 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaViT: Dual Attention Vision Transformers
Apr 07, 2022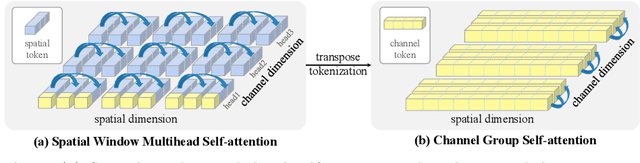
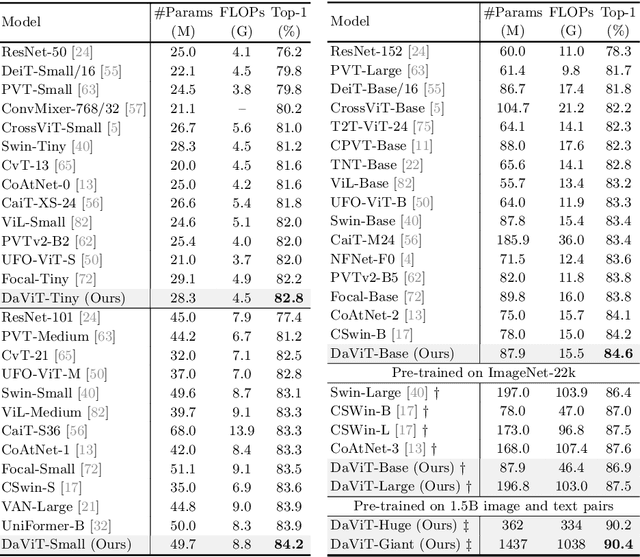
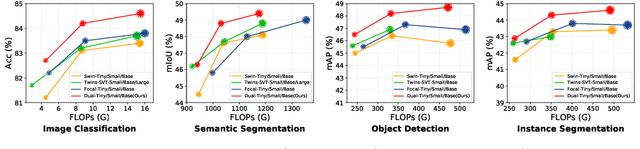
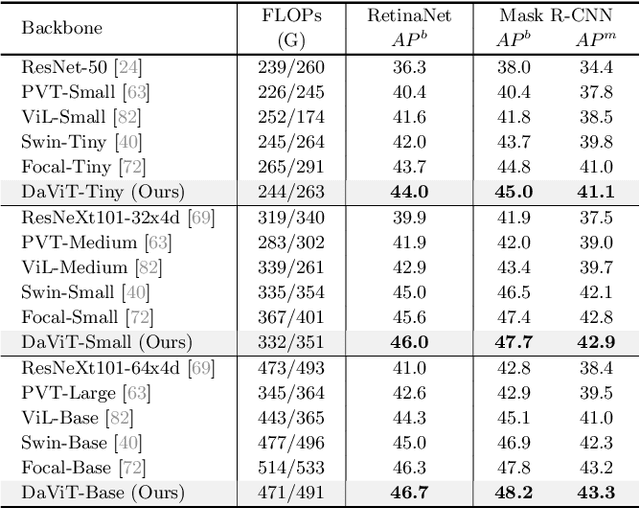
In this work, we introduce Dual Attention Vision Transformers (DaViT), a simple yet effective vision transformer architecture that is able to capture global context while maintaining computational efficiency. We propose approaching the problem from an orthogonal angle: exploiting self-attention mechanisms with both "spatial tokens" and "channel tokens". With spatial tokens, the spatial dimension defines the token scope, and the channel dimension defines the token feature dimension. With channel tokens, we have the inverse: the channel dimension defines the token scope, and the spatial dimension defines the token feature dimension. We further group tokens along the sequence direction for both spatial and channel tokens to maintain the linear complexity of the entire model. We show that these two self-attentions complement each other: (i) since each channel token contains an abstract representation of the entire image, the channel attention naturally captures global interactions and representations by taking all spatial positions into account when computing attention scores between channels; (ii) the spatial attention refines the local representations by performing fine-grained interactions across spatial locations, which in turn helps the global information modeling in channel attention. Extensive experiments show our DaViT achieves state-of-the-art performance on four different tasks with efficient computations. Without extra data, DaViT-Tiny, DaViT-Small, and DaViT-Base achieve 82.8%, 84.2%, and 84.6% top-1 accuracy on ImageNet-1K with 28.3M, 49.7M, and 87.9M parameters, respectively. When we further scale up DaViT with 1.5B weakly supervised image and text pairs, DaViT-Gaint reaches 90.4% top-1 accuracy on ImageNet-1K. Code is available at https://github.com/dingmyu/davit.
