 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Speech Technologies for Australian Aboriginal English: Opportunities, Risks and Participation
Mar 05, 2025In Australia, post-contact language varieties, including creoles and local varieties of international languages, emerged as a result of forced contact between Indigenous communities and English speakers. These contact varieties are widely used, yet are poorly supported by language technologies. This gap presents barriers to participation in civil and economic society for Indigenous communities using these varieties, and reproduces minoritisation of contemporary Indigenous sociolinguistic identities. This paper concerns three questions regarding this context. First, can speech technologies support speakers of Australian Aboriginal English, a local indigenised variety of English? Second, what risks are inherent in such a project? Third, what technology development practices are appropriate for this context, and how can researchers integrate meaningful community participation in order to mitigate risks? We argue that opportunities do exist -- as well as risks -- and demonstrate this through a case study exploring design practices in a real-world project aiming to improve speech technologies for Australian Aboriginal English. We discuss how we integrated culturally appropriate and participatory processes throughout the project. We call for increased support for languages used by Indigenous communities, including contact varieties, which provide practical economic and socio-cultural benefits, provided that participatory and culturally safe practices are enacted.
Socially Responsible Data for Large Multilingual Language Models
Sep 08, 2024
Large Language Models (LLMs) have rapidly increased in size and apparent capabilities in the last three years, but their training data is largely English text. There is growing interest in multilingual LLMs, and various efforts are striving for models to accommodate languages of communities outside of the Global North, which include many languages that have been historically underrepresented in digital realms. These languages have been coined as "low resource languages" or "long-tail languages", and LLMs performance on these languages is generally poor. While expanding the use of LLMs to more languages may bring many potential benefits, such as assisting cross-community communication and language preservation, great care must be taken to ensure that data collection on these languages is not extractive and that it does not reproduce exploitative practices of the past. Collecting data from languages spoken by previously colonized people, indigenous people, and non-Western languages raises many complex sociopolitical and ethical questions, e.g., around consent, cultural safety, and data sovereignty. Furthermore, linguistic complexity and cultural nuances are often lost in LLMs. This position paper builds on recent scholarship, and our own work, and outlines several relevant social, cultural, and ethical considerations and potential ways to mitigate them through qualitative research, community partnerships, and participatory design approaches. We provide twelve recommendations for consideration when collecting language data on underrepresented language communities outside of the Global North.
Modeling the Sacred: Considerations when Using Considerations when Using Religious Texts in Natural Language Processing
Apr 23, 2024



This position paper concerns the use of religious texts in Natural Language Processing (NLP), which is of special interest to the Ethics of NLP. Religious texts are expressions of culturally important values, and machine learned models have a propensity to reproduce cultural values encoded in their training data. Furthermore, translations of religious texts are frequently used by NLP researchers when language data is scarce. This repurposes the translations from their original uses and motivations, which often involve attracting new followers. This paper argues that NLP's use of such texts raises considerations that go beyond model biases, including data provenance, cultural contexts, and their use in proselytism. We argue for more consideration of researcher positionality, and of the perspectives of marginalized linguistic and religious communities.
"It's how you do things that matters": Attending to Process to Better Serve Indigenous Communities with Language Technologies
Feb 06, 2024Indigenous languages are historically under-served by Natural Language Processing (NLP) technologies, but this is changing for some languages with the recent scaling of large multilingual models and an increased focus by the NLP community on endangered languages. This position paper explores ethical considerations in building NLP technologies for Indigenous languages, based on the premise that such projects should primarily serve Indigenous communities. We report on interviews with 17 researchers working in or with Aboriginal and/or Torres Strait Islander communities on language technology projects in Australia. Drawing on insights from the interviews, we recommend practices for NLP researchers to increase attention to the process of engagements with Indigenous communities, rather than focusing only on decontextualised artefacts.
Cultural Incongruencies in Artificial Intelligence
Nov 19, 2022Artificial intelligence (AI) systems attempt to imitate human behavior. How well they do this imitation is often used to assess their utility and to attribute human-like (or artificial) intelligence to them. However, most work on AI refers to and relies on human intelligence without accounting for the fact that human behavior is inherently shaped by the cultural contexts they are embedded in, the values and beliefs they hold, and the social practices they follow. Additionally, since AI technologies are mostly conceived and developed in just a handful of countries, they embed the cultural values and practices of these countries. Similarly, the data that is used to train the models also fails to equitably represent global cultural diversity. Problems therefore arise when these technologies interact with globally diverse societies and cultures, with different values and interpretive practices. In this position paper, we describe a set of cultural dependencies and incongruencies in the context of AI-based language and vision technologies, and reflect on the possibilities of and potential strategies towards addressing these incongruencies.
Underspecification in Scene Description-to-Depiction Tasks
Oct 11, 2022

