 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
Apr 07, 2025Recent advancements in reasoning language models have demonstrated remarkable performance in complex tasks, but their extended chain-of-thought reasoning process increases inference overhead. While quantization has been widely adopted to reduce the inference cost of large language models, its impact on reasoning models remains understudied. In this study, we conduct the first systematic study on quantized reasoning models, evaluating the open-sourced DeepSeek-R1-Distilled Qwen and LLaMA families ranging from 1.5B to 70B parameters, and QwQ-32B. Our investigation covers weight, KV cache, and activation quantization using state-of-the-art algorithms at varying bit-widths, with extensive evaluation across mathematical (AIME, MATH-500), scientific (GPQA), and programming (LiveCodeBench) reasoning benchmarks. Our findings reveal that while lossless quantization can be achieved with W8A8 or W4A16 quantization, lower bit-widths introduce significant accuracy risks. We further identify model size, model origin, and task difficulty as critical determinants of performance. Contrary to expectations, quantized models do not exhibit increased output lengths. In addition, strategically scaling the model sizes or reasoning steps can effectively enhance the performance. All quantized models and codes will be open-sourced in https://github.com/ruikangliu/Quantized-Reasoning-Models.
ILLUME+: Illuminating Unified MLLM with Dual Visual Tokenization and Diffusion Refinement
Apr 03, 2025



We present ILLUME+ that leverages dual visual tokenization and a diffusion decoder to improve both deep semantic understanding and high-fidelity image generation. Existing unified models have struggled to simultaneously handle the three fundamental capabilities in a unified model: understanding, generation, and editing. Models like Chameleon and EMU3 utilize VQGAN for image discretization, due to the lack of deep semantic interaction, they lag behind specialist models like LLaVA in visual understanding tasks. To mitigate this, LaViT and ILLUME employ semantic encoders for tokenization, but they struggle with image editing due to poor texture preservation. Meanwhile, Janus series decouples the input and output image representation, limiting their abilities to seamlessly handle interleaved image-text understanding and generation. In contrast, ILLUME+ introduces a unified dual visual tokenizer, DualViTok, which preserves both fine-grained textures and text-aligned semantics while enabling a coarse-to-fine image representation strategy for multimodal understanding and generation. Additionally, we employ a diffusion model as the image detokenizer for enhanced generation quality and efficient super-resolution. ILLUME+ follows a continuous-input, discrete-output scheme within the unified MLLM and adopts a progressive training procedure that supports dynamic resolution across the vision tokenizer, MLLM, and diffusion decoder. This design allows for flexible and efficient context-aware image editing and generation across diverse tasks. ILLUME+ (3B) exhibits competitive performance against existing unified MLLMs and specialized models across multimodal understanding, generation, and editing benchmarks. With its strong performance, ILLUME+ provides a scalable and versatile foundation for future multimodal applications. Project Page: https://illume-unified-mllm.github.io/.
ILLUME: Illuminating Your LLMs to See, Draw, and Self-Enhance
Dec 09, 2024In this paper, we introduce ILLUME, a unified multimodal large language model (MLLM) that seamlessly integrates multimodal understanding and generation capabilities within a single large language model through a unified next-token prediction formulation. To address the large dataset size typically required for image-text alignment, we propose to enhance data efficiency through the design of a vision tokenizer that incorporates semantic information and a progressive multi-stage training procedure. This approach reduces the dataset size to just 15M for pretraining -- over four times fewer than what is typically needed -- while achieving competitive or even superior performance with existing unified MLLMs, such as Janus. Additionally, to promote synergistic enhancement between understanding and generation capabilities, which is under-explored in previous works, we introduce a novel self-enhancing multimodal alignment scheme. This scheme supervises the MLLM to self-assess the consistency between text descriptions and self-generated images, facilitating the model to interpret images more accurately and avoid unrealistic and incorrect predictions caused by misalignment in image generation. Based on extensive experiments, our proposed ILLUME stands out and competes with state-of-the-art unified MLLMs and specialized models across various benchmarks for multimodal understanding, generation, and editing.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024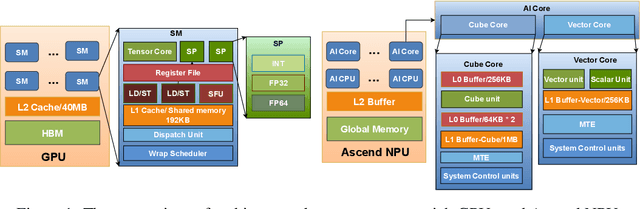