Unified Contrastive Learning in Image-Text-Label Space
Apr 07, 2022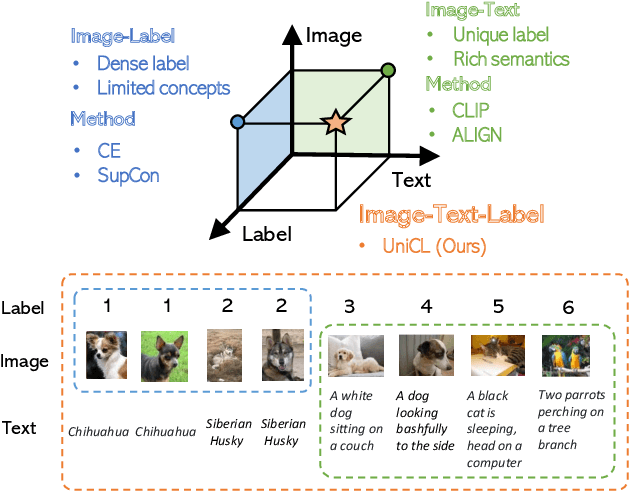
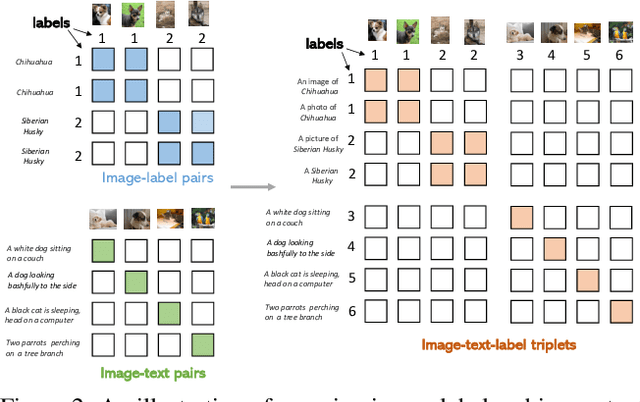

Visual recognition is recently learned via either supervised learning on human-annotated image-label data or language-image contrastive learning with webly-crawled image-text pairs. While supervised learning may result in a more discriminative representation, language-image pretraining shows unprecedented zero-shot recognition capability, largely due to the different properties of data sources and learning objectives. In this work, we introduce a new formulation by combining the two data sources into a common image-text-label space. In this space, we propose a new learning paradigm, called Unified Contrastive Learning (UniCL) with a single learning objective to seamlessly prompt the synergy of two data types. Extensive experiments show that our UniCL is an effective way of learning semantically rich yet discriminative representations, universally for image recognition in zero-shot, linear-probe, fully finetuning and transfer learning scenarios. Particularly, it attains gains up to 9.2% and 14.5% in average on zero-shot recognition benchmarks over the language-image contrastive learning and supervised learning methods, respectively. In linear probe setting, it also boosts the performance over the two methods by 7.3% and 3.4%, respectively. Our study also indicates that UniCL stand-alone is a good learner on pure image-label data, rivaling the supervised learning methods across three image classification datasets and two types of vision backbones, ResNet and Swin Transformer. Code is available at https://github.com/microsoft/UniCL.
