 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexPIE: Stable Dexterous Policy Improvement from Real-World Experience
Jun 08, 2026Dexterous manipulation presents substantial challenges for imitation learning due to its high-dimensional action space and complex contact-rich dynamics. Policies trained purely from demonstrations often suffer from compounding errors during deployment and require large amounts of expert data to achieve reliable performance. To move beyond the limitations of demonstration data, in this work, we propose DexPIE, a post-training framework for dexterous policy improvement from experience collected through real-world deployment. First, DexPIE enables effective exploration coverage through a dexterous-hand-adapted intervention system and multi-stage DAgger-style data collection across initial and intermediate task stages, providing reliable supervision for accurate policy evaluation. To reduce temporal noise between post-training rollouts and demonstration data, we introduce asynchronous inference in the relative action space, which better aligns rollout data with demonstrated behavior and allows the critic to learn a value function induced by a more consistent underlying policy. Finally, DexPIE improves the policy through conditioning on a continuous optimality indicator, allowing the policy to leverage the quality of data in a more fine-grained manner. Across three challenging real-world dexterous manipulation tasks, DexPIE achieves a 37% improvement in success rate over the demonstration-based reference policy, outperforming all baseline methods and demonstrating stronger robustness. The source code and dataset will be made publicly available.
WASD: Locating Critical Neurons as Sufficient Conditions for Explaining and Controlling LLM Behavior
Mar 19, 2026Precise behavioral control of large language models (LLMs) is critical for complex applications. However, existing methods often incur high training costs, lack natural language controllability, or compromise semantic coherence. To bridge this gap, we propose WASD (unWeaving Actionable Sufficient Directives), a novel framework that explains model behavior by identifying sufficient neural conditions for token generation. Our method represents candidate conditions as neuron-activation predicates and iteratively searches for a minimal set that guarantees the current output under input perturbations. Experiments on SST-2 and CounterFact with the Gemma-2-2B model demonstrate that our approach produces explanations that are more stable, accurate, and concise than conventional attribution graphs. Moreover, through a case study on controlling cross-lingual output generation, we validated the practical effectiveness of WASD in controlling model behavior.
Valley2: Exploring Multimodal Models with Scalable Vision-Language Design
Jan 13, 2025



Recently, vision-language models have made remarkable progress, demonstrating outstanding capabilities in various tasks such as image captioning and video understanding. We introduce Valley2, a novel multimodal large language model designed to enhance performance across all domains and extend the boundaries of practical applications in e-commerce and short video scenarios. Notably, Valley2 achieves state-of-the-art (SOTA) performance on e-commerce benchmarks, surpassing open-source models of similar size by a large margin (79.66 vs. 72.76). Additionally, Valley2 ranks second on the OpenCompass leaderboard among models with fewer than 10B parameters, with an impressive average score of 67.4. The code and model weights are open-sourced at https://github.com/bytedance/Valley.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024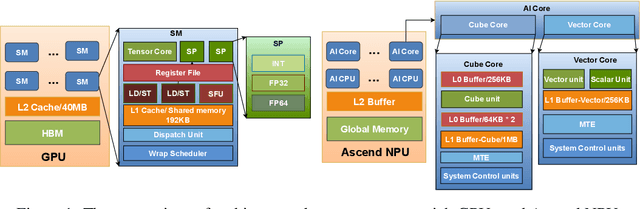

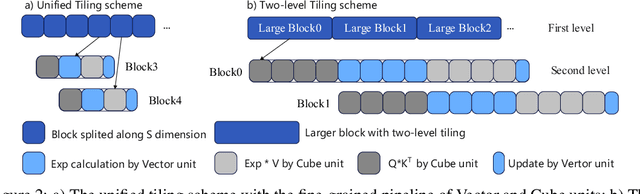

FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
Learning Granularity-Aware Affordances from Human-Object Interaction for Tool-Based Functional Grasping in Dexterous Robotics
Jun 30, 2024



To enable robots to use tools, the initial step is teaching robots to employ dexterous gestures for touching specific areas precisely where tasks are performed. Affordance features of objects serve as a bridge in the functional interaction between agents and objects. However, leveraging these affordance cues to help robots achieve functional tool grasping remains unresolved. To address this, we propose a granularity-aware affordance feature extraction method for locating functional affordance areas and predicting dexterous coarse gestures. We study the intrinsic mechanisms of human tool use. On one hand, we use fine-grained affordance features of object-functional finger contact areas to locate functional affordance regions. On the other hand, we use highly activated coarse-grained affordance features in hand-object interaction regions to predict grasp gestures. Additionally, we introduce a model-based post-processing module that includes functional finger coordinate localization, finger-to-end coordinate transformation, and force feedback-based coarse-to-fine grasping. This forms a complete dexterous robotic functional grasping framework GAAF-Dex, which learns Granularity-Aware Affordances from human-object interaction for tool-based Functional grasping in Dexterous Robotics. Unlike fully-supervised methods that require extensive data annotation, we employ a weakly supervised approach to extract relevant cues from exocentric (Exo) images of hand-object interactions to supervise feature extraction in egocentric (Ego) images. We have constructed a small-scale dataset, FAH, which includes near 6K images of functional hand-object interaction Exo- and Ego images of 18 commonly used tools performing 6 tasks. Extensive experiments on the dataset demonstrate our method outperforms state-of-the-art methods. The code will be made publicly available at https://github.com/yangfan293/GAAF-DEX.