 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
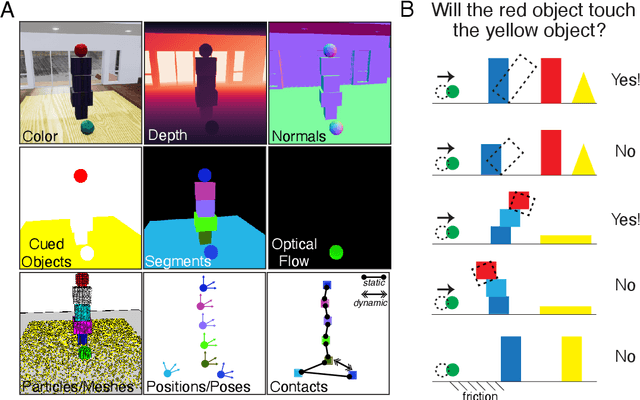
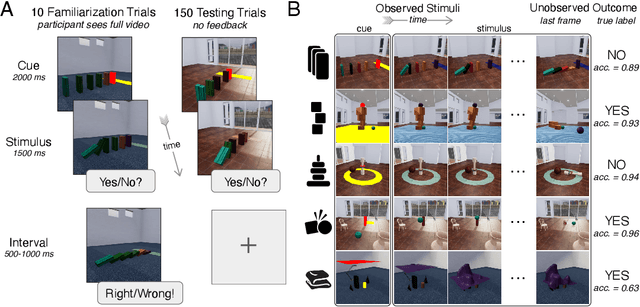
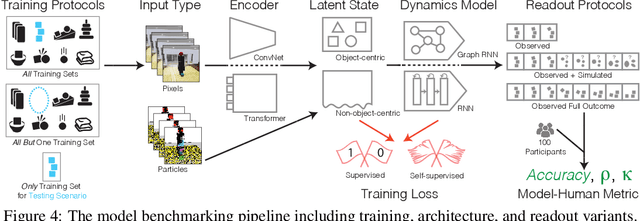
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.
Rethinking Architecture Design for Tackling Data Heterogeneity in Federated Learning
Jun 10, 2021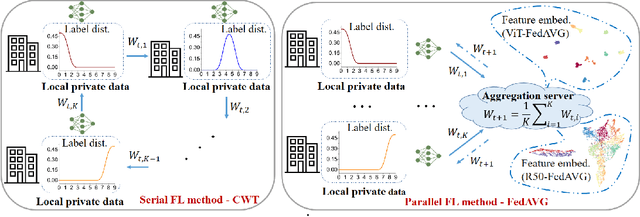
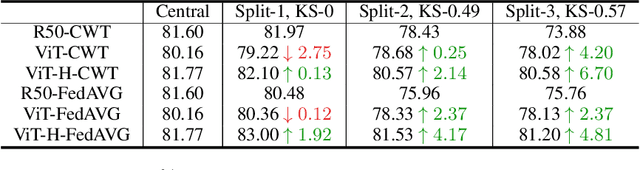
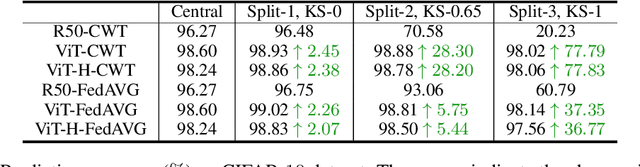

Federated learning is an emerging research paradigm enabling collaborative training of machine learning models among different organizations while keeping data private at each institution. Despite recent progress, there remain fundamental challenges such as lack of convergence and potential for catastrophic forgetting in federated learning across real-world heterogeneous devices. In this paper, we demonstrate that attention-based architectures (e.g., Transformers) are fairly robust to distribution shifts and hence improve federated learning over heterogeneous data. Concretely, we conduct the first rigorous empirical investigation of different neural architectures across a range of federated algorithms, real-world benchmarks, and heterogeneous data splits. Our experiments show that simply replacing convolutional networks with Transformers can greatly reduce catastrophic forgetting of previous devices, accelerate convergence, and reach a better global model, especially when dealing with heterogeneous data. We will release our code and pretrained models at https://github.com/Liangqiong/ViT-FL-main to encourage future exploration in robust architectures as an alternative to current research efforts on the optimization front.
