 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Flow Policy Optimization
May 26, 2025In recent years, generative models have shown remarkable capabilities across diverse fields, including images, videos, language, and decision-making. By applying powerful generative models such as flow-based models to reinforcement learning, we can effectively model complex multi-modal action distributions and achieve superior robotic control in continuous action spaces, surpassing the limitations of single-modal action distributions with traditional Gaussian-based policies. Previous methods usually adopt the generative models as behavior models to fit state-conditioned action distributions from datasets, with policy optimization conducted separately through additional policies using value-based sample weighting or gradient-based updates. However, this separation prevents the simultaneous optimization of multi-modal distribution fitting and policy improvement, ultimately hindering the training of models and degrading the performance. To address this issue, we propose Decision Flow, a unified framework that integrates multi-modal action distribution modeling and policy optimization. Specifically, our method formulates the action generation procedure of flow-based models as a flow decision-making process, where each action generation step corresponds to one flow decision. Consequently, our method seamlessly optimizes the flow policy while capturing multi-modal action distributions. We provide rigorous proofs of Decision Flow and validate the effectiveness through extensive experiments across dozens of offline RL environments. Compared with established offline RL baselines, the results demonstrate that our method achieves or matches the SOTA performance.
Analytic Energy-Guided Policy Optimization for Offline Reinforcement Learning
May 03, 2025Conditional decision generation with diffusion models has shown powerful competitiveness in reinforcement learning (RL). Recent studies reveal the relation between energy-function-guidance diffusion models and constrained RL problems. The main challenge lies in estimating the intermediate energy, which is intractable due to the log-expectation formulation during the generation process. To address this issue, we propose the Analytic Energy-guided Policy Optimization (AEPO). Specifically, we first provide a theoretical analysis and the closed-form solution of the intermediate guidance when the diffusion model obeys the conditional Gaussian transformation. Then, we analyze the posterior Gaussian distribution in the log-expectation formulation and obtain the target estimation of the log-expectation under mild assumptions. Finally, we train an intermediate energy neural network to approach the target estimation of log-expectation formulation. We apply our method in 30+ offline RL tasks to demonstrate the effectiveness of our method. Extensive experiments illustrate that our method surpasses numerous representative baselines in D4RL offline reinforcement learning benchmarks.
Continual Task Learning through Adaptive Policy Self-Composition
Nov 18, 2024



Training a generalizable agent to continually learn a sequence of tasks from offline trajectories is a natural requirement for long-lived agents, yet remains a significant challenge for current offline reinforcement learning (RL) algorithms. Specifically, an agent must be able to rapidly adapt to new tasks using newly collected trajectories (plasticity), while retaining knowledge from previously learned tasks (stability). However, systematic analyses of this setting are scarce, and it remains unclear whether conventional continual learning (CL) methods are effective in continual offline RL (CORL) scenarios. In this study, we develop the Offline Continual World benchmark and demonstrate that traditional CL methods struggle with catastrophic forgetting, primarily due to the unique distribution shifts inherent to CORL scenarios. To address this challenge, we introduce CompoFormer, a structure-based continual transformer model that adaptively composes previous policies via a meta-policy network. Upon encountering a new task, CompoFormer leverages semantic correlations to selectively integrate relevant prior policies alongside newly trained parameters, thereby enhancing knowledge sharing and accelerating the learning process. Our experiments reveal that CompoFormer outperforms conventional CL methods, particularly in longer task sequences, showcasing a promising balance between plasticity and stability.
Solving Continual Offline RL through Selective Weights Activation on Aligned Spaces
Oct 21, 2024Continual offline reinforcement learning (CORL) has shown impressive ability in diffusion-based lifelong learning systems by modeling the joint distributions of trajectories. However, most research only focuses on limited continual task settings where the tasks have the same observation and action space, which deviates from the realistic demands of training agents in various environments. In view of this, we propose Vector-Quantized Continual Diffuser, named VQ-CD, to break the barrier of different spaces between various tasks. Specifically, our method contains two complementary sections, where the quantization spaces alignment provides a unified basis for the selective weights activation. In the quantized spaces alignment, we leverage vector quantization to align the different state and action spaces of various tasks, facilitating continual training in the same space. Then, we propose to leverage a unified diffusion model attached by the inverse dynamic model to master all tasks by selectively activating different weights according to the task-related sparse masks. Finally, we conduct extensive experiments on 15 continual learning (CL) tasks, including conventional CL task settings (identical state and action spaces) and general CL task settings (various state and action spaces). Compared with 16 baselines, our method reaches the SOTA performance.
Continual Diffuser (CoD): Mastering Continual Offline Reinforcement Learning with Experience Rehearsal
Sep 04, 2024



