 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022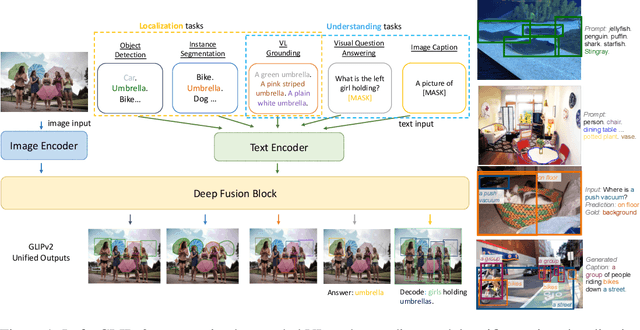
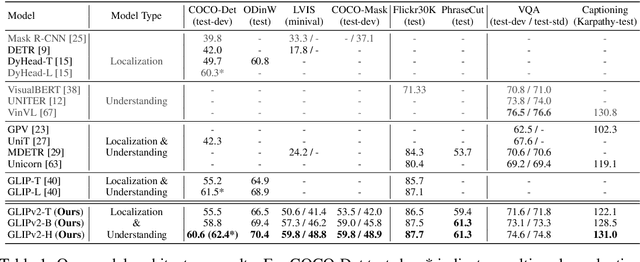
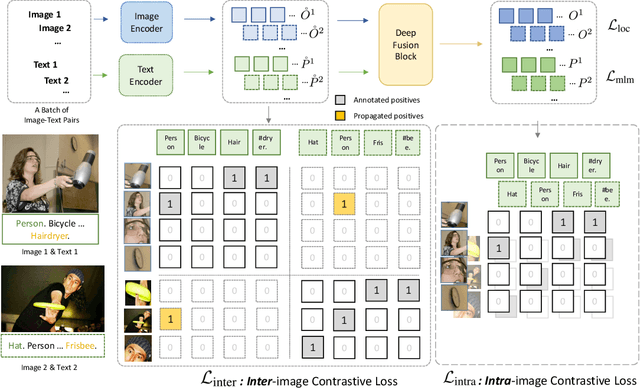
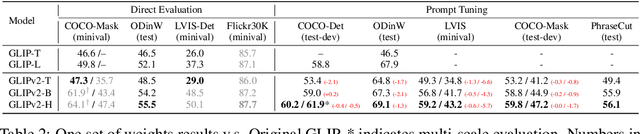
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
Detection Hub: Unifying Object Detection Datasets via Query Adaptation on Language Embedding
Jun 07, 2022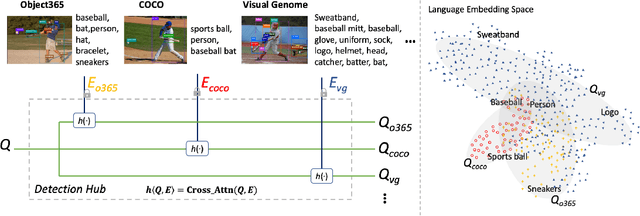

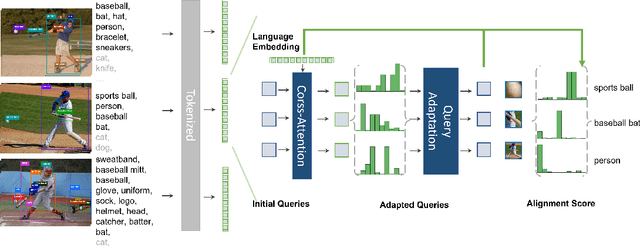
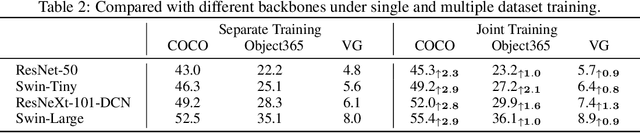
Leveraging large-scale data can introduce performance gains on many computer vision tasks. Unfortunately, this does not happen in object detection when training a single model under multiple datasets together. We observe two main obstacles: taxonomy difference and bounding box annotation inconsistency, which introduces domain gaps in different datasets that prevents us from joint training. In this paper, we show that these two challenges can be effectively addressed by simply adapting object queries on language embedding of categories per dataset. We design a detection hub to dynamically adapt queries on category embedding based on the different distributions of datasets. Unlike previous methods attempted to learn a joint embedding for all datasets, our adaptation method can utilize the language embedding as semantic centers for common categories, while learning the semantic bias towards specific categories belonging to different datasets to handle annotation differences and make up the domain gaps. These novel improvements enable us to end-to-end train a single detector on multiple datasets simultaneously to fully take their advantages. Further experiments on joint training on multiple datasets demonstrate the significant performance gains over separate individual fine-tuned detectors.
Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

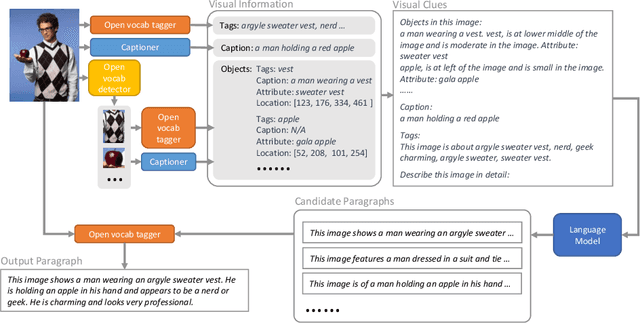
People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
Jun 02, 2022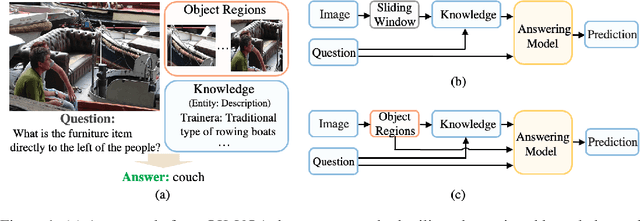
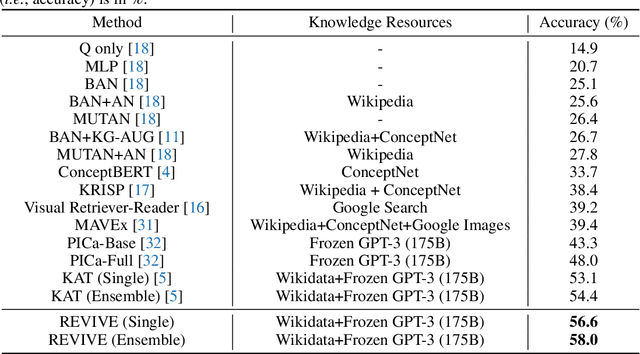
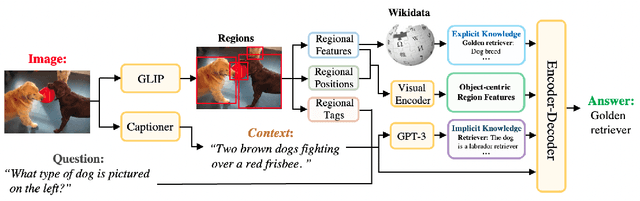

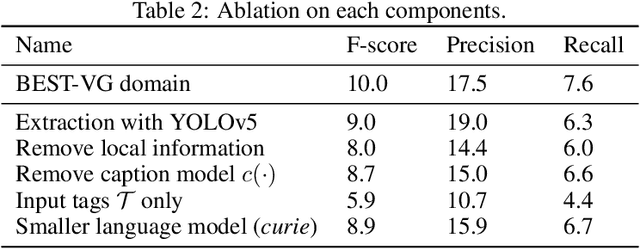
This paper revisits visual representation in knowledge-based visual question answering (VQA) and demonstrates that using regional information in a better way can significantly improve the performance. While visual representation is extensively studied in traditional VQA, it is under-explored in knowledge-based VQA even though these two tasks share the common spirit, i.e., rely on visual input to answer the question. Specifically, we observe that in most state-of-the-art knowledge-based VQA methods: 1) visual features are extracted either from the whole image or in a sliding window manner for retrieving knowledge, and the important relationship within/among object regions is neglected; 2) visual features are not well utilized in the final answering model, which is counter-intuitive to some extent. Based on these observations, we propose a new knowledge-based VQA method REVIVE, which tries to utilize the explicit information of object regions not only in the knowledge retrieval stage but also in the answering model. The key motivation is that object regions and inherent relationships are important for knowledge-based VQA. We perform extensive experiments on the standard OK-VQA dataset and achieve new state-of-the-art performance, i.e., 58.0% accuracy, surpassing previous state-of-the-art method by a large margin (+3.6%). We also conduct detailed analysis and show the necessity of regional information in different framework components for knowledge-based VQA.