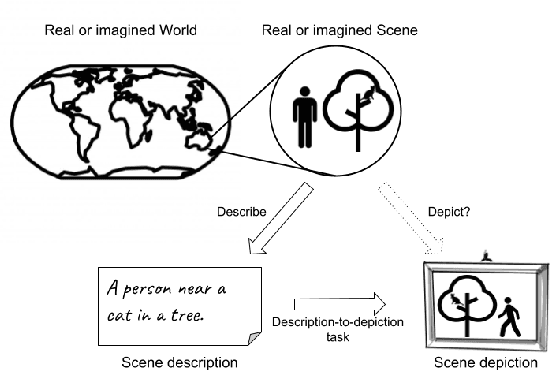

Questions regarding implicitness, ambiguity and underspecification are crucial for understanding the task validity and ethical concerns of multimodal image+text systems, yet have received little attention to date. This position paper maps out a conceptual framework to address this gap, focusing on systems which generate images depicting scenes from scene descriptions. In doing so, we account for how texts and images convey meaning differently. We outline a set of core challenges concerning textual and visual ambiguity, as well as risks that may be amplified by ambiguous and underspecified elements. We propose and discuss strategies for addressing these challenges, including generating visually ambiguous images, and generating a set of diverse images.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022

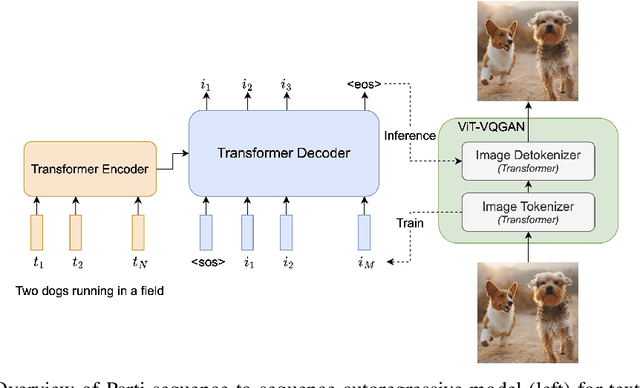
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Evaluation Gaps in Machine Learning Practice
May 11, 2022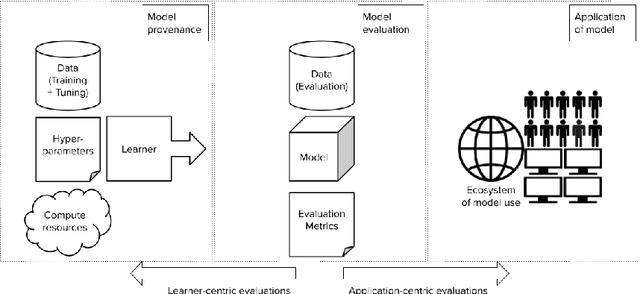

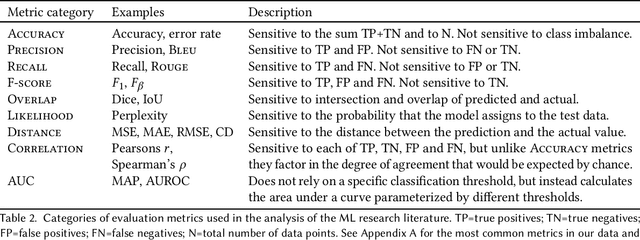
Forming a reliable judgement of a machine learning (ML) model's appropriateness for an application ecosystem is critical for its responsible use, and requires considering a broad range of factors including harms, benefits, and responsibilities. In practice, however, evaluations of ML models frequently focus on only a narrow range of decontextualized predictive behaviours. We examine the evaluation gaps between the idealized breadth of evaluation concerns and the observed narrow focus of actual evaluations. Through an empirical study of papers from recent high-profile conferences in the Computer Vision and Natural Language Processing communities, we demonstrate a general focus on a handful of evaluation methods. By considering the metrics and test data distributions used in these methods, we draw attention to which properties of models are centered in the field, revealing the properties that are frequently neglected or sidelined during evaluation. By studying these properties, we demonstrate the machine learning discipline's implicit assumption of a range of commitments which have normative impacts; these include commitments to consequentialism, abstractability from context, the quantifiability of impacts, the limited role of model inputs in evaluation, and the equivalence of different failure modes. Shedding light on these assumptions enables us to question their appropriateness for ML system contexts, pointing the way towards more contextualized evaluation methodologies for robustly examining the trustworthiness of ML models
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022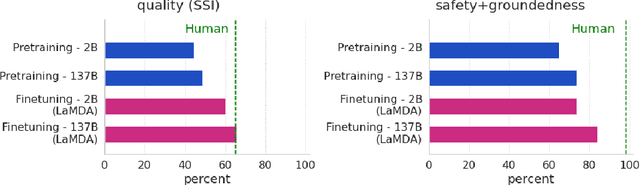
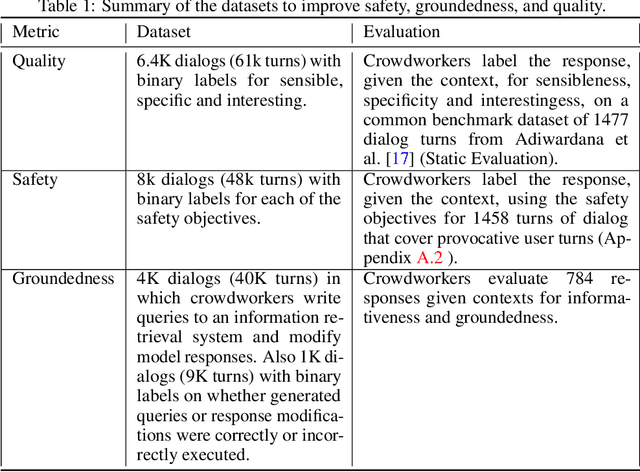

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.