Metadata Normalization
May 05, 2021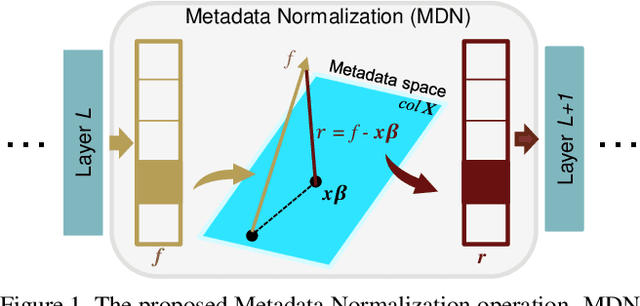
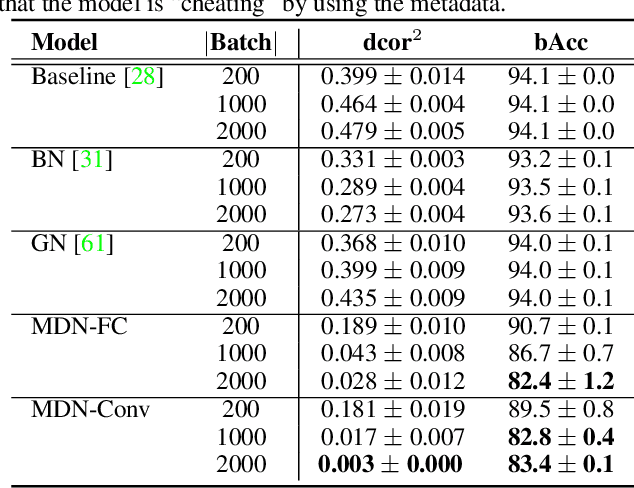

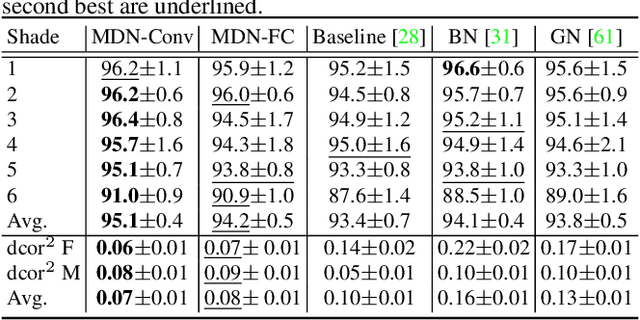
Batch Normalization (BN) and its variants have delivered tremendous success in combating the covariate shift induced by the training step of deep learning methods. While these techniques normalize feature distributions by standardizing with batch statistics, they do not correct the influence on features from extraneous variables or multiple distributions. Such extra variables, referred to as metadata here, may create bias or confounding effects (e.g., race when classifying gender from face images). We introduce the Metadata Normalization (MDN) layer, a new batch-level operation which can be used end-to-end within the training framework, to correct the influence of metadata on feature distributions. MDN adopts a regression analysis technique traditionally used for preprocessing to remove (regress out) the metadata effects on model features during training. We utilize a metric based on distance correlation to quantify the distribution bias from the metadata and demonstrate that our method successfully removes metadata effects on four diverse settings: one synthetic, one 2D image, one video, and one 3D medical image dataset.
