 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudgeted Multiple-Expert Deferral
Oct 30, 2025Learning to defer uncertain predictions to costly experts offers a powerful strategy for improving the accuracy and efficiency of machine learning systems. However, standard training procedures for deferral algorithms typically require querying all experts for every training instance, an approach that becomes prohibitively expensive when expert queries incur significant computational or resource costs. This undermines the core goal of deferral: to limit unnecessary expert usage. To overcome this challenge, we introduce the budgeted deferral framework, which aims to train effective deferral algorithms while minimizing expert query costs during training. We propose new algorithms for both two-stage and single-stage multiple-expert deferral settings that selectively query only a subset of experts per training example. While inspired by active learning, our setting is fundamentally different: labels are already known, and the core challenge is to decide which experts to query in order to balance cost and predictive performance. We establish theoretical guarantees for both of our algorithms, including generalization bounds and label complexity analyses. Empirical results across several domains show that our algorithms substantially reduce training costs without sacrificing prediction accuracy, demonstrating the practical value of our budget-aware deferral algorithms.
No more hard prompts: SoftSRV prompting for synthetic data generation
Oct 23, 2024



We present a novel soft prompt based framework, SoftSRV, that leverages a frozen pre-trained large language model (LLM) to generate targeted synthetic text sequences. Given a sample from the target distribution, our proposed framework uses data-driven loss minimization to train a parameterized "contextual" soft prompt. This soft prompt is then used to steer the frozen LLM to generate synthetic sequences that are similar to the target distribution. We argue that SoftSRV provides a practical improvement over common hard-prompting approaches that rely on human-curated prompt-templates, which can be idiosyncratic, labor-intensive to craft, and may need to be specialized per domain. We empirically evaluate SoftSRV and hard-prompting baselines by generating synthetic data to fine-tune a small Gemma model on three different domains (coding, math, reasoning). To stress the generality of SoftSRV, we perform these evaluations without any particular specialization of the framework to each domain. We find that SoftSRV significantly improves upon hard-prompting baselines, generating data with superior fine-tuning performance and that better matches the target distribution according to the MAUVE similarity metric.
GIST: Greedy Independent Set Thresholding for Diverse Data Summarization
May 29, 2024

We propose a novel subset selection task called min-distance diverse data summarization ($\textsf{MDDS}$), which has a wide variety of applications in machine learning, e.g., data sampling and feature selection. Given a set of points in a metric space, the goal is to maximize an objective that combines the total utility of the points and a diversity term that captures the minimum distance between any pair of selected points, subject to the constraint $|S| \le k$. For example, the points may correspond to training examples in a data sampling problem, e.g., learned embeddings of images extracted from a deep neural network. This work presents the $\texttt{GIST}$ algorithm, which achieves a $\frac{2}{3}$-approximation guarantee for $\textsf{MDDS}$ by approximating a series of maximum independent set problems with a bicriteria greedy algorithm. We also prove a complementary $(\frac{2}{3}+\varepsilon)$-hardness of approximation, for any $\varepsilon > 0$. Finally, we provide an empirical study that demonstrates $\texttt{GIST}$ outperforms existing methods for $\textsf{MDDS}$ on synthetic data, and also for a real-world image classification experiment the studies single-shot subset selection for ImageNet.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
Two-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023


Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
Leveraging Importance Weights in Subset Selection
Jan 28, 2023