Reduce Information Loss in Transformers for Pluralistic Image Inpainting
May 15, 2022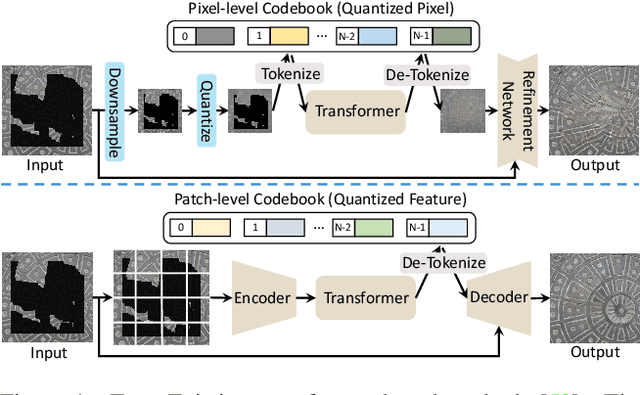
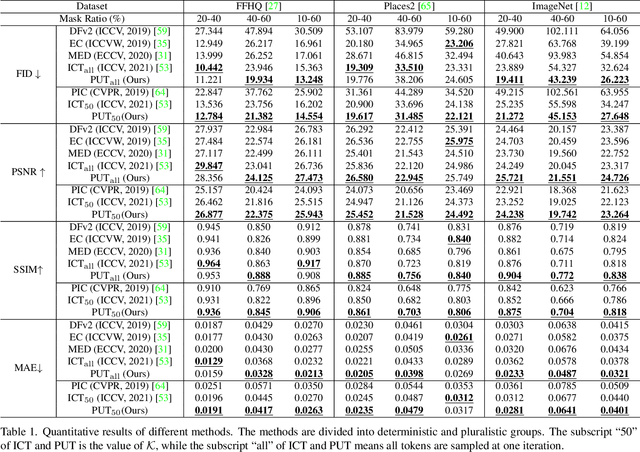
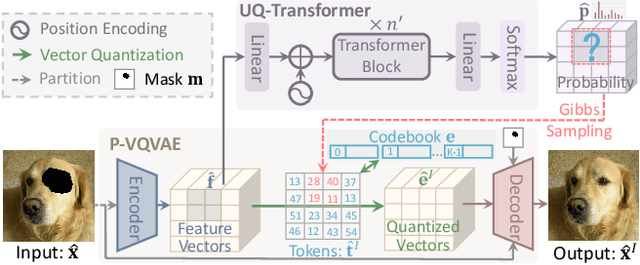

Transformers have achieved great success in pluralistic image inpainting recently. However, we find existing transformer based solutions regard each pixel as a token, thus suffer from information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration, incurring information loss and extra misalignment for the boundaries of masked regions. 2) They quantize $256^3$ RGB pixels to a small number (such as 512) of quantized pixels. The indices of quantized pixels are used as tokens for the inputs and prediction targets of transformer. Although an extra CNN network is used to upsample and refine the low-resolution results, it is difficult to retrieve the lost information back.To keep input information as much as possible, we propose a new transformer based framework "PUT". Specifically, to avoid input downsampling while maintaining the computation efficiency, we design a patch-based auto-encoder P-VQVAE, where the encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by quantization, an Un-Quantized Transformer (UQ-Transformer) is applied, which directly takes the features from P-VQVAE encoder as input without quantization and regards the quantized tokens only as prediction targets. Extensive experiments show that PUT greatly outperforms state-of-the-art methods on image fidelity, especially for large masked regions and complex large-scale datasets. Code is available at https://github.com/liuqk3/PUT
i-Code: An Integrative and Composable Multimodal Learning Framework
May 05, 2022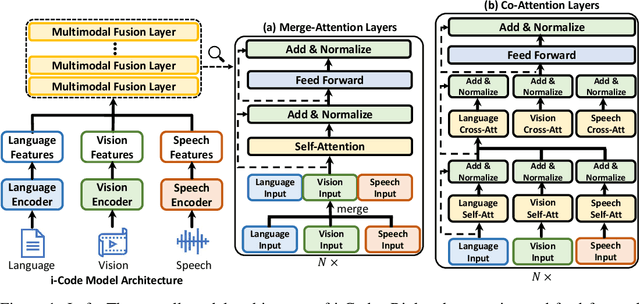
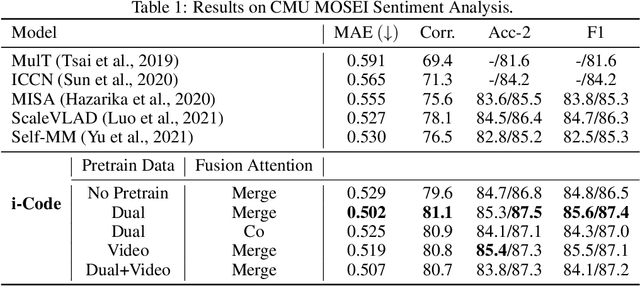
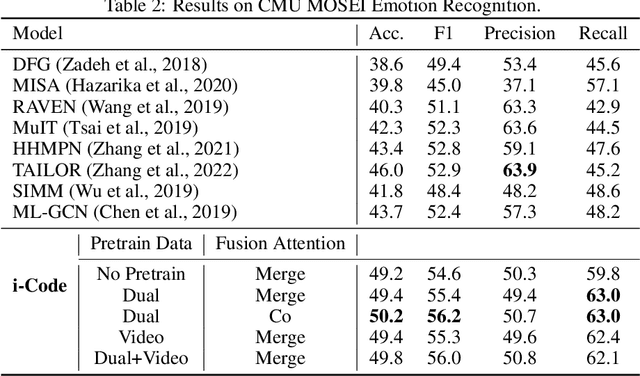

Human intelligence is multimodal; we integrate visual, linguistic, and acoustic signals to maintain a holistic worldview. Most current pretraining methods, however, are limited to one or two modalities. We present i-Code, a self-supervised pretraining framework where users may flexibly combine the modalities of vision, speech, and language into unified and general-purpose