Large-Scale Pre-training for Person Re-identification with Noisy Labels
Apr 04, 2022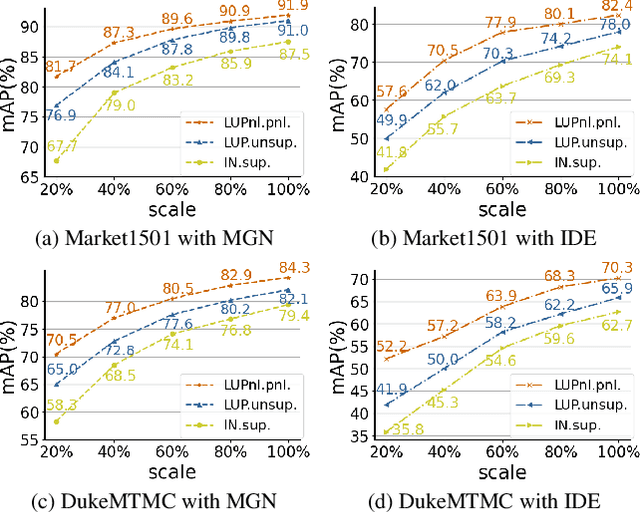
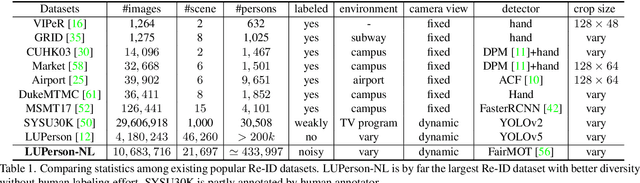
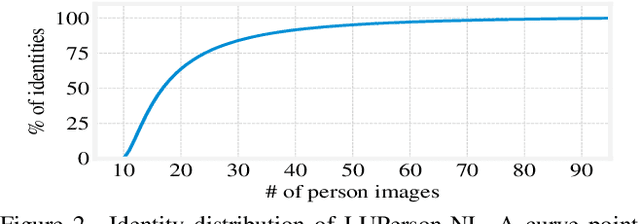
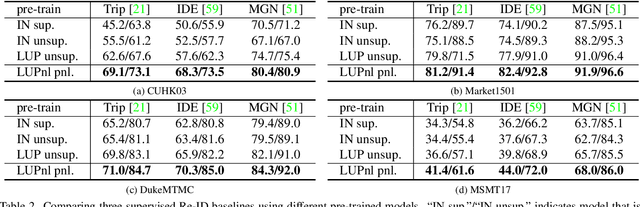
This paper aims to address the problem of pre-training for person re-identification (Re-ID) with noisy labels. To setup the pre-training task, we apply a simple online multi-object tracking system on raw videos of an existing unlabeled Re-ID dataset "LUPerson" nd build the Noisy Labeled variant called "LUPerson-NL". Since theses ID labels automatically derived from tracklets inevitably contain noises, we develop a large-scale Pre-training framework utilizing Noisy Labels (PNL), which consists of three learning modules: supervised Re-ID learning, prototype-based contrastive learning, and label-guided contrastive learning. In principle, joint learning of these three modules not only clusters similar examples to one prototype, but also rectifies noisy labels based on the prototype assignment. We demonstrate that learning directly from raw videos is a promising alternative for pre-training, which utilizes spatial and temporal correlations as weak supervision. This simple pre-training task provides a scalable way to learn SOTA Re-ID representations from scratch on "LUPerson-NL" without bells and whistles. For example, by applying on the same supervised Re-ID method MGN, our pre-trained model improves the mAP over the unsupervised pre-training counterpart by 5.7%, 2.2%, 2.3% on CUHK03, DukeMTMC, and MSMT17 respectively. Under the small-scale or few-shot setting, the performance gain is even more significant, suggesting a better transferability of the learned representation. Code is available at https://github.com/DengpanFu/LUPerson-NL
CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks
Jan 15, 2022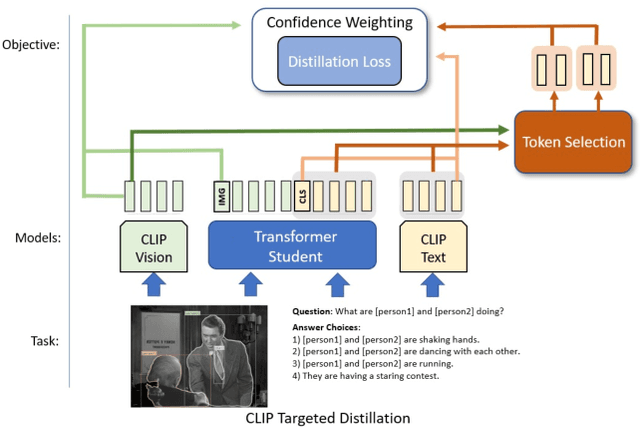
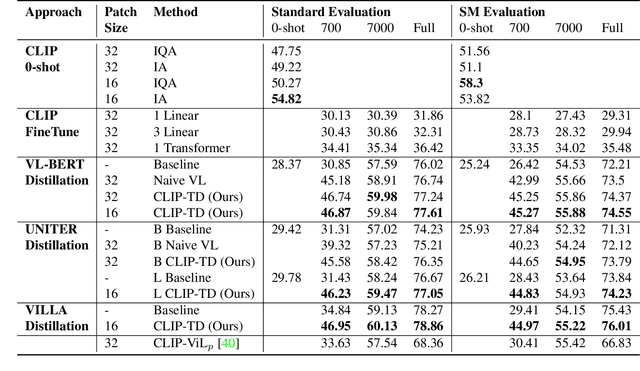
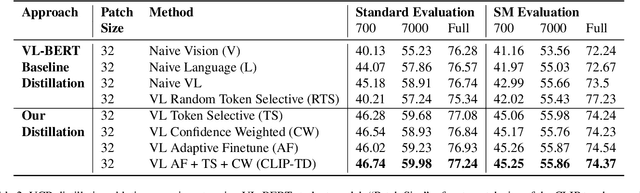

