 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff$^2$I2P: Differentiable Image-to-Point Cloud Registration with Diffusion Prior
Jul 09, 2025Learning cross-modal correspondences is essential for image-to-point cloud (I2P) registration. Existing methods achieve this mostly by utilizing metric learning to enforce feature alignment across modalities, disregarding the inherent modality gap between image and point data. Consequently, this paradigm struggles to ensure accurate cross-modal correspondences. To this end, inspired by the cross-modal generation success of recent large diffusion models, we propose Diff$^2$I2P, a fully Differentiable I2P registration framework, leveraging a novel and effective Diffusion prior for bridging the modality gap. Specifically, we propose a Control-Side Score Distillation (CSD) technique to distill knowledge from a depth-conditioned diffusion model to directly optimize the predicted transformation. However, the gradients on the transformation fail to backpropagate onto the cross-modal features due to the non-differentiability of correspondence retrieval and PnP solver. To this end, we further propose a Deformable Correspondence Tuning (DCT) module to estimate the correspondences in a differentiable way, followed by the transformation estimation using a differentiable PnP solver. With these two designs, the Diffusion model serves as a strong prior to guide the cross-modal feature learning of image and point cloud for forming robust correspondences, which significantly improves the registration. Extensive experimental results demonstrate that Diff$^2$I2P consistently outperforms SoTA I2P registration methods, achieving over 7% improvement in registration recall on the 7-Scenes benchmark.
ReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model
Jun 11, 2025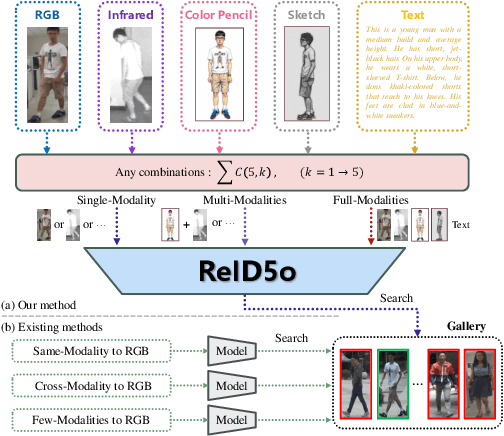
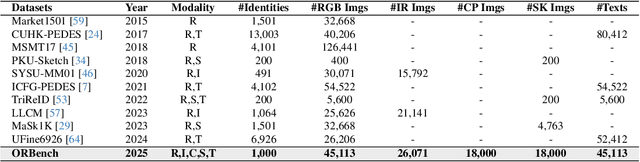
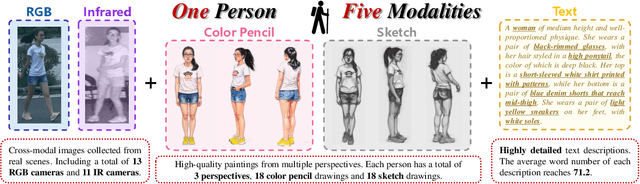
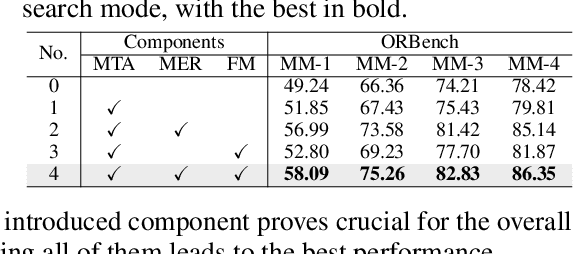
In real-word scenarios, person re-identification (ReID) expects to identify a person-of-interest via the descriptive query, regardless of whether the query is a single modality or a combination of multiple modalities. However, existing methods and datasets remain constrained to limited modalities, failing to meet this requirement. Therefore, we investigate a new challenging problem called Omni Multi-modal Person Re-identification (OM-ReID), which aims to achieve effective retrieval with varying multi-modal queries. To address dataset scarcity, we construct ORBench, the first high-quality multi-modal dataset comprising 1,000 unique identities across five modalities: RGB, infrared, color pencil, sketch, and textual description. This dataset also has significant superiority in terms of diversity, such as the painting perspectives and textual information. It could serve as an ideal platform for follow-up investigations in OM-ReID. Moreover, we propose ReID5o, a novel multi-modal learning framework for person ReID. It enables synergistic fusion and cross-modal alignment of arbitrary modality combinations in a single model, with a unified encoding and multi-expert routing mechanism proposed. Extensive experiments verify the advancement and practicality of our ORBench. A wide range of possible models have been evaluated and compared on it, and our proposed ReID5o model gives the best performance. The dataset and code will be made publicly available at https://github.com/Zplusdragon/ReID5o_ORBench.
