 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Vision Language Model Unlearning via Fictitious Facial Identity Dataset
Nov 05, 2024



Machine unlearning has emerged as an effective strategy for forgetting specific information in the training data. However, with the increasing integration of visual data, privacy concerns in Vision Language Models (VLMs) remain underexplored. To address this, we introduce Facial Identity Unlearning Benchmark (FIUBench), a novel VLM unlearning benchmark designed to robustly evaluate the effectiveness of unlearning algorithms under the Right to be Forgotten setting. Specifically, we formulate the VLM unlearning task via constructing the Fictitious Facial Identity VQA dataset and apply a two-stage evaluation pipeline that is designed to precisely control the sources of information and their exposure levels. In terms of evaluation, since VLM supports various forms of ways to ask questions with the same semantic meaning, we also provide robust evaluation metrics including membership inference attacks and carefully designed adversarial privacy attacks to evaluate the performance of algorithms. Through the evaluation of four baseline VLM unlearning algorithms within FIUBench, we find that all methods remain limited in their unlearning performance, with significant trade-offs between model utility and forget quality. Furthermore, our findings also highlight the importance of privacy attacks for robust evaluations. We hope FIUBench will drive progress in developing more effective VLM unlearning algorithms.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


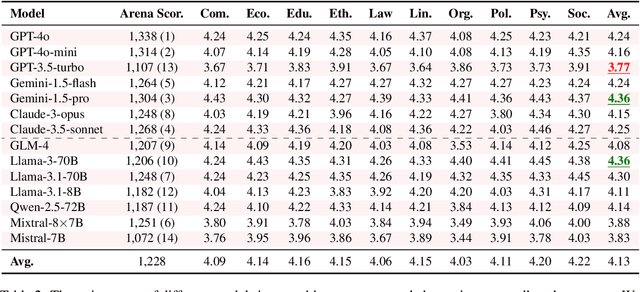
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
Solving Continual Offline RL through Selective Weights Activation on Aligned Spaces
Oct 21, 2024Continual offline reinforcement learning (CORL) has shown impressive ability in diffusion-based lifelong learning systems by modeling the joint distributions of trajectories. However, most research only focuses on limited continual task settings where the tasks have the same observation and action space, which deviates from the realistic demands of training agents in various environments. In view of this, we propose Vector-Quantized Continual Diffuser, named VQ-CD, to break the barrier of different spaces between various tasks. Specifically, our method contains two complementary sections, where the quantization spaces alignment provides a unified basis for the selective weights activation. In the quantized spaces alignment, we leverage vector quantization to align the different state and action spaces of various tasks, facilitating continual training in the same space. Then, we propose to leverage a unified diffusion model attached by the inverse dynamic model to master all tasks by selectively activating different weights according to the task-related sparse masks. Finally, we conduct extensive experiments on 15 continual learning (CL) tasks, including conventional CL task settings (identical state and action spaces) and general CL task settings (various state and action spaces). Compared with 16 baselines, our method reaches the SOTA performance.
BenTo: Benchmark Task Reduction with In-Context Transferability
Oct 17, 2024Evaluating large language models (LLMs) is costly: it requires the generation and examination of LLM outputs on a large-scale benchmark of various tasks. This paper investigates how to efficiently reduce the tasks used to benchmark LLMs without affecting the evaluation quality. Our study reveals that task transferability and relevance provide critical information to identify the most representative subset of tasks via optimizing a facility location function. We propose a practically efficient metric for estimating the transferability between two tasks via in-context learning (ICL). By analyzing the pairwise transferability, we can reduce tasks in a modern LLM benchmark (e.g., MMLU or FLAN) to 5% while inducing only a <4% difference to the evaluation on the original benchmark. Compared to prior works, our method is training-free, gradient-free, and highly efficient requiring ICL only.
FedCAP: Robust Federated Learning via Customized Aggregation and Personalization
Oct 16, 2024



Federated learning (FL), an emerging distributed machine learning paradigm, has been applied to various privacy-preserving scenarios. However, due to its distributed nature, FL faces two key issues: the non-independent and identical distribution (non-IID) of user data and vulnerability to Byzantine threats. To address these challenges, in this paper, we propose FedCAP, a robust FL framework against both data heterogeneity and Byzantine attacks. The core of FedCAP is a model update calibration mechanism to help a server capture the differences in the direction and magnitude of model updates among clients. Furthermore, we design a customized model aggregation rule that facilitates collaborative training among similar clients while accelerating the model deterioration of malicious clients. With a Euclidean norm-based anomaly detection mechanism, the server can quickly identify and permanently remove malicious clients. Moreover, the impact of data heterogeneity and Byzantine attacks can be further mitigated through personalization on the client side. We conduct extensive experiments, comparing multiple state-of-the-art baselines, to demonstrate that FedCAP performs well in several non-IID settings and shows strong robustness under a series of poisoning attacks.
MLP-KAN: Unifying Deep Representation and Function Learning
Oct 03, 2024