Artificial neural networks, especially recent diffusion-based models, have shown remarkable superiority in gaming, control, and QA systems, where the training tasks' datasets are usually static. However, in real-world applications, such as robotic control of reinforcement learning (RL), the tasks are changing, and new tasks arise in a sequential order. This situation poses the new challenge of plasticity-stability trade-off for training an agent who can adapt to task changes and retain acquired knowledge. In view of this, we propose a rehearsal-based continual diffusion model, called Continual Diffuser (CoD), to endow the diffuser with the capabilities of quick adaptation (plasticity) and lasting retention (stability). Specifically, we first construct an offline benchmark that contains 90 tasks from multiple domains. Then, we train the CoD on each task with sequential modeling and conditional generation for making decisions. Next, we preserve a small portion of previous datasets as the rehearsal buffer and replay it to retain the acquired knowledge. Extensive experiments on a series of tasks show CoD can achieve a promising plasticity-stability trade-off and outperform existing diffusion-based methods and other representative baselines on most tasks.
In-Context Decision Transformer: Reinforcement Learning via Hierarchical Chain-of-Thought
May 31, 2024



In-context learning is a promising approach for offline reinforcement learning (RL) to handle online tasks, which can be achieved by providing task prompts. Recent works demonstrated that in-context RL could emerge with self-improvement in a trial-and-error manner when treating RL tasks as an across-episodic sequential prediction problem. Despite the self-improvement not requiring gradient updates, current works still suffer from high computational costs when the across-episodic sequence increases with task horizons. To this end, we propose an In-context Decision Transformer (IDT) to achieve self-improvement in a high-level trial-and-error manner. Specifically, IDT is inspired by the efficient hierarchical structure of human decision-making and thus reconstructs the sequence to consist of high-level decisions instead of low-level actions that interact with environments. As one high-level decision can guide multi-step low-level actions, IDT naturally avoids excessively long sequences and solves online tasks more efficiently. Experimental results show that IDT achieves state-of-the-art in long-horizon tasks over current in-context RL methods. In particular, the online evaluation time of our IDT is \textbf{36$\times$} times faster than baselines in the D4RL benchmark and \textbf{27$\times$} times faster in the Grid World benchmark.
Learning Generalizable Agents via Saliency-Guided Features Decorrelation
Oct 08, 2023



In visual-based Reinforcement Learning (RL), agents often struggle to generalize well to environmental variations in the state space that were not observed during training. The variations can arise in both task-irrelevant features, such as background noise, and task-relevant features, such as robot configurations, that are related to the optimal decisions. To achieve generalization in both situations, agents are required to accurately understand the impact of changed features on the decisions, i.e., establishing the true associations between changed features and decisions in the policy model. However, due to the inherent correlations among features in the state space, the associations between features and decisions become entangled, making it difficult for the policy to distinguish them. To this end, we propose Saliency-Guided Features Decorrelation (SGFD) to eliminate these correlations through sample reweighting. Concretely, SGFD consists of two core techniques: Random Fourier Functions (RFF) and the saliency map. RFF is utilized to estimate the complex non-linear correlations in high-dimensional images, while the saliency map is designed to identify the changed features. Under the guidance of the saliency map, SGFD employs sample reweighting to minimize the estimated correlations related to changed features, thereby achieving decorrelation in visual RL tasks. Our experimental results demonstrate that SGFD can generalize well on a wide range of test environments and significantly outperforms state-of-the-art methods in handling both task-irrelevant variations and task-relevant variations.
A Simple Unified Uncertainty-Guided Framework for Offline-to-Online Reinforcement Learning
Jun 13, 2023



Offline reinforcement learning (RL) provides a promising solution to learning an agent fully relying on a data-driven paradigm. However, constrained by the limited quality of the offline dataset, its performance is often sub-optimal. Therefore, it is desired to further finetune the agent via extra online interactions before deployment. Unfortunately, offline-to-online RL can be challenging due to two main challenges: constrained exploratory behavior and state-action distribution shift. To this end, we propose a Simple Unified uNcertainty-Guided (SUNG) framework, which naturally unifies the solution to both challenges with the tool of uncertainty. Specifically, SUNG quantifies uncertainty via a VAE-based state-action visitation density estimator. To facilitate efficient exploration, SUNG presents a practical optimistic exploration strategy to select informative actions with both high value and high uncertainty. Moreover, SUNG develops an adaptive exploitation method by applying conservative offline RL objectives to high-uncertainty samples and standard online RL objectives to low-uncertainty samples to smoothly bridge offline and online stages. SUNG achieves state-of-the-art online finetuning performance when combined with different offline RL methods, across various environments and datasets in D4RL benchmark.
Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning
Jun 08, 2023