vector representations. In this framework, data from each modality are first given to pretrained single-modality encoders. The encoder outputs are then integrated with a multimodal fusion network, which uses novel attention mechanisms and other architectural innovations to effectively combine information from the different modalities. The entire system is pretrained end-to-end with new objectives including masked modality unit modeling and cross-modality contrastive learning. Unlike previous research using only video for pretraining, the i-Code framework can dynamically process single, dual, and triple-modality data during training and inference, flexibly projecting different combinations of modalities into a single representation space. Experimental results demonstrate how i-Code can outperform state-of-the-art techniques on five video understanding tasks and the GLUE NLP benchmark, improving by as much as 11% and demonstrating the power of integrative multimodal pretraining.
Multimodal Adaptive Distillation for Leveraging Unimodal Encoders for Vision-Language Tasks
Apr 28, 2022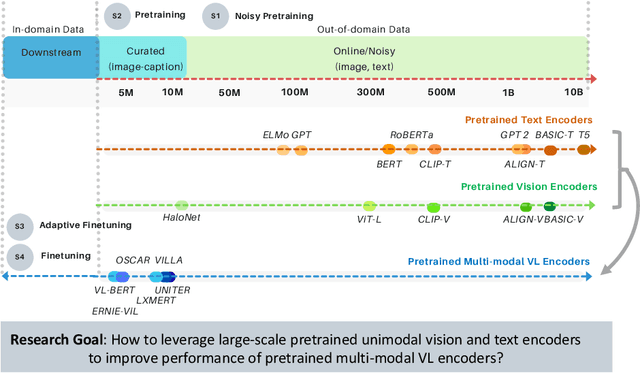
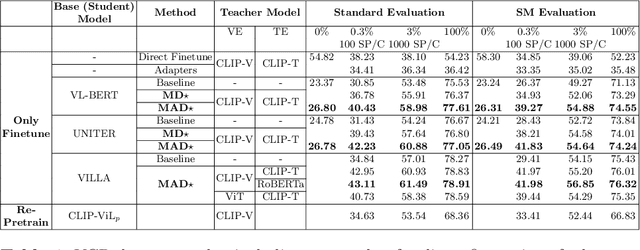
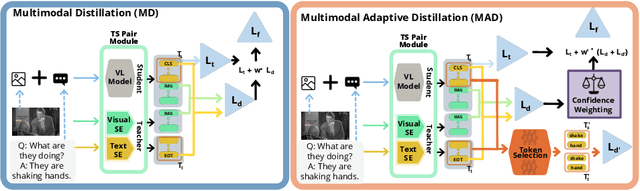
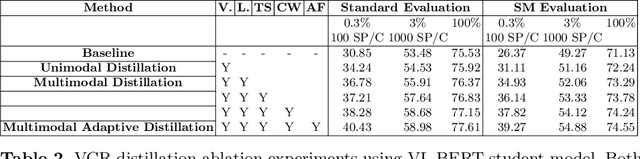
Cross-modal encoders for vision-language (VL) tasks are often pretrained with carefully curated vision-language datasets. While these datasets reach an order of 10 million samples, the labor cost is prohibitive to scale further. Conversely, unimodal encoders are pretrained with simpler annotations that are less cost-prohibitive, achieving scales of hundreds of millions to billions. As a result, unimodal encoders have achieved state-of-art (SOTA) on many downstream tasks. However, challenges remain when applying to VL tasks. The pretraining data is not optimal for cross-modal architectures and requires heavy computational resources. In addition, unimodal architectures lack cross-modal interactions that have demonstrated significant benefits for VL tasks. Therefore, how to best leverage pretrained unimodal encoders for VL tasks is still an area of active research. In this work, we propose a method to leverage unimodal vision and text encoders