Contrastive language-image pretraining (CLIP) links vision and language modalities into a unified embedding space, yielding the tremendous potential for vision-language (VL) tasks. While early concurrent works have begun to study this potential on a subset of tasks, important questions remain: 1) What is the benefit of CLIP on unstudied VL tasks? 2) Does CLIP provide benefit in low-shot or domain-shifted scenarios? 3) Can CLIP improve existing approaches without impacting inference or pretraining complexity? In this work, we seek to answer these questions through two key contributions. First, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data availability constraints and conditions of domain shift. Second, we propose an approach, named CLIP Targeted Distillation (CLIP-TD), to intelligently distill knowledge from CLIP into existing architectures using a dynamically weighted objective applied to adaptively selected tokens per instance. Experiments demonstrate that our proposed CLIP-TD leads to exceptional gains in the low-shot (up to 51.9%) and domain-shifted (up to 71.3%) conditions of VCR, while simultaneously improving performance under standard fully-supervised conditions (up to 2%), achieving state-of-art performance on VCR compared to other single models that are pretrained with image-text data only. On SNLI-VE, CLIP-TD produces significant gains in low-shot conditions (up to 6.6%) as well as fully supervised (up to 3%). On VQA, CLIP-TD provides improvement in low-shot (up to 9%), and in fully-supervised (up to 1.3%). Finally, CLIP-TD outperforms concurrent works utilizing CLIP for finetuning, as well as baseline naive distillation approaches. Code will be made available.
Online Multi-Object Tracking with Unsupervised Re-Identification Learning and Occlusion Estimation
Jan 04, 2022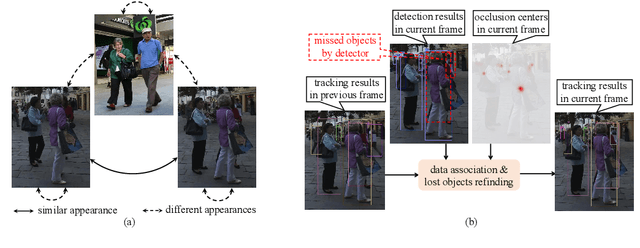

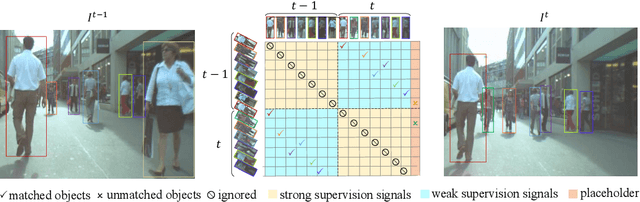