Recent works have shown the potential of diffusion models in computer vision and natural language processing. Apart from the classical supervised learning fields, diffusion models have also shown strong competitiveness in reinforcement learning (RL) by formulating decision-making as sequential generation. However, incorporating temporal information of sequential data and utilizing it to guide diffusion models to perform better generation is still an open challenge. In this paper, we take one step forward to investigate controllable generation with temporal conditions that are refined from temporal information. We observe the importance of temporal conditions in sequential generation in sufficient explorative scenarios and provide a comprehensive discussion and comparison of different temporal conditions. Based on the observations, we propose an effective temporally-conditional diffusion model coined Temporally-Composable Diffuser (TCD), which extracts temporal information from interaction sequences and explicitly guides generation with temporal conditions. Specifically, we separate the sequences into three parts according to time expansion and identify historical, immediate, and prospective conditions accordingly. Each condition preserves non-overlapping temporal information of sequences, enabling more controllable generation when we jointly use them to guide the diffuser. Finally, we conduct extensive experiments and analysis to reveal the favorable applicability of TCD in offline RL tasks, where our method reaches or matches the best performance compared with prior SOTA baselines.
Distributional Reward Estimation for Effective Multi-Agent Deep Reinforcement Learning
Oct 14, 2022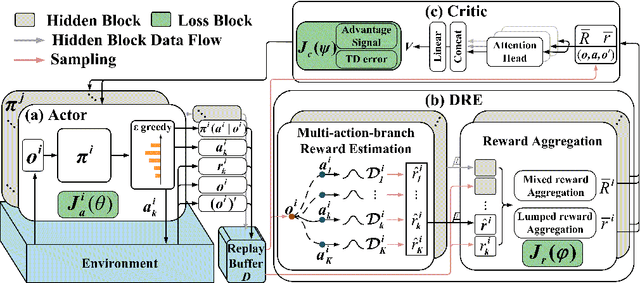
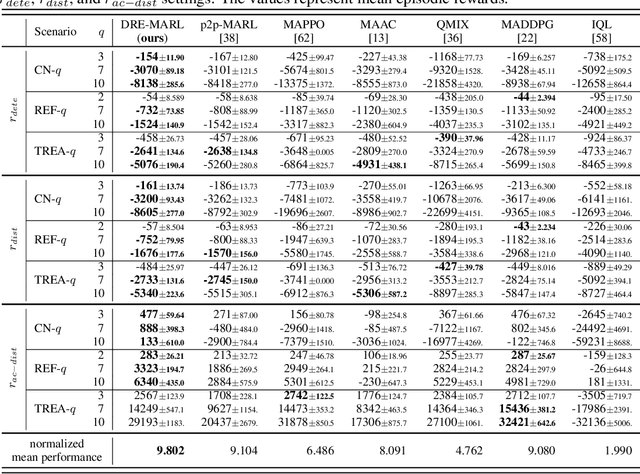
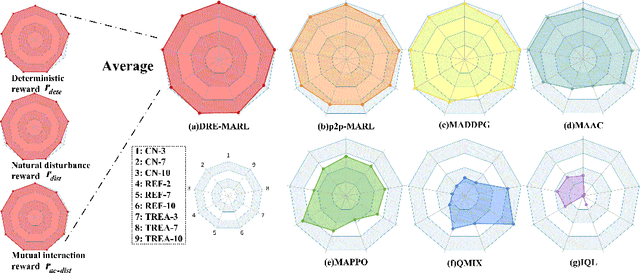
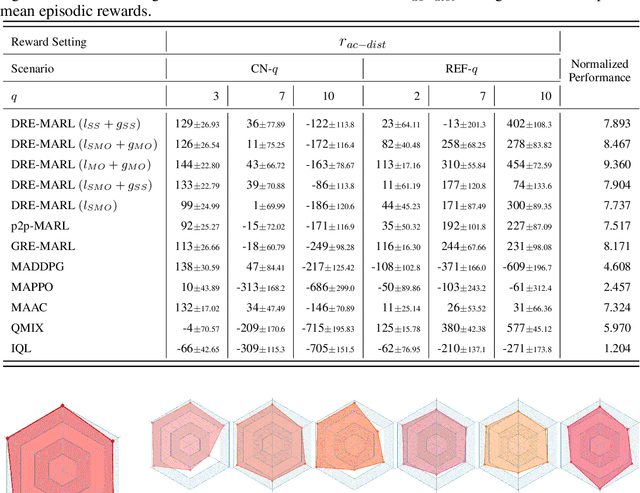
Multi-agent reinforcement learning has drawn increasing attention in practice, e.g., robotics and automatic driving, as it can explore optimal policies using samples generated by interacting with the environment. However, high reward uncertainty still remains a problem when we want to train a satisfactory model, because obtaining high-quality reward feedback is usually expensive and even infeasible. To handle this issue, previous methods mainly focus on passive reward correction. At the same time, recent active reward estimation methods have proven to be a recipe for reducing the effect of reward uncertainty. In this paper, we propose a novel Distributional Reward Estimation framework for effective Multi-Agent Reinforcement Learning (DRE-MARL). Our main idea is to design the multi-action-branch reward estimation and policy-weighted reward aggregation for stabilized training. Specifically, we design the multi-action-branch reward estimation to model reward distributions on all action branches. Then we utilize reward aggregation to obtain stable updating signals during training. Our intuition is that consideration of all possible consequences of actions could be useful for learning policies. The superiority of the DRE-MARL is demonstrated using benchmark multi-agent scenarios, compared with the SOTA baselines in terms of both effectiveness and robustness.