for VL tasks that augment existing VL approaches while conserving computational complexity. Specifically, we propose Multimodal Adaptive Distillation (MAD), which adaptively distills useful knowledge from pretrained encoders to cross-modal VL encoders. Second, to better capture nuanced impacts on VL task performance, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data constraints and conditions of domain shift. Experiments demonstrate that MAD leads to consistent gains in the low-shot, domain-shifted, and fully-supervised conditions on VCR, SNLI-VE, and VQA, achieving SOTA performance on VCR compared to other single models pretrained with image-text data. Finally, MAD outperforms concurrent works utilizing pretrained vision encoder from CLIP. Code will be made available.
Residual Mixture of Experts
Apr 20, 2022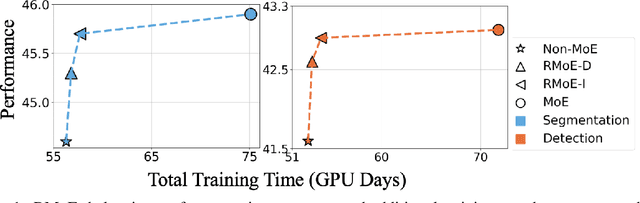
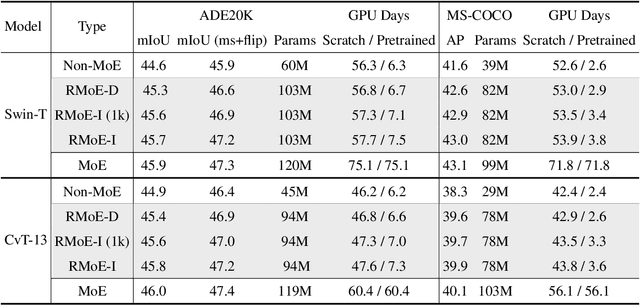
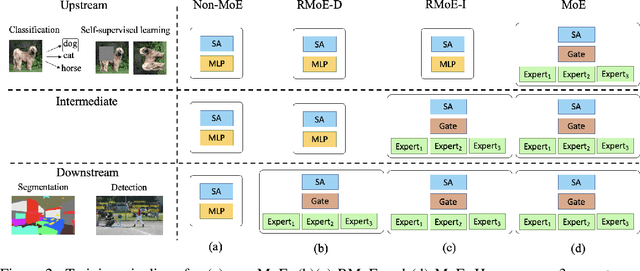
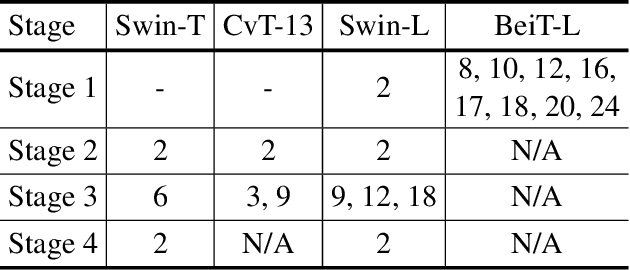
Mixture of Experts (MoE) is able to scale up vision transformers effectively. However, it requires prohibiting computation resources to train a large MoE transformer. In this paper, we propose Residual Mixture of Experts (RMoE), an efficient training pipeline for MoE vision transformers on downstream tasks, such as segmentation and detection. RMoE achieves comparable results with the upper-bound MoE training, while only introducing minor additional training cost than the lower-bound non-MoE training pipelines. The efficiency is supported by our key observation: the weights of an MoE transformer can be factored into an input-independent core and an input-dependent residual. Compared with the weight core, the weight residual can be efficiently trained with much less computation resource, e.g., finetuning on the downstream data. We show that, compared with the current MoE training pipeline, we get comparable results while saving over 30% training cost. When compared with state-of-the-art non- MoE transformers, such as Swin-T / CvT-13 / Swin-L, we get +1.1 / 0.9 / 1.0 mIoU gain on ADE20K segmentation and +1.4 / 1.6 / 0.6 AP gain on MS-COCO object detection task with less than 3% additional training cost.