Recent advancements in both representation learning and function learning have demonstrated substantial promise across diverse domains of artificial intelligence. However, the effective integration of these paradigms poses a significant challenge, particularly in cases where users must manually decide whether to apply a representation learning or function learning model based on dataset characteristics. To address this issue, we introduce MLP-KAN, a unified method designed to eliminate the need for manual model selection. By integrating Multi-Layer Perceptrons (MLPs) for representation learning and Kolmogorov-Arnold Networks (KANs) for function learning within a Mixture-of-Experts (MoE) architecture, MLP-KAN dynamically adapts to the specific characteristics of the task at hand, ensuring optimal performance. Embedded within a transformer-based framework, our work achieves remarkable results on four widely-used datasets across diverse domains. Extensive experimental evaluation demonstrates its superior versatility, delivering competitive performance across both deep representation and function learning tasks. These findings highlight the potential of MLP-KAN to simplify the model selection process, offering a comprehensive, adaptable solution across various domains. Our code and weights are available at \url{https://github.com/DLYuanGod/MLP-KAN}.
Empirical Perturbation Analysis of Linear System Solvers from a Data Poisoning Perspective
Oct 01, 2024



The perturbation analysis of linear solvers applied to systems arising broadly in machine learning settings -- for instance, when using linear regression models -- establishes an important perspective when reframing these analyses through the lens of a data poisoning attack. By analyzing solvers' responses to such attacks, this work aims to contribute to the development of more robust linear solvers and provide insights into poisoning attacks on linear solvers. In particular, we investigate how the errors in the input data will affect the fitting error and accuracy of the solution from a linear system-solving algorithm under perturbations common in adversarial attacks. We propose data perturbation through two distinct knowledge levels, developing a poisoning optimization and studying two methods of perturbation: Label-guided Perturbation (LP) and Unconditioning Perturbation (UP). Existing works mainly focus on deriving the worst-case perturbation bound from a theoretical perspective, and the analysis is often limited to specific kinds of linear system solvers. Under the circumstance that the data is intentionally perturbed -- as is the case with data poisoning -- we seek to understand how different kinds of solvers react to these perturbations, identifying those algorithms most impacted by different types of adversarial attacks.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024



This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
LLM4Brain: Training a Large Language Model for Brain Video Understanding
Sep 26, 2024



Decoding visual-semantic information from brain signals, such as functional MRI (fMRI), across different subjects poses significant challenges, including low signal-to-noise ratio, limited data availability, and cross-subject variability. Recent advancements in large language models (LLMs) show remarkable effectiveness in processing multimodal information. In this study, we introduce an LLM-based approach for reconstructing visual-semantic information from fMRI signals elicited by video stimuli. Specifically, we employ fine-tuning techniques on an fMRI encoder equipped with adaptors to transform brain responses into latent representations aligned with the video stimuli. Subsequently, these representations are mapped to textual modality by LLM. In particular, we integrate self-supervised domain adaptation methods to enhance the alignment between visual-semantic information and brain responses. Our proposed method achieves good results using various quantitative semantic metrics, while yielding similarity with ground-truth information.
TTT-Unet: Enhancing U-Net with Test-Time Training Layers for Biomedical Image Segmentation
Sep 18, 2024



Biomedical image segmentation is crucial for accurately diagnosing and analyzing various diseases. However, Convolutional Neural Networks (CNNs) and Transformers, the most commonly used architectures for this task, struggle to effectively capture long-range dependencies due to the inherent locality of CNNs and the computational complexity of Transformers. To address this limitation, we introduce TTT-Unet, a novel framework that integrates Test-Time Training (TTT) layers into the traditional U-Net architecture for biomedical image segmentation. TTT-Unet dynamically adjusts model parameters during the testing time, enhancing the model's ability to capture both local and long-range features. We evaluate TTT-Unet on multiple medical imaging datasets, including 3D abdominal organ segmentation in CT and MR images, instrument segmentation in endoscopy images, and cell segmentation in microscopy images. The results demonstrate that TTT-Unet consistently outperforms state-of-the-art CNN-based and Transformer-based segmentation models across all tasks. The code is available at https://github.com/rongzhou7/TTT-Unet.