Greedy Hierarchical Variational Autoencoders for Large-Scale Video Prediction
Mar 26, 2021
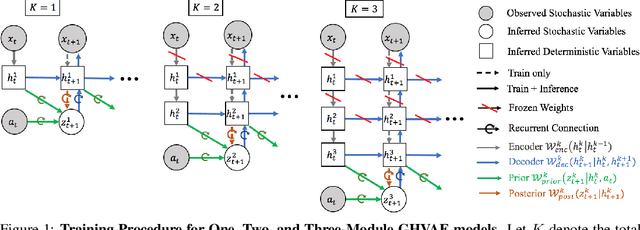

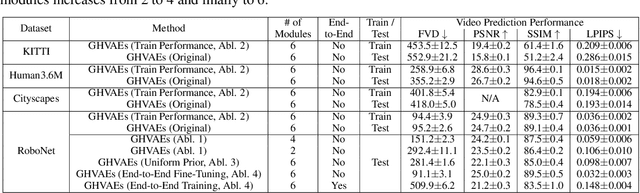
A video prediction model that generalizes to diverse scenes would enable intelligent agents such as robots to perform a variety of tasks via planning with the model. However, while existing video prediction models have produced promising results on small datasets, they suffer from severe underfitting when trained on large and diverse datasets. To address this underfitting challenge, we first observe that the ability to train larger video prediction models is often bottlenecked by the memory constraints of GPUs or TPUs. In parallel, deep hierarchical latent variable models can produce higher quality predictions by capturing the multi-level stochasticity of future observations, but end-to-end optimization of such models is notably difficult. Our key insight is that greedy and modular optimization of hierarchical autoencoders can simultaneously address both the memory constraints and the optimization challenges of large-scale video prediction. We introduce Greedy Hierarchical Variational Autoencoders (GHVAEs), a method that learns high-fidelity video predictions by greedily training each level of a hierarchical autoencoder. In comparison to state-of-the-art models, GHVAEs provide 17-55% gains in prediction performance on four video datasets, a 35-40% higher success rate on real robot tasks, and can improve performance monotonically by simply adding more modules.
A Study of Face Obfuscation in ImageNet
Mar 14, 2021
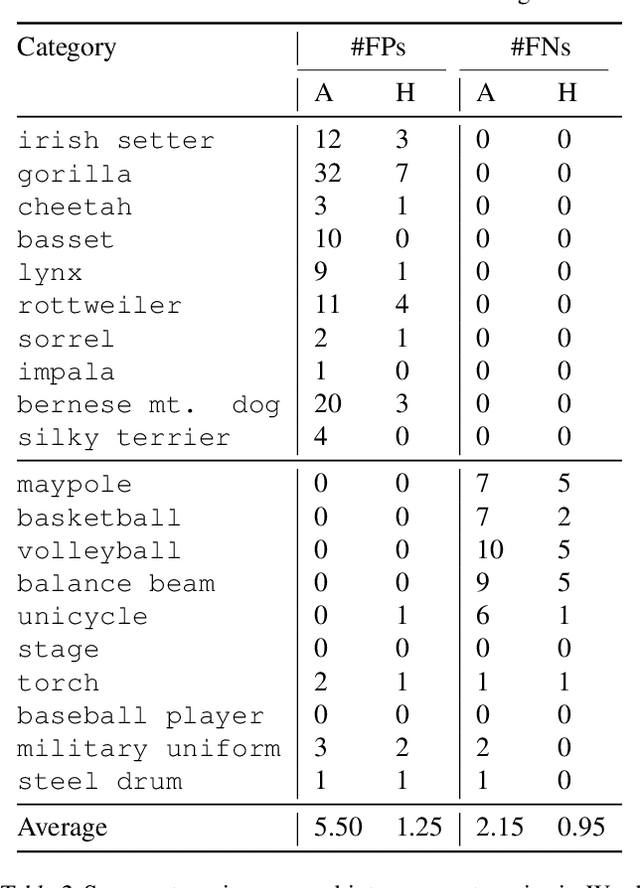
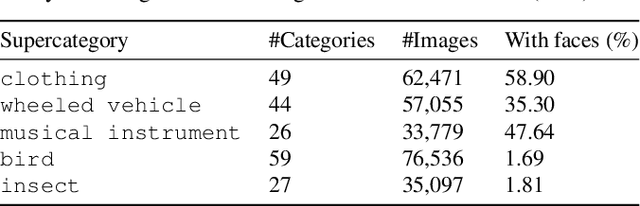
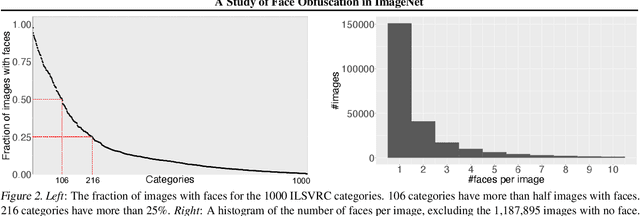
Face obfuscation (blurring, mosaicing, etc.) has been shown to be effective for privacy protection; nevertheless, object recognition research typically assumes access to complete, unobfuscated images. In this paper, we explore the effects of face obfuscation on the popular ImageNet challenge visual recognition benchmark. Most categories in the ImageNet challenge are not people categories; however, many incidental people appear in the images, and their privacy is a concern. We first annotate faces in the dataset. Then we demonstrate that face blurring -- a typical obfuscation technique -- has minimal impact on the accuracy of recognition models. Concretely, we benchmark multiple deep neural networks on face-blurred images and observe that the overall recognition accuracy drops only slightly (no more than 0.68%). Further, we experiment with transfer learning to 4 downstream tasks (object recognition, scene recognition, face attribute classification, and object detection) and show that features learned on face-blurred images are equally transferable. Our work demonstrates the feasibility of privacy-aware visual recognition, improves the highly-used ImageNet challenge benchmark, and suggests an important path for future visual datasets. Data and code are available at https://github.com/princetonvisualai/imagenet-face-obfuscation.
