 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Spark Transformer: Reactivating Sparsity in FFN and Attention
Jun 07, 2025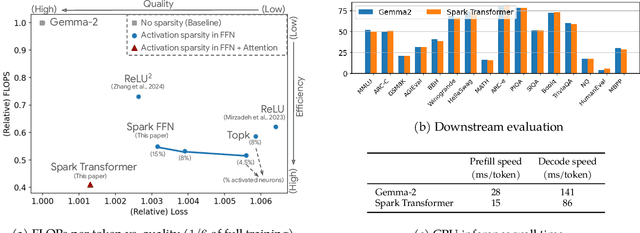
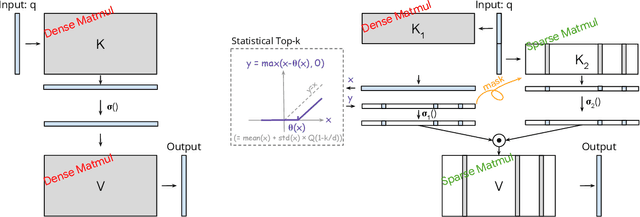
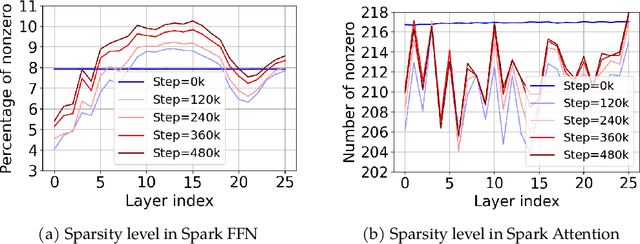
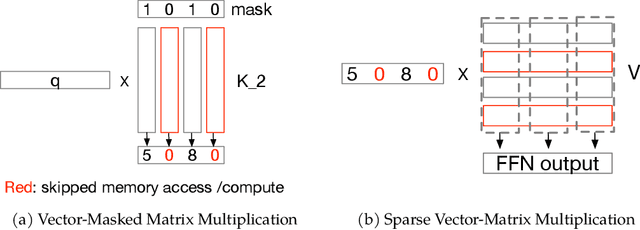
The discovery of the lazy neuron phenomenon in trained Transformers, where the vast majority of neurons in their feed-forward networks (FFN) are inactive for each token, has spurred tremendous interests in activation sparsity for enhancing large model efficiency. While notable progress has been made in translating such sparsity to wall-time benefits, modern Transformers have moved away from the ReLU activation function crucial to this phenomenon. Existing efforts on re-introducing activation sparsity often degrade model quality, increase parameter count, complicate or slow down training. Sparse attention, the application of sparse activation to the attention mechanism, often faces similar challenges. This paper introduces the Spark Transformer, a novel architecture that achieves a high level of activation sparsity in both FFN and the attention mechanism while maintaining model quality, parameter count, and standard training procedures. Our method realizes sparsity via top-k masking for explicit control over sparsity level. Crucially, we introduce statistical top-k, a hardware-accelerator-friendly, linear-time approximate algorithm that avoids costly sorting and mitigates significant training slowdown from standard top-$k$ operators. Furthermore, Spark Transformer reallocates existing FFN parameters and attention key embeddings to form a low-cost predictor for identifying activated entries. This design not only mitigates quality loss from enforced sparsity, but also enhances wall-time benefit. Pretrained with the Gemma-2 recipe, Spark Transformer demonstrates competitive performance on standard benchmarks while exhibiting significant sparsity: only 8% of FFN neurons are activated, and each token attends to a maximum of 256 tokens. This sparsity translates to a 2.5x reduction in FLOPs, leading to decoding wall-time speedups of up to 1.79x on CPU and 1.40x on GPU.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Scaling Laws for Floating Point Quantization Training
Jan 05, 2025



