 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoESD: Unveil Speculative Decoding's Potential for Accelerating Sparse MoE
May 26, 2025Large Language Models (LLMs) have achieved remarkable success across many applications, with Mixture of Experts (MoE) models demonstrating great potential. Compared to traditional dense models, MoEs achieve better performance with less computation. Speculative decoding (SD) is a widely used technique to accelerate LLM inference without accuracy loss, but it has been considered efficient only for dense models. In this work, we first demonstrate that, under medium batch sizes, MoE surprisingly benefits more from SD than dense models. Furthermore, as MoE becomes sparser -- the prevailing trend in MoE designs -- the batch size range where SD acceleration is expected to be effective becomes broader. To quantitatively understand tradeoffs involved in SD, we develop a reliable modeling based on theoretical analyses. While current SD research primarily focuses on improving acceptance rates of algorithms, changes in workload and model architecture can still lead to degraded SD acceleration even with high acceptance rates. To address this limitation, we introduce a new metric 'target efficiency' that characterizes these effects, thus helping researchers identify system bottlenecks and understand SD acceleration more comprehensively. For scenarios like private serving, this work unveils a new perspective to speed up MoE inference, where existing solutions struggle. Experiments on different GPUs show up to 2.29x speedup for Qwen2-57B-A14B at medium batch sizes and validate our theoretical predictions.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs
Oct 22, 2024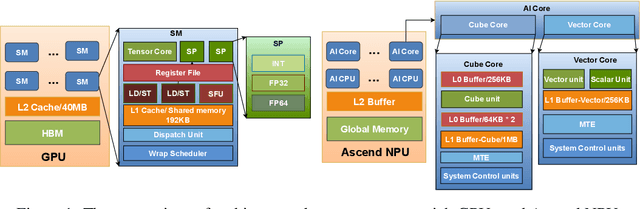

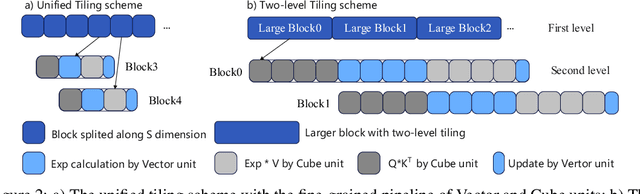

FlashAttention series has been widely applied in the inference of large language models (LLMs). However, FlashAttention series only supports the high-level GPU architectures, e.g., Ampere and Hopper. At present, FlashAttention series is not easily transferrable to NPUs and low-resource GPUs. Moreover, FlashAttention series is inefficient for multi- NPUs or GPUs inference scenarios. In this work, we propose FastAttention which pioneers the adaptation of FlashAttention series for NPUs and low-resource GPUs to boost LLM inference efficiency. Specifically, we take Ascend NPUs and Volta-based GPUs as representatives for designing our FastAttention. We migrate FlashAttention series to Ascend NPUs by proposing a novel two-level tiling strategy for runtime speedup, tiling-mask strategy for memory saving and the tiling-AllReduce strategy for reducing communication overhead, respectively. Besides, we adapt FlashAttention for Volta-based GPUs by redesigning the operands layout in shared memory and introducing a simple yet effective CPU-GPU cooperative strategy for efficient memory utilization. On Ascend NPUs, our FastAttention can achieve a 10.7$\times$ speedup compared to the standard attention implementation. Llama-7B within FastAttention reaches up to 5.16$\times$ higher throughput than within the standard attention. On Volta architecture GPUs, FastAttention yields 1.43$\times$ speedup compared to its equivalents in \texttt{xformers}. Pangu-38B within FastAttention brings 1.46$\times$ end-to-end speedup using FasterTransformer. Coupled with the propose CPU-GPU cooperative strategy, FastAttention supports a maximal input length of 256K on 8 V100 GPUs. All the codes will be made available soon.
Component Divide-and-Conquer for Real-World Image Super-Resolution
Aug 05, 2020In this paper, we present a large-scale Diverse Real-world image Super-Resolution dataset, i.e., DRealSR, as well as a divide-and-conquer Super-Resolution (SR) network, exploring the utility of guiding SR model with low-level image components. DRealSR establishes a new SR benchmark with diverse real-world degradation processes, mitigating the limitations of conventional simulated image degradation. In general, the targets of SR vary with image regions with different low-level image components, e.g., smoothness preserving for flat regions, sharpening for edges, and detail enhancing for textures. Learning an SR model with conventional pixel-wise loss usually is easily dominated by flat regions and edges, and fails to infer realistic details of complex textures. We propose a Component Divide-and-Conquer (CDC) model and a Gradient-Weighted (GW) loss for SR. Our CDC parses an image with three components, employs three Component-Attentive Blocks (CABs) to learn attentive masks and intermediate SR predictions with an intermediate supervision learning strategy, and trains an SR model following a divide-and-conquer learning principle. Our GW loss also provides a feasible way to balance the difficulties of image components for SR. Extensive experiments validate the superior performance of our CDC and the challenging aspects of our DRealSR dataset related to diverse real-world scenarios. Our dataset and codes are publicly available at https://github.com/xiezw5/Component-Divide-and-Conquer-for-Real-World-Image-Super-Resolution