TokenHSI: Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization
Mar 25, 2025Synthesizing diverse and physically plausible Human-Scene Interactions (HSI) is pivotal for both computer animation and embodied AI. Despite encouraging progress, current methods mainly focus on developing separate controllers, each specialized for a specific interaction task. This significantly hinders the ability to tackle a wide variety of challenging HSI tasks that require the integration of multiple skills, e.g., sitting down while carrying an object. To address this issue, we present TokenHSI, a single, unified transformer-based policy capable of multi-skill unification and flexible adaptation. The key insight is to model the humanoid proprioception as a separate shared token and combine it with distinct task tokens via a masking mechanism. Such a unified policy enables effective knowledge sharing across skills, thereby facilitating the multi-task training. Moreover, our policy architecture supports variable length inputs, enabling flexible adaptation of learned skills to new scenarios. By training additional task tokenizers, we can not only modify the geometries of interaction targets but also coordinate multiple skills to address complex tasks. The experiments demonstrate that our approach can significantly improve versatility, adaptability, and extensibility in various HSI tasks. Website: https://liangpan99.github.io/TokenHSI/
SuperFlow++: Enhanced Spatiotemporal Consistency for Cross-Modal Data Pretraining
Mar 25, 2025LiDAR representation learning has emerged as a promising approach to reducing reliance on costly and labor-intensive human annotations. While existing methods primarily focus on spatial alignment between LiDAR and camera sensors, they often overlook the temporal dynamics critical for capturing motion and scene continuity in driving scenarios. To address this limitation, we propose SuperFlow++, a novel framework that integrates spatiotemporal cues in both pretraining and downstream tasks using consecutive LiDAR-camera pairs. SuperFlow++ introduces four key components: (1) a view consistency alignment module to unify semantic information across camera views, (2) a dense-to-sparse consistency regularization mechanism to enhance feature robustness across varying point cloud densities, (3) a flow-based contrastive learning approach that models temporal relationships for improved scene understanding, and (4) a temporal voting strategy that propagates semantic information across LiDAR scans to improve prediction consistency. Extensive evaluations on 11 heterogeneous LiDAR datasets demonstrate that SuperFlow++ outperforms state-of-the-art methods across diverse tasks and driving conditions. Furthermore, by scaling both 2D and 3D backbones during pretraining, we uncover emergent properties that provide deeper insights into developing scalable 3D foundation models. With strong generalizability and computational efficiency, SuperFlow++ establishes a new benchmark for data-efficient LiDAR-based perception in autonomous driving. The code is publicly available at https://github.com/Xiangxu-0103/SuperFlow
MotionStreamer: Streaming Motion Generation via Diffusion-based Autoregressive Model in Causal Latent Space
Mar 19, 2025This paper addresses the challenge of text-conditioned streaming motion generation, which requires us to predict the next-step human pose based on variable-length historical motions and incoming texts. Existing methods struggle to achieve streaming motion generation, e.g., diffusion models are constrained by pre-defined motion lengths, while GPT-based methods suffer from delayed response and error accumulation problem due to discretized non-causal tokenization. To solve these problems, we propose MotionStreamer, a novel framework that incorporates a continuous causal latent space into a probabilistic autoregressive model. The continuous latents mitigate information loss caused by discretization and effectively reduce error accumulation during long-term autoregressive generation. In addition, by establishing temporal causal dependencies between current and historical motion latents, our model fully utilizes the available information to achieve accurate online motion decoding. Experiments show that our method outperforms existing approaches while offering more applications, including multi-round generation, long-term generation, and dynamic motion composition. Project Page: https://zju3dv.github.io/MotionStreamer/
LargeAD: Large-Scale Cross-Sensor Data Pretraining for Autonomous Driving
Jan 07, 2025Recent advancements in vision foundation models (VFMs) have revolutionized visual perception in 2D, yet their potential for 3D scene understanding, particularly in autonomous driving applications, remains underexplored. In this paper, we introduce LargeAD, a versatile and scalable framework designed for large-scale 3D pretraining across diverse real-world driving datasets. Our framework leverages VFMs to extract semantically rich superpixels from 2D images, which are aligned with LiDAR point clouds to generate high-quality contrastive samples. This alignment facilitates cross-modal representation learning, enhancing the semantic consistency between 2D and 3D data. We introduce several key innovations: i) VFM-driven superpixel generation for detailed semantic representation, ii) a VFM-assisted contrastive learning strategy to align multimodal features, iii) superpoint temporal consistency to maintain stable representations across time, and iv) multi-source data pretraining to generalize across various LiDAR configurations. Our approach delivers significant performance improvements over state-of-the-art methods in both linear probing and fine-tuning tasks for both LiDAR-based segmentation and object detection. Extensive experiments on eleven large-scale multi-modal datasets highlight our superior performance, demonstrating the adaptability, efficiency, and robustness in real-world autonomous driving scenarios.
LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes
Jan 07, 2025LiDAR data pretraining offers a promising approach to leveraging large-scale, readily available datasets for enhanced data utilization. However, existing methods predominantly focus on sparse voxel representation, overlooking the complementary attributes provided by other LiDAR representations. In this work, we propose LiMoE, a framework that integrates the Mixture of Experts (MoE) paradigm into LiDAR data representation learning to synergistically combine multiple representations, such as range images, sparse voxels, and raw points. Our approach consists of three stages: i) Image-to-LiDAR Pretraining, which transfers prior knowledge from images to point clouds across different representations; ii) Contrastive Mixture Learning (CML), which uses MoE to adaptively activate relevant attributes from each representation and distills these mixed features into a unified 3D network; iii) Semantic Mixture Supervision (SMS), which combines semantic logits from multiple representations to boost downstream segmentation performance. Extensive experiments across 11 large-scale LiDAR datasets demonstrate our effectiveness and superiority. The code and model checkpoints have been made publicly accessible.
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives
Jan 07, 2025



Recent advancements in Vision-Language Models (VLMs) have sparked interest in their use for autonomous driving, particularly in generating interpretable driving decisions through natural language. However, the assumption that VLMs inherently provide visually grounded, reliable, and interpretable explanations for driving remains largely unexamined. To address this gap, we introduce DriveBench, a benchmark dataset designed to evaluate VLM reliability across 17 settings (clean, corrupted, and text-only inputs), encompassing 19,200 frames, 20,498 question-answer pairs, three question types, four mainstream driving tasks, and a total of 12 popular VLMs. Our findings reveal that VLMs often generate plausible responses derived from general knowledge or textual cues rather than true visual grounding, especially under degraded or missing visual inputs. This behavior, concealed by dataset imbalances and insufficient evaluation metrics, poses significant risks in safety-critical scenarios like autonomous driving. We further observe that VLMs struggle with multi-modal reasoning and display heightened sensitivity to input corruptions, leading to inconsistencies in performance. To address these challenges, we propose refined evaluation metrics that prioritize robust visual grounding and multi-modal understanding. Additionally, we highlight the potential of leveraging VLMs' awareness of corruptions to enhance their reliability, offering a roadmap for developing more trustworthy and interpretable decision-making systems in real-world autonomous driving contexts. The benchmark toolkit is publicly accessible.
OVGaussian: Generalizable 3D Gaussian Segmentation with Open Vocabularies
Dec 31, 2024Open-vocabulary scene understanding using 3D Gaussian (3DGS) representations has garnered considerable attention. However, existing methods mostly lift knowledge from large 2D vision models into 3DGS on a scene-by-scene basis, restricting the capabilities of open-vocabulary querying within their training scenes so that lacking the generalizability to novel scenes. In this work, we propose \textbf{OVGaussian}, a generalizable \textbf{O}pen-\textbf{V}ocabulary 3D semantic segmentation framework based on the 3D \textbf{Gaussian} representation. We first construct a large-scale 3D scene dataset based on 3DGS, dubbed \textbf{SegGaussian}, which provides detailed semantic and instance annotations for both Gaussian points and multi-view images. To promote semantic generalization across scenes, we introduce Generalizable Semantic Rasterization (GSR), which leverages a 3D neural network to learn and predict the semantic property for each 3D Gaussian point, where the semantic property can be rendered as multi-view consistent 2D semantic maps. In the next, we propose a Cross-modal Consistency Learning (CCL) framework that utilizes open-vocabulary annotations of 2D images and 3D Gaussians within SegGaussian to train the 3D neural network capable of open-vocabulary semantic segmentation across Gaussian-based 3D scenes. Experimental results demonstrate that OVGaussian significantly outperforms baseline methods, exhibiting robust cross-scene, cross-domain, and novel-view generalization capabilities. Code and the SegGaussian dataset will be released. (https://github.com/runnanchen/OVGaussian).
A Plug-and-Play Physical Motion Restoration Approach for In-the-Wild High-Difficulty Motions
Dec 23, 2024



Extracting physically plausible 3D human motion from videos is a critical task. Although existing simulation-based motion imitation methods can enhance the physical quality of daily motions estimated from monocular video capture, extending this capability to high-difficulty motions remains an open challenge. This can be attributed to some flawed motion clips in video-based motion capture results and the inherent complexity in modeling high-difficulty motions. Therefore, sensing the advantage of segmentation in localizing human body, we introduce a mask-based motion correction module (MCM) that leverages motion context and video mask to repair flawed motions, producing imitation-friendly motions; and propose a physics-based motion transfer module (PTM), which employs a pretrain and adapt approach for motion imitation, improving physical plausibility with the ability to handle in-the-wild and challenging motions. Our approach is designed as a plug-and-play module to physically refine the video motion capture results, including high-difficulty in-the-wild motions. Finally, to validate our approach, we collected a challenging in-the-wild test set to establish a benchmark, and our method has demonstrated effectiveness on both the new benchmark and existing public datasets.https://physicalmotionrestoration.github.io