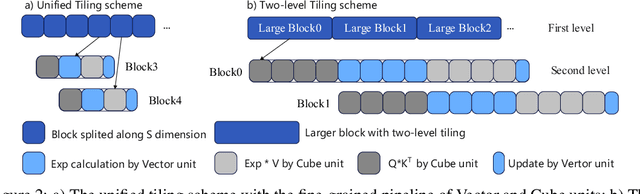

FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
FlatQuant: Flatness Matters for LLM Quantization
Oct 12, 2024



Recently, quantization has been widely used for the compression and acceleration of large language models~(LLMs). Due to the outliers in LLMs, it is crucial to flatten weights and activations to minimize quantization error with the equally spaced quantization points. Prior research explores various pre-quantization transformations to suppress outliers, such as per-channel scaling and Hadamard transformation. However, we observe that these transformed weights and activations can still remain steep and outspread. In this paper, we propose FlatQuant (Fast and Learnable Affine Transformation), a new post-training quantization approach to enhance flatness of weights and activations. Our approach identifies optimal affine transformations tailored to each linear layer, calibrated in hours via a lightweight objective. To reduce runtime overhead, we apply Kronecker decomposition to the transformation matrices, and fuse all operations in FlatQuant into a single kernel. Extensive experiments show that FlatQuant sets up a new state-of-the-art quantization benchmark. For instance, it achieves less than $\textbf{1}\%$ accuracy drop for W4A4 quantization on the LLaMA-3-70B model, surpassing SpinQuant by $\textbf{7.5}\%$. For inference latency, FlatQuant reduces the slowdown induced by pre-quantization transformation from 0.26x of QuaRot to merely $\textbf{0.07x}$, bringing up to $\textbf{2.3x}$ speedup for prefill and $\textbf{1.7x}$ speedup for decoding, respectively. Code is available at: \url{https://github.com/ruikangliu/FlatQuant}.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024



GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
UNIT: Unifying Image and Text Recognition in One Vision Encoder
Sep 06, 2024



Currently, vision encoder models like Vision Transformers (ViTs) typically excel at image recognition tasks but cannot simultaneously support text recognition like human visual recognition. To address this limitation, we propose UNIT, a novel training framework aimed at UNifying Image and Text recognition within a single model. Starting with a vision encoder pre-trained with image recognition tasks, UNIT introduces a lightweight language decoder for predicting text outputs and a lightweight vision decoder to prevent catastrophic forgetting of the original image encoding capabilities. The training process comprises two stages: intra-scale pretraining and inter-scale finetuning. During intra-scale pretraining, UNIT learns unified representations from multi-scale inputs, where images and documents are at their commonly used resolution, to enable fundamental recognition capability. In the inter-scale finetuning stage, the model introduces scale-exchanged data, featuring images and documents at resolutions different from the most commonly used ones, to enhance its scale robustness. Notably, UNIT retains the original vision encoder architecture, making it cost-free in terms of inference and deployment. Experiments across multiple benchmarks confirm that our method significantly outperforms existing methods on document-related tasks (e.g., OCR and DocQA) while maintaining the performances on natural images, demonstrating its ability to substantially enhance text recognition without compromising its core image recognition capabilities.
Embedding Compression in Recommender Systems: A Survey
Aug 05, 2024To alleviate the problem of information explosion, recommender systems are widely deployed to provide personalized information filtering services. Usually, embedding tables are employed in recommender systems to transform high-dimensional sparse one-hot vectors into dense real-valued embeddings. However, the embedding tables are huge and account for most of the parameters in industrial-scale recommender systems. In order to reduce memory costs and improve efficiency, various approaches are proposed to compress the embedding tables. In this survey, we provide a comprehensive review of embedding compression approaches in recommender systems. We first introduce deep learning recommendation models and the basic concept of embedding compression in recommender systems. Subsequently, we systematically organize existing approaches into three categories, namely low-precision, mixed-dimension, and weight-sharing, respectively. Lastly, we summarize the survey with some general suggestions and provide future prospects for this field.
* Accepted by ACM Computing Surveys
HiRes-LLaVA: Restoring Fragmentation Input in High-Resolution Large Vision-Language Models
Jul 11, 2024