Generalization Through Hand-Eye Coordination: An Action Space for Learning Spatially-Invariant Visuomotor Control
Feb 28, 2021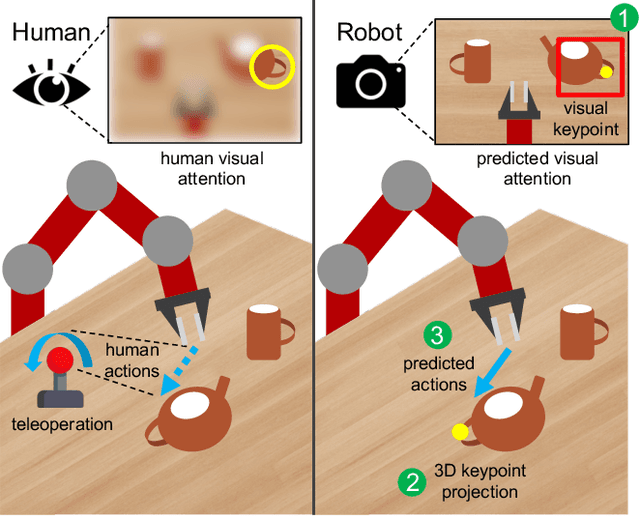
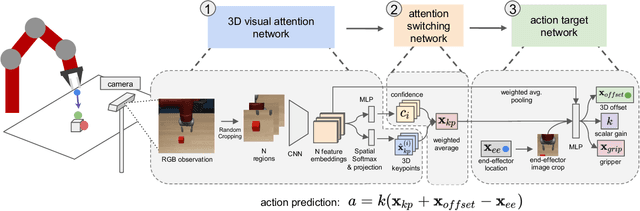
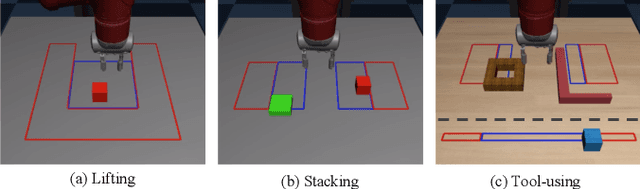
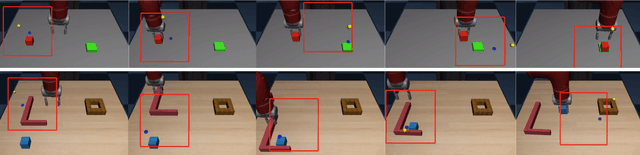
Imitation Learning (IL) is an effective framework to learn visuomotor skills from offline demonstration data. However, IL methods often fail to generalize to new scene configurations not covered by training data. On the other hand, humans can manipulate objects in varying conditions. Key to such capability is hand-eye coordination, a cognitive ability that enables humans to adaptively direct their movements at task-relevant objects and be invariant to the objects' absolute spatial location. In this work, we present a learnable action space, Hand-eye Action Networks (HAN), that can approximate human's hand-eye coordination behaviors by learning from human teleoperated demonstrations. Through a set of challenging multi-stage manipulation tasks, we show that a visuomotor policy equipped with HAN is able to inherit the key spatial invariance property of hand-eye coordination and achieve zero-shot generalization to new scene configurations. Additional materials available at https://sites.google.com/stanford.edu/han
Embodied Intelligence via Learning and Evolution
Feb 03, 2021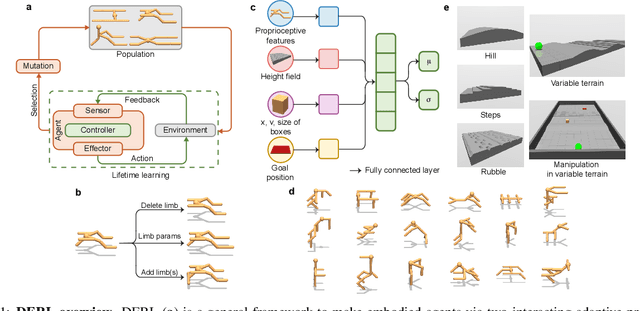

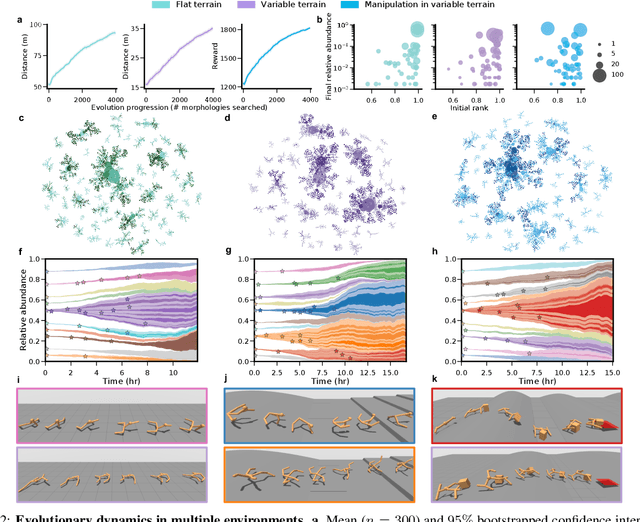