We present a subset selection algorithm designed to work with arbitrary model families in a practical batch setting. In such a setting, an algorithm can sample examples one at a time but, in order to limit overhead costs, is only able to update its state (i.e. further train model weights) once a large enough batch of examples is selected. Our algorithm, IWeS, selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. IWeS admits significant performance improvement compared to other subset selection algorithms for seven publicly available datasets. Additionally, it is competitive in an active learning setting, where the label information is not available at selection time. We also provide an initial theoretical analysis to support our importance weighting approach, proving generalization and sampling rate bounds.
Batch Active Learning at Scale
Jul 29, 2021
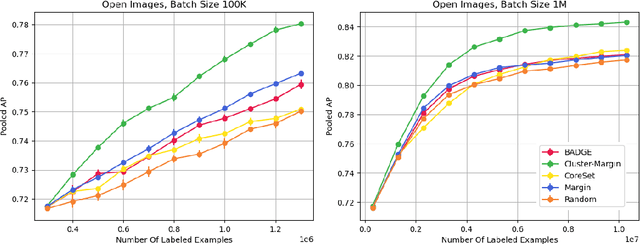
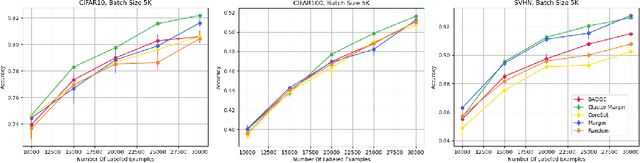
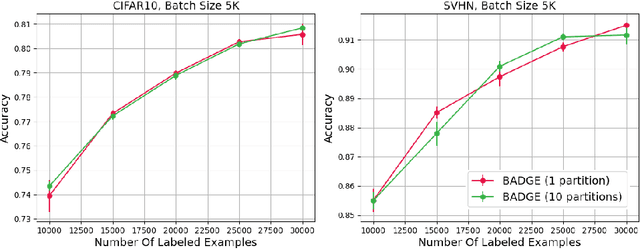
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Adaptive Region-Based Active Learning
Feb 18, 2020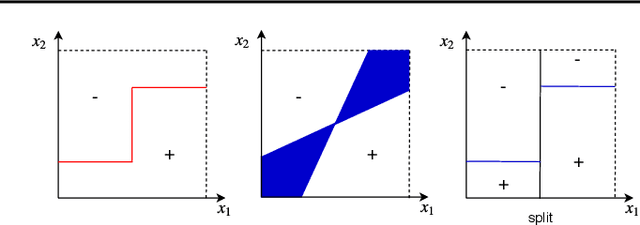
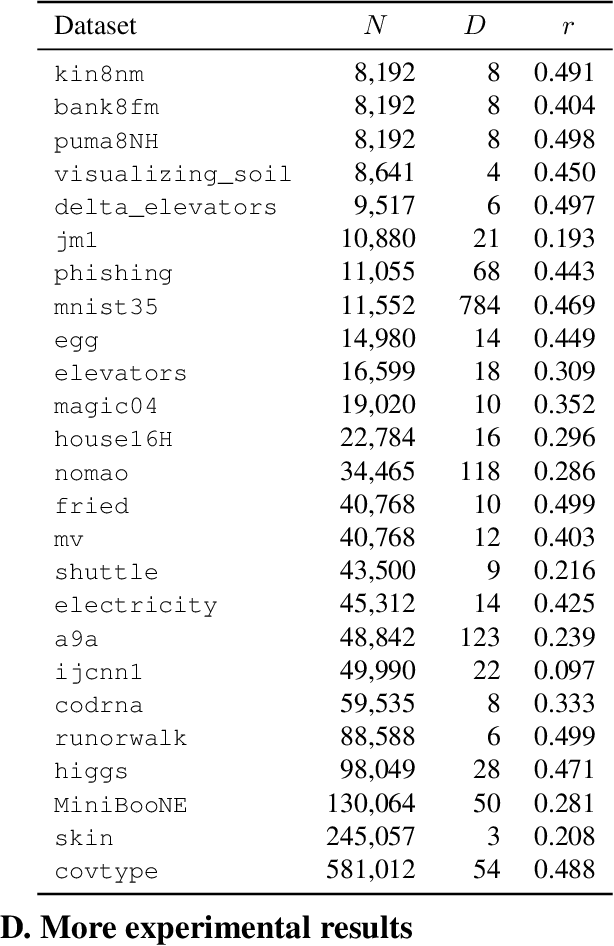
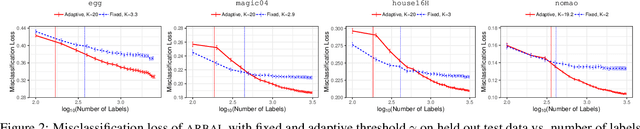
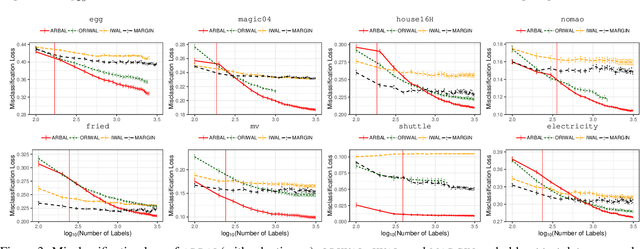
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, both phases actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
Jun 18, 2018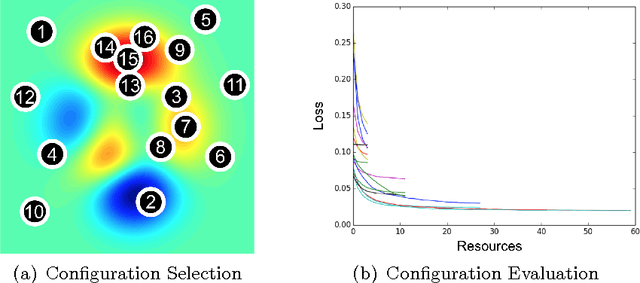

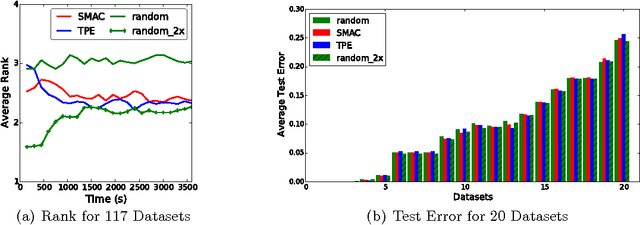

Performance of machine learning algorithms depends critically on identifying a good set of hyperparameters. While recent approaches use Bayesian optimization to adaptively select configurations, we focus on speeding up random search through adaptive resource allocation and early-stopping. We formulate hyperparameter optimization as a pure-exploration non-stochastic infinite-armed bandit problem where a predefined resource like iterations, data samples, or features is allocated to randomly sampled configurations. We introduce a novel algorithm, Hyperband, for this framework and analyze its theoretical properties, providing several desirable guarantees. Furthermore, we compare Hyperband with popular Bayesian optimization methods on a suite of hyperparameter optimization problems. We observe that Hyperband can provide over an order-of-magnitude speedup over our competitor set on a variety of deep-learning and kernel-based learning problems.
* Changes: - Updated to JMLR version
Online Learning with Abstention
Feb 27, 2018



We present an extensive study of the key problem of online learning where algorithms are allowed to abstain from making predictions. In the adversarial setting, we show how existing online algorithms and guarantees can be adapted to this problem. In the stochastic setting, we first point out a bias problem that limits the straightforward extension of algorithms such as UCB-N to time-varying feedback graphs, as needed in this context. Next, we give a new algorithm, UCB-GT, that exploits historical data and is adapted to time-varying feedback graphs. We show that this algorithm benefits from more favorable regret guarantees than a possible, but limited, extension of UCB-N. We further report the results of a series of experiments demonstrating that UCB-GT largely outperforms that extension of UCB-N, as well as more standard baselines.