High-resolution inputs enable Large Vision-Language Models (LVLMs) to discern finer visual details, enhancing their comprehension capabilities. To reduce the training and computation costs caused by high-resolution input, one promising direction is to use sliding windows to slice the input into uniform patches, each matching the input size of the well-trained vision encoder. Although efficient, this slicing strategy leads to the fragmentation of original input, i.e., the continuity of contextual information and spatial geometry is lost across patches, adversely affecting performance in cross-patch context perception and position-specific tasks. To overcome these shortcomings, we introduce HiRes-LLaVA, a novel framework designed to efficiently process any size of high-resolution input without altering the original contextual and geometric information. HiRes-LLaVA comprises two innovative components: (i) a SliceRestore adapter that reconstructs sliced patches into their original form, efficiently extracting both global and local features via down-up-sampling and convolution layers, and (ii) a Self-Mining Sampler to compresses the vision tokens based on themselves, preserving the original context and positional information while reducing training overhead. To assess the ability of handling context fragmentation, we construct a new benchmark, EntityGrid-QA, consisting of edge-related and position-related tasks. Our comprehensive experiments demonstrate the superiority of HiRes-LLaVA on both existing public benchmarks and on EntityGrid-QA, particularly on document-oriented tasks, establishing new standards for handling high-resolution inputs.
DeCo: Decoupling Token Compression from Semantic Abstraction in Multimodal Large Language Models
May 31, 2024



The visual projector, which bridges the vision and language modalities and facilitates cross-modal alignment, serves as a crucial component in MLLMs. However, measuring the effectiveness of projectors in vision-language alignment remains under-explored, which currently can only be inferred from the performance of MLLMs on downstream tasks. Motivated by the problem, this study examines the projector module by interpreting the vision-language semantic flow within MLLMs. Specifically, we trace back the semantic relevance flow from generated language tokens to raw visual encoder patches and the intermediate outputs produced by projectors. Our findings reveal that compressive projectors (e.g., QFormer), abstract visual patches into a limited set of semantic concepts, such as objects or attributes, resulting in a 'double abstraction' phenomenon. This involves a first visual semantic abstraction by the projector referring to pre-defined query tokens, and a second extraction by the LLM based on text instructions. The double abstraction is inefficient in training and will result in cumulative vision semantics deficiency. To mitigate this issue, we propose the key insight of 'Decouple Compression from Abstraction (DeCo), that is compressing the visual token number at the patch level by projectors and allowing the LLM to handle visual semantic abstraction entirely. Consequently, we adopt a simple compressor, i.e., 2D Adaptive Pooling, to downsample visual patches in a parameter-free manner. Empirical evaluation demonstrates that DeCo surpasses traditional compressive projectors regarding both performance and efficiency. It achieves performance gains of 0.9%, 7.1%, and 2.9% across the MLLM Benchmarks, Visual Localization, and Open-ended VQA tasks with fewer trainable parameters and faster convergence speed.