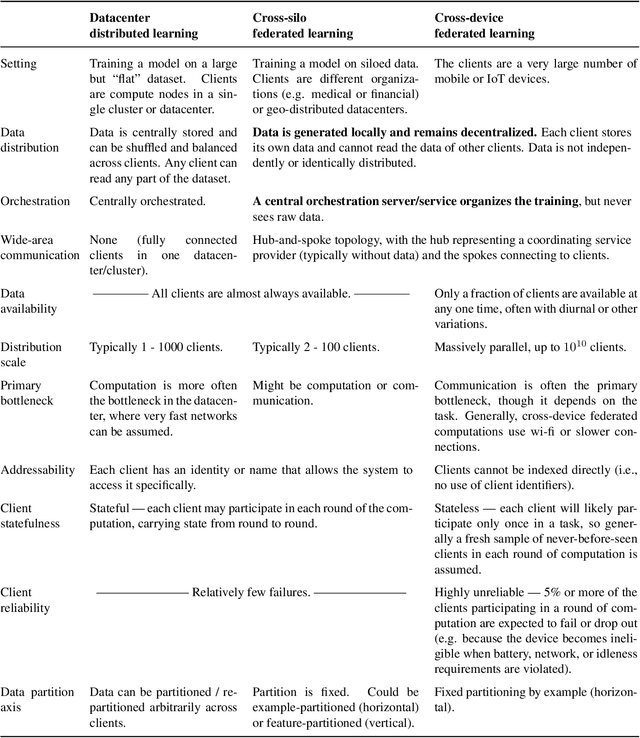
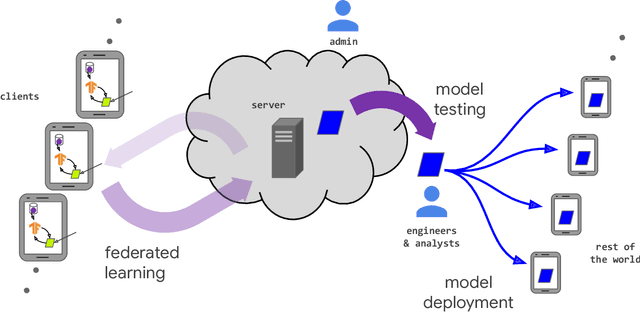
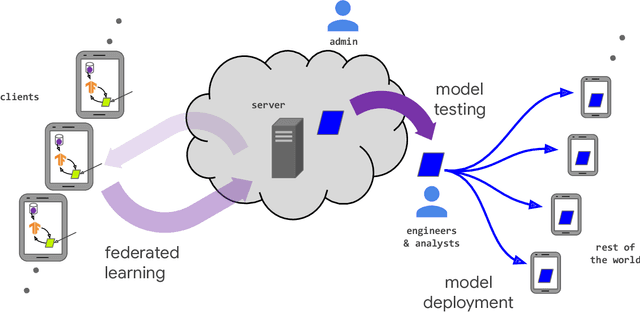

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
AdaCliP: Adaptive Clipping for Private SGD
Aug 20, 2019
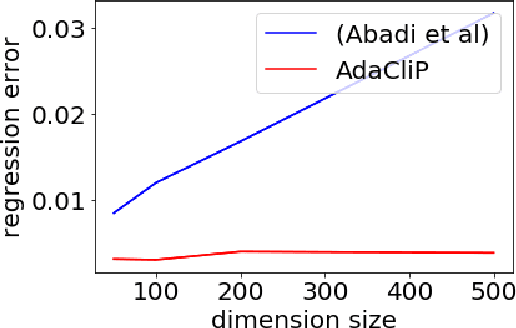
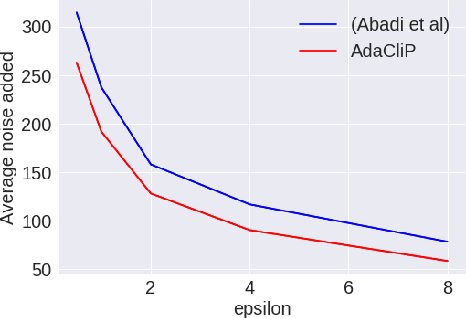

Privacy preserving machine learning algorithms are crucial for learning models over user data to protect sensitive information. Motivated by this, differentially private stochastic gradient descent (SGD) algorithms for training machine learning models have been proposed. At each step, these algorithms modify the gradients and add noise proportional to the sensitivity of the modified gradients. Under this framework, we propose AdaCliP, a theoretically motivated differentially private SGD algorithm that provably adds less noise compared to the previous methods, by using coordinate-wise adaptive clipping of the gradient. We empirically demonstrate that AdaCliP reduces the amount of added noise and produces models with better accuracy.
The Sparse Recovery Autoencoder
Jul 05, 2018
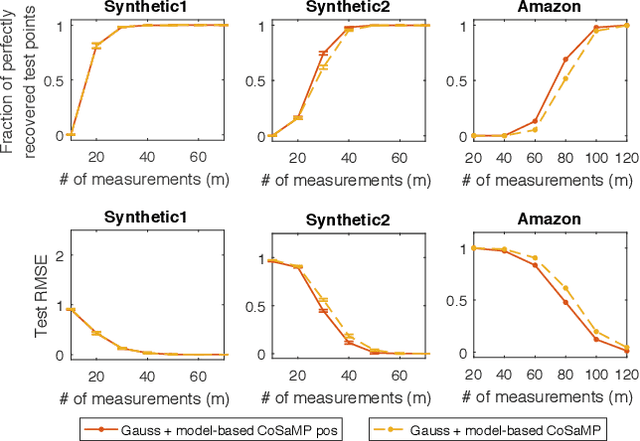
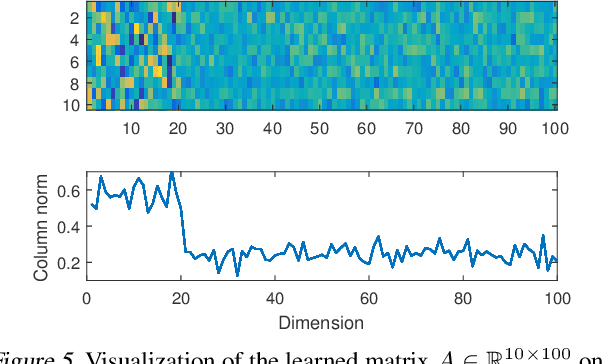
Linear encoding of sparse vectors is widely popular, but is most commonly data-independent -- missing any possible extra (but a-priori unknown) structure beyond sparsity. In this paper we present a new method to learn linear encoders that adapt to data, while still performing well with the widely used $\ell_1$ decoder. The convex $\ell_1$ decoder prevents gradient propagation as needed in standard autoencoder training. Our method is based on the insight that unfolding the convex decoder into $T$ projected gradient steps can address this issue. Our method can be seen as a data-driven way to learn a compressed sensing matrix. Our experiments show that there is indeed additional structure beyond sparsity in several real datasets. Our autoencoder is able to discover it and exploit it to create excellent reconstructions with fewer measurements compared to the previous state of the art methods.