Occlusion between different objects is a typical challenge in Multi-Object Tracking (MOT), which often leads to inferior tracking results due to the missing detected objects. The common practice in multi-object tracking is re-identifying the missed objects after their reappearance. Though tracking performance can be boosted by the re-identification, the annotation of identity is required to train the model. In addition, such practice of re-identification still can not track those highly occluded objects when they are missed by the detector. In this paper, we focus on online multi-object tracking and design two novel modules, the unsupervised re-identification learning module and the occlusion estimation module, to handle these problems. Specifically, the proposed unsupervised re-identification learning module does not require any (pseudo) identity information nor suffer from the scalability issue. The proposed occlusion estimation module tries to predict the locations where occlusions happen, which are used to estimate the positions of missed objects by the detector. Our study shows that, when applied to state-of-the-art MOT methods, the proposed unsupervised re-identification learning is comparable to supervised re-identification learning, and the tracking performance is further improved by the proposed occlusion estimation module.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021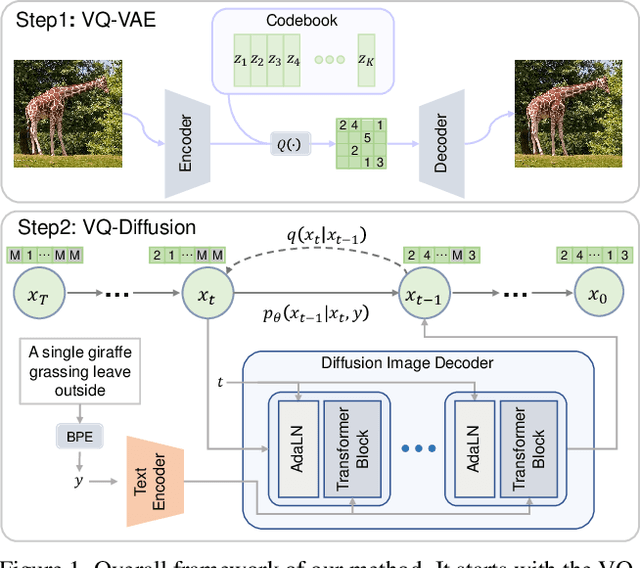
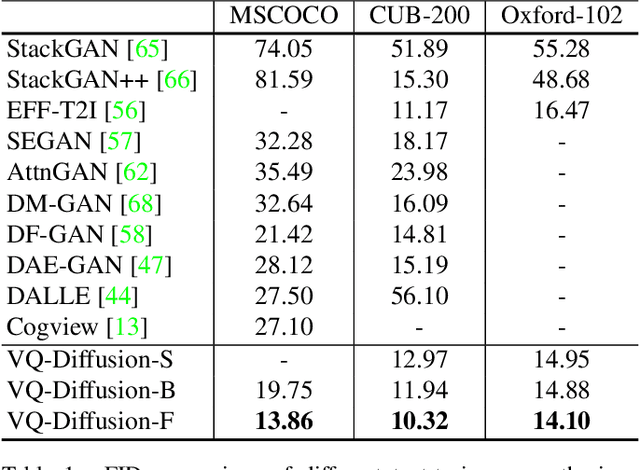

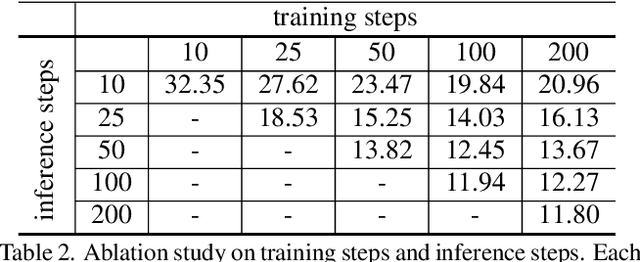
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
RegionCLIP: Region-based Language-Image Pretraining
Dec 16, 2021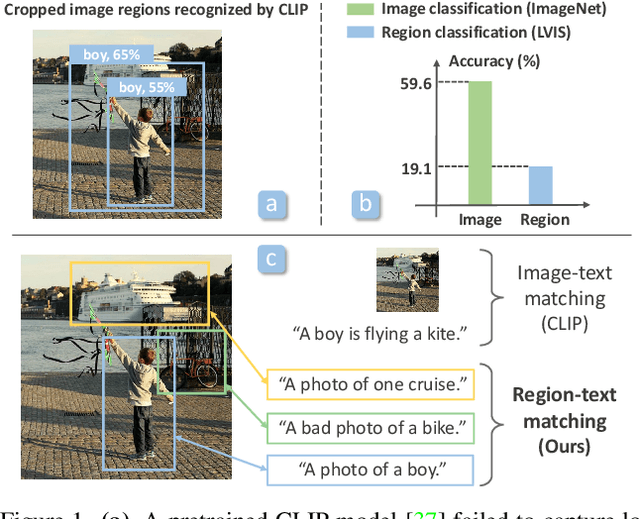
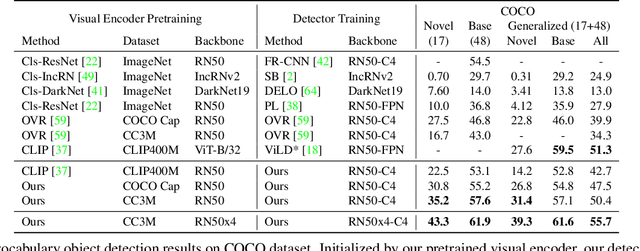
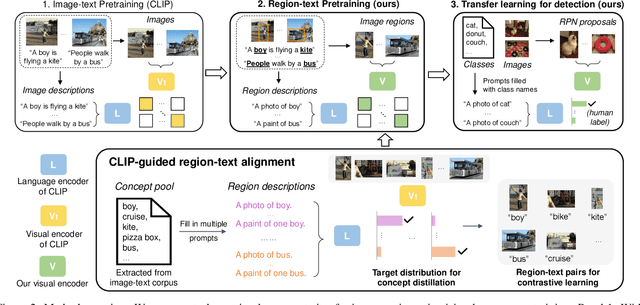
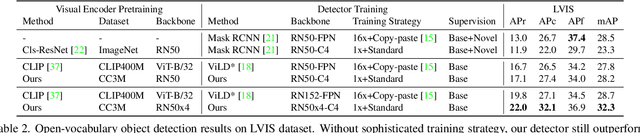
Contrastive language-image pretraining (CLIP) using image-text pairs has achieved impressive results on image classification in both zero-shot and transfer learning settings. However, we show that directly applying such models to recognize image regions for object detection leads to poor performance due to a domain shift: CLIP was trained to match an image as a whole to a text description, without capturing the fine-grained alignment between image regions and text spans. To mitigate this issue, we propose a