The intertwined processes of learning and evolution in complex environmental niches have resulted in a remarkable diversity of morphological forms. Moreover, many aspects of animal intelligence are deeply embodied in these evolved morphologies. However, the principles governing relations between environmental complexity, evolved morphology, and the learnability of intelligent control, remain elusive, partially due to the substantial challenge of performing large-scale in silico experiments on evolution and learning. We introduce Deep Evolutionary Reinforcement Learning (DERL): a novel computational framework which can evolve diverse agent morphologies to learn challenging locomotion and manipulation tasks in complex environments using only low level egocentric sensory information. Leveraging DERL we demonstrate several relations between environmental complexity, morphological intelligence and the learnability of control. First, environmental complexity fosters the evolution of morphological intelligence as quantified by the ability of a morphology to facilitate the learning of novel tasks. Second, evolution rapidly selects morphologies that learn faster, thereby enabling behaviors learned late in the lifetime of early ancestors to be expressed early in the lifetime of their descendants. In agents that learn and evolve in complex environments, this result constitutes the first demonstration of a long-conjectured morphological Baldwin effect. Third, our experiments suggest a mechanistic basis for both the Baldwin effect and the emergence of morphological intelligence through the evolution of morphologies that are more physically stable and energy efficient, and can therefore facilitate learning and control.