Low-precision training is considered an effective strategy for reducing both training and downstream inference costs. Previous scaling laws for precision mainly focus on integer quantization, which pay less attention to the constituents in floating-point quantization and thus cannot well fit the LLM losses in this scenario. In contrast, while floating-point quantization training is more commonly implemented in production, the research on it has been relatively superficial. In this paper, we thoroughly explore the effects of floating-point quantization targets, exponent bits, mantissa bits, and the calculation granularity of the scaling factor in floating-point quantization training performance of LLM models. While presenting an accurate floating-point quantization unified scaling law, we also provide valuable suggestions for the community: (1) Exponent bits contribute slightly more to the model performance than mantissa bits. We provide the optimal exponent-mantissa bit ratio for different bit numbers, which is available for future reference by hardware manufacturers; (2) We discover the formation of the critical data size in low-precision LLM training. Too much training data exceeding the critical data size will inversely bring in degradation of LLM performance; (3) The optimal floating-point quantization precision is directly proportional to the computational power, but within a wide computational power range, we estimate that the best cost-performance precision lies between 4-8 bits.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Lossless KV Cache Compression to 2%
Oct 20, 2024



Large language models have revolutionized data processing in numerous domains, with their ability to handle extended context reasoning receiving notable recognition. To speed up inference, maintaining a key-value (KV) cache memory is essential. Nonetheless, the growing demands for KV cache memory create significant hurdles for efficient implementation. This work introduces a novel architecture, Cross-Layer Latent Attention (CLLA), aimed at compressing the KV cache to less than 2% of its original size while maintaining comparable performance levels. CLLA integrates multiple aspects of KV cache compression, including attention head/dimension reduction, layer sharing, and quantization techniques, into a cohesive framework. Our extensive experiments demonstrate that CLLA achieves lossless performance on most tasks while utilizing minimal KV cache, marking a significant advancement in practical KV cache compression.
Physical design optimization for automated drug dispensing systems in a human-machine interaction environment
Dec 18, 2023Automated drug dispensing systems (ADDSs) are increasingly in demand in today's pharmacies due to the growing aging population. Recognizing the practical needs faced by hospitals utilizing ADDSs, this study focuses on optimizing the physical design of ADDSs in a human-machine interaction environment. Specifically, we investigate the retrieval sequencing of drugs among successive prescription orders. To compare the efficiency of ADDSs with the different number of input/output designs, we formulate dual command retrieval sequencing models that optimize the retrieval sequence of drugs in adjacent prescription orders. In particular, we consider the stochastic service time of pharmacists in the 0-1 integer programming models to analyze the impact on humans. Through experimental comparisons of average picking times for prescription orders under different layout designs, the system layout with two input/output points significantly enhances the efficiency of prescription order fulfillment within a human-machine interaction environment. Furthermore, the proposed retrieval sequence method outperforms dynamic programming, greedy, and random strategies in improving prescription order-picking efficiency.
A Quick Response Algorithm for Dynamic Autonomous Mobile Robot Routing Problem with Time Windows
Nov 26, 2023



This paper investigates the optimization problem of scheduling autonomous mobile robots (AMRs) in hospital settings, considering dynamic requests with different priorities. The primary objective is to minimize the daily service cost by dynamically planning routes for the limited number of available AMRs. The total cost consists of AMR's purchase cost, transportation cost, delay penalty cost, and loss of denial of service. To address this problem, we have established a two-stage mathematical programming model. In the first stage, a tabu search algorithm is employed to plan prior routes for all known medical requests. The second stage involves planning for real-time received dynamic requests using the efficient insertion algorithm with decision rules, which enables quick response based on the time window and demand constraints of the dynamic requests. One of the main contributions of this study is to make resource allocation decisions based on the present number of service AMRs for dynamic requests with different priorities. Computational experiments using Lackner instances demonstrate the efficient insertion algorithm with decision rules is very fast and robust in solving the dynamic AMR routing problem with time windows and request priority. Additionally, we provide managerial insights concerning the AMR's safety stock settings, which can aid in decision-making processes.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.