new method called RegionCLIP that significantly extends CLIP to learn region-level visual representations, thus enabling fine-grained alignment between image regions and textual concepts. Our method leverages a CLIP model to match image regions with template captions and then pretrains our model to align these region-text pairs in the feature space. When transferring our pretrained model to the open-vocabulary object detection tasks, our method significantly outperforms the state of the art by 3.8 AP50 and 2.2 AP for novel categories on COCO and LVIS datasets, respectively. Moreoever, the learned region representations support zero-shot inference for object detection, showing promising results on both COCO and LVIS datasets. Our code is available at https://github.com/microsoft/RegionCLIP.
HairCLIP: Design Your Hair by Text and Reference Image
Dec 09, 2021
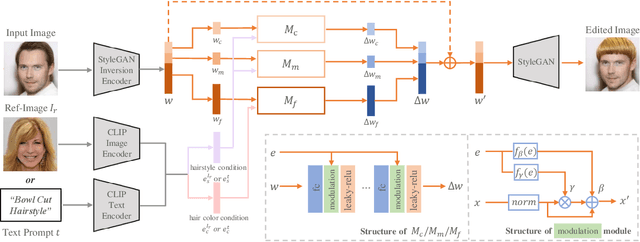
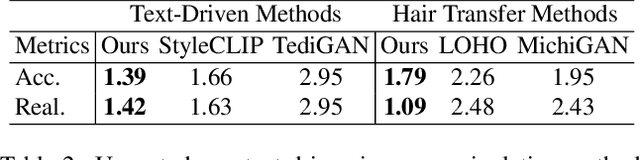

Hair editing is an interesting and challenging problem in computer vision and graphics. Many existing methods require well-drawn sketches or masks as conditional inputs for editing, however these interactions are neither straightforward nor efficient. In order to free users from the tedious interaction process, this paper proposes a new hair editing interaction mode, which enables manipulating hair attributes individually or jointly based on the texts or reference images provided by users. For this purpose, we encode the image and text conditions in a shared embedding space and propose a unified hair editing framework by leveraging the powerful image text representation capability of the Contrastive Language-Image Pre-Training (CLIP) model. With the carefully designed network structures and loss functions, our framework can perform high-quality hair editing in a disentangled manner. Extensive experiments demonstrate the superiority of our approach in terms of manipulation accuracy, visual realism of editing results, and irrelevant attribute preservation. Project repo is https://github.com/wty-ustc/HairCLIP.