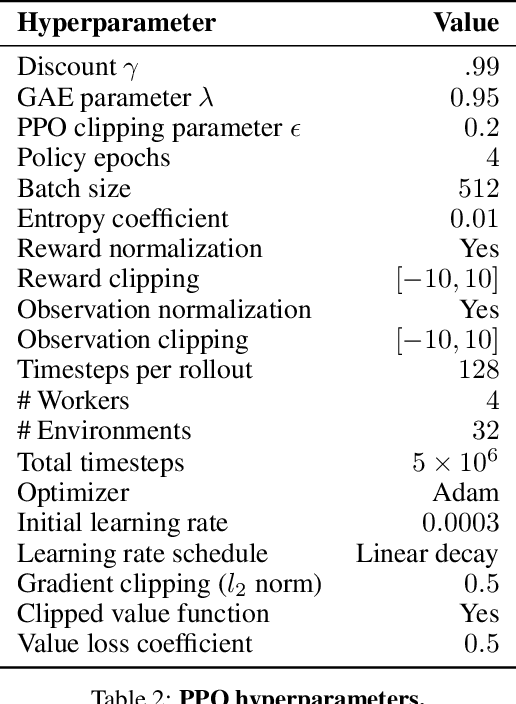
Learning Multi-Arm Manipulation Through Collaborative Teleoperation
Dec 12, 2020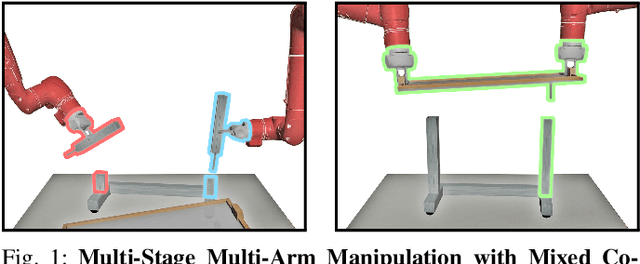

Imitation Learning (IL) is a powerful paradigm to teach robots to perform manipulation tasks by allowing them to learn from human demonstrations collected via teleoperation, but has mostly been limited to single-arm manipulation. However, many real-world tasks require multiple arms, such as lifting a heavy object or assembling a desk. Unfortunately, applying IL to multi-arm manipulation tasks has been challenging -- asking a human to control more than one robotic arm can impose significant cognitive burden and is often only possible for a maximum of two robot arms. To address these challenges, we present Multi-Arm RoboTurk (MART), a multi-user data collection platform that allows multiple remote users to simultaneously teleoperate a set of robotic arms and collect demonstrations for multi-arm tasks. Using MART, we collected demonstrations for five novel two and three-arm tasks from several geographically separated users. From our data we arrived at a critical insight: most multi-arm tasks do not require global coordination throughout its full duration, but only during specific moments. We show that learning from such data consequently presents challenges for centralized agents that directly attempt to model all robot actions simultaneously, and perform a comprehensive study of different policy architectures with varying levels of centralization on our tasks. Finally, we propose and evaluate a base-residual policy framework that allows trained policies to better adapt to the mixed coordination setting common in multi-arm manipulation, and show that a centralized policy augmented with a decentralized residual model outperforms all other models on our set of benchmark tasks. Additional results and videos at https://roboturk.stanford.edu/multiarm .
Human-in-the-Loop Imitation Learning using Remote Teleoperation
Dec 12, 2020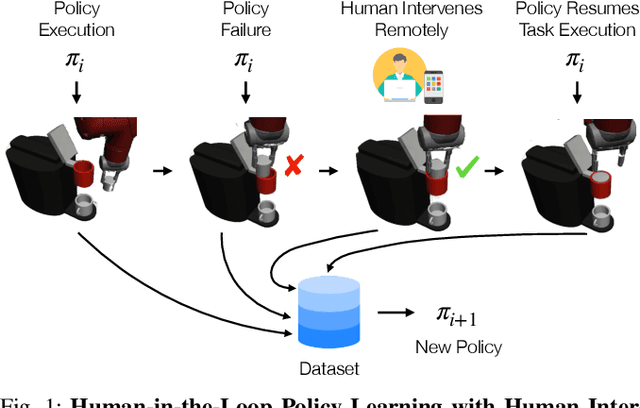

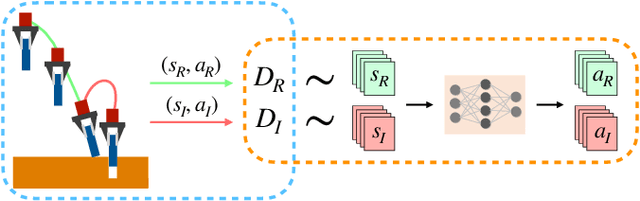

Imitation Learning is a promising paradigm for learning complex robot manipulation skills by reproducing behavior from human demonstrations. However, manipulation tasks often contain bottleneck regions that require a sequence of precise actions to make meaningful progress, such as a robot inserting a pod into a coffee machine to make coffee. Trained policies can fail in these regions because small deviations in actions can lead the policy into states not covered by the demonstrations. Intervention-based policy learning is an alternative that can address this issue -- it allows human operators to monitor trained policies and take over control when they encounter failures. In this paper, we build a data collection system tailored to 6-DoF manipulation settings, that enables remote human operators to monitor and intervene on trained policies. We develop a simple and effective algorithm to train the policy iteratively on new data collected by the system that encourages the policy to learn how to traverse bottlenecks through the interventions. We demonstrate that agents trained on data collected by our intervention-based system and algorithm outperform agents trained on an equivalent number of samples collected by non-interventional demonstrators, and further show that our method outperforms multiple state-of-the-art baselines for learning from the human interventions on a challenging robot threading task and a coffee making task. Additional results and videos at https://sites.google.com/stanford.edu/iwr .