K-LITE: Learning Transferable Visual Models with External Knowledge
Apr 20, 2022
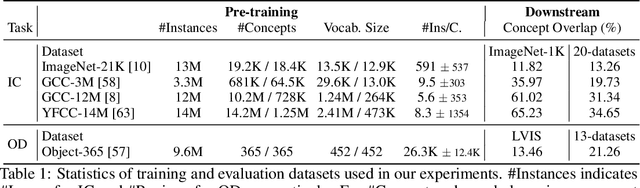
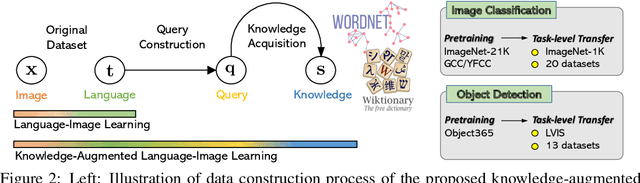
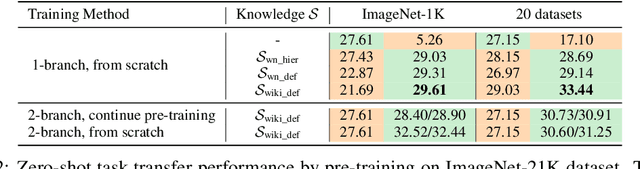
Recent state-of-the-art computer vision systems are trained from natural language supervision, ranging from simple object category names to descriptive captions. This free form of supervision ensures high generality and usability of the learned visual models, based on extensive heuristics on data collection to cover as many visual concepts as possible. Alternatively, learning with external knowledge about images is a promising way which leverages a much more structured source of supervision. In this paper, we propose K-LITE (Knowledge-augmented Language-Image Training and Evaluation), a simple strategy to leverage external knowledge to build transferable visual systems: In training, it enriches entities in natural language with WordNet and Wiktionary knowledge, leading to an efficient and scalable approach to learning image representations that can understand both visual concepts and their knowledge; In evaluation, the natural language is also augmented with external knowledge and then used to reference learned visual concepts (or describe new ones) to enable zero-shot and few-shot transfer of the pre-trained models. We study the performance of K-LITE on two important computer vision problems, image classification and object detection, benchmarking on 20 and 13 different existing datasets, respectively. The proposed knowledge-augmented models show significant improvement in transfer learning performance over existing methods.
MiniViT: Compressing Vision Transformers with Weight Multiplexing
Apr 14, 2022



Vision Transformer (ViT) models have recently drawn much attention in computer vision due to their high model capability. However, ViT models suffer from huge number of parameters, restricting their applicability on devices with limited memory. To alleviate this problem, we propose MiniViT, a new compression framework, which achieves parameter reduction in vision transformers while retaining the same performance. The central idea of MiniViT is to multiplex the weights of consecutive transformer blocks. More specifically, we make the weights shared across layers, while imposing a transformation on the weights to increase diversity. Weight distillation over self-attention is also applied to transfer knowledge from large-scale ViT models to weight-multiplexed compact models. Comprehensive experiments demonstrate the efficacy of MiniViT, showing that it can reduce the size of the pre-trained Swin-B transformer by 48\%, while achieving an increase of 1.0\% in Top-1 accuracy on ImageNet. Moreover, using a single-layer of parameters, MiniViT is able to compress DeiT-B by 9.7 times from 86M to 9M parameters, without seriously compromising the performance. Finally, we verify the transferability of MiniViT by reporting its performance on downstream benchmarks. Code and models are available at here.