Grounded Language-Image Pre-training
Dec 07, 2021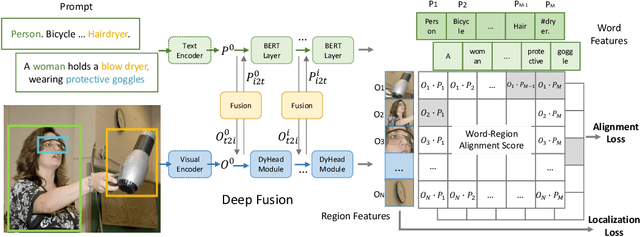
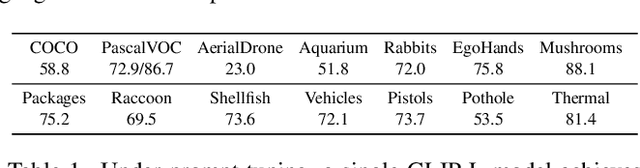
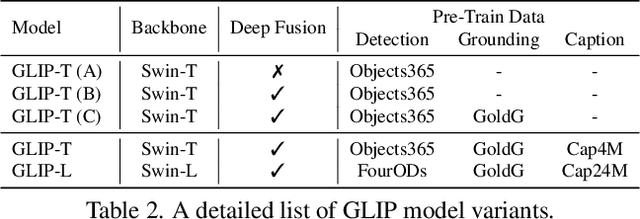
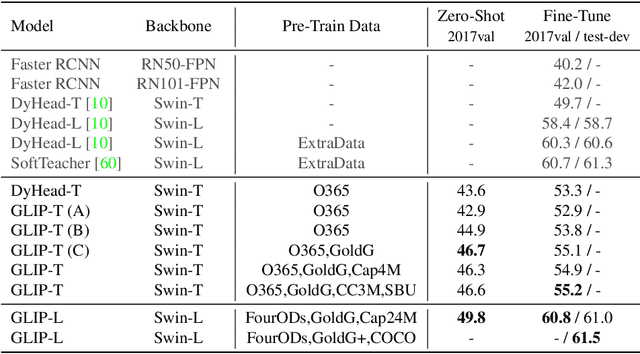
This paper presents a grounded language-image pre-training (GLIP) model for learning object-level, language-aware, and semantic-rich visual representations. GLIP unifies object detection and phrase grounding for pre-training. The unification brings two benefits: 1) it allows GLIP to learn from both detection and grounding data to improve both tasks and bootstrap a good grounding model; 2) GLIP can leverage massive image-text pairs by generating grounding boxes in a self-training fashion, making the learned representation semantic-rich. In our experiments, we pre-train GLIP on 27M grounding data, including 3M human-annotated and 24M web-crawled image-text pairs. The learned representations demonstrate strong zero-shot and few-shot transferability to various object-level recognition tasks. 1) When directly evaluated on COCO and LVIS (without seeing any images in COCO during pre-training), GLIP achieves 49.8 AP and 26.9 AP, respectively, surpassing many supervised baselines. 2) After fine-tuned on COCO, GLIP achieves 60.8 AP on val and 61.5 AP on test-dev, surpassing prior SoTA. 3) When transferred to 13 downstream object detection tasks, a 1-shot GLIP rivals with a fully-supervised Dynamic Head. Code will be released at https://github.com/microsoft/GLIP.
General Facial Representation Learning in a Visual-Linguistic Manner
Dec 06, 2021
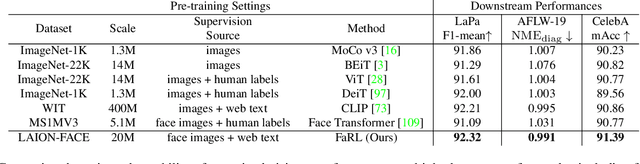
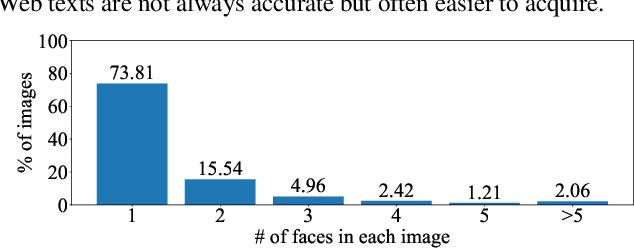

How to learn a universal facial representation that boosts all face analysis tasks? This paper takes one step toward this goal. In this paper, we study the transfer performance of pre-trained models on face analysis tasks and introduce a framework, called FaRL, for general Facial Representation Learning in a visual-linguistic manner. On one hand, the framework involves a contrastive loss to learn high-level semantic meaning from image-text pairs. On the other hand, we propose exploring low-level information simultaneously to further enhance the face representation, by adding a masked image modeling. We perform pre-training on LAION-FACE, a dataset containing large amount of face image-text pairs, and evaluate the representation capability on multiple downstream tasks. We show that FaRL achieves better transfer performance compared with previous pre-trained models. We also verify its superiority in the low-data regime. More importantly, our model surpasses the state-of-the-art methods on face analysis tasks including face parsing and face alignment.