iGibson, a Simulation Environment for Interactive Tasks in Large Realistic Scenes
Dec 08, 2020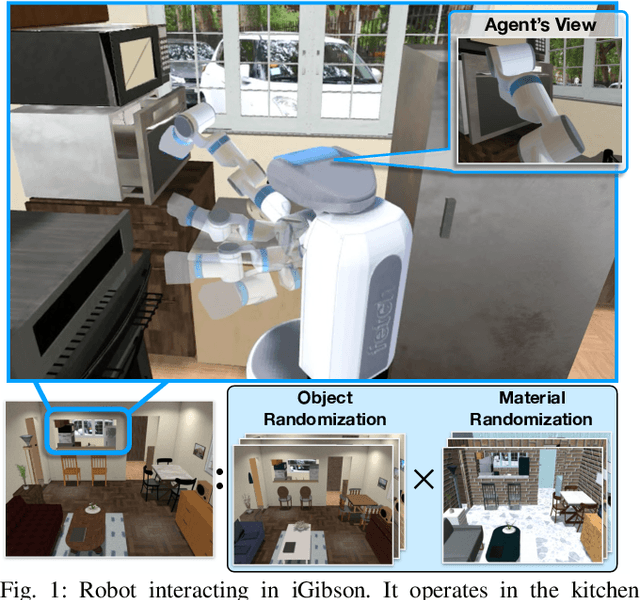
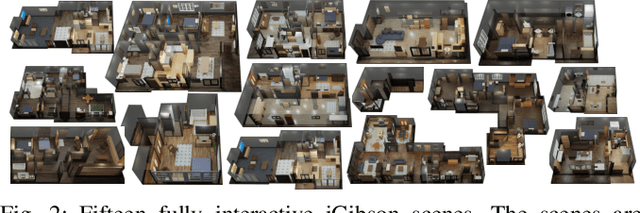


We present iGibson, a novel simulation environment to develop robotic solutions for interactive tasks in large-scale realistic scenes. Our environment contains fifteen fully interactive home-sized scenes populated with rigid and articulated objects. The scenes are replicas of 3D scanned real-world homes, aligning the distribution of objects and layout to that of the real world. iGibson integrates several key features to facilitate the study of interactive tasks: i) generation of high-quality visual virtual sensor signals (RGB, depth, segmentation, LiDAR, flow, among others), ii) domain randomization to change the materials of the objects (both visual texture and dynamics) and/or their shapes, iii) integrated sampling-based motion planners to generate collision-free trajectories for robot bases and arms, and iv) intuitive human-iGibson interface that enables efficient collection of human demonstrations. Through experiments, we show that the full interactivity of the scenes enables agents to learn useful visual representations that accelerate the training of downstream manipulation tasks. We also show that iGibson features enable the generalization of navigation agents, and that the human-iGibson interface and integrated motion planners facilitate efficient imitation learning of simple human demonstrated behaviors. iGibson is open-sourced with comprehensive examples and documentation. For more information, visit our project website: http://svl.stanford.edu/igibson/