 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGibson, a Simulation Environment for Interactive Tasks in Large Realistic Scenes
Dec 08, 2020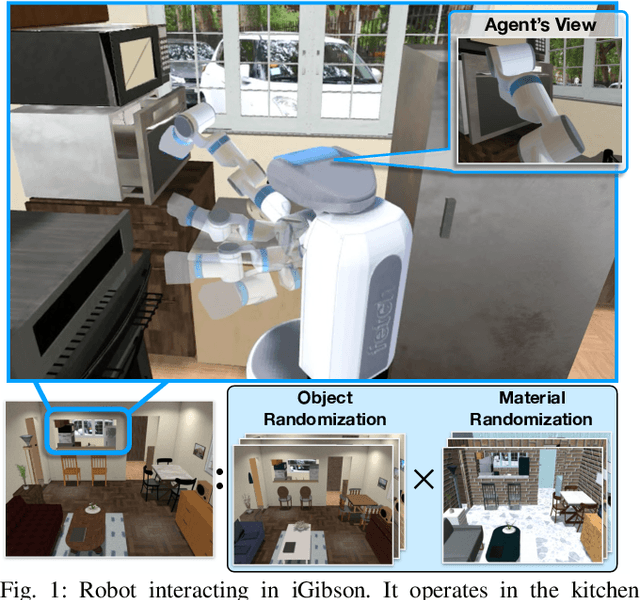
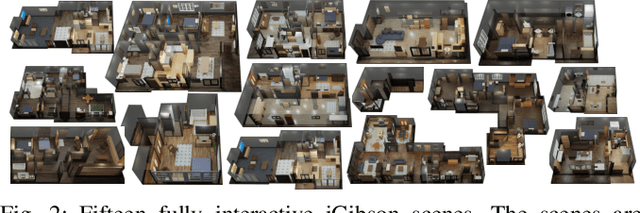


We present iGibson, a novel simulation environment to develop robotic solutions for interactive tasks in large-scale realistic scenes. Our environment contains fifteen fully interactive home-sized scenes populated with rigid and articulated objects. The scenes are replicas of 3D scanned real-world homes, aligning the distribution of objects and layout to that of the real world. iGibson integrates several key features to facilitate the study of interactive tasks: i) generation of high-quality visual virtual sensor signals (RGB, depth, segmentation, LiDAR, flow, among others), ii) domain randomization to change the materials of the objects (both visual texture and dynamics) and/or their shapes, iii) integrated sampling-based motion planners to generate collision-free trajectories for robot bases and arms, and iv) intuitive human-iGibson interface that enables efficient collection of human demonstrations. Through experiments, we show that the full interactivity of the scenes enables agents to learn useful visual representations that accelerate the training of downstream manipulation tasks. We also show that iGibson features enable the generalization of navigation agents, and that the human-iGibson interface and integrated motion planners facilitate efficient imitation learning of simple human demonstrated behaviors. iGibson is open-sourced with comprehensive examples and documentation. For more information, visit our project website: http://svl.stanford.edu/igibson/
Machine Vision for Natural Gas Methane Emissions Detection Using an Infrared Camera
Apr 01, 2019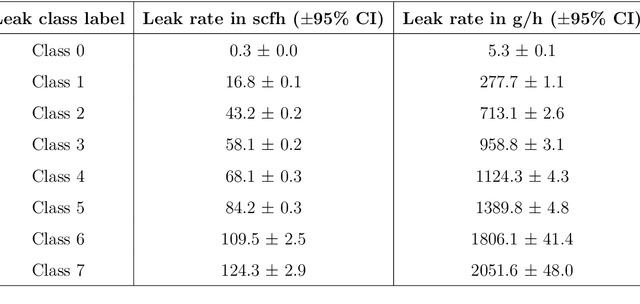


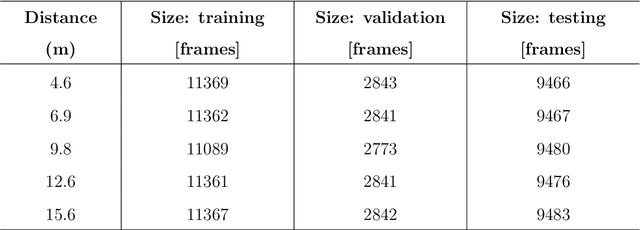
It is crucial to reduce natural gas methane emissions, which can potentially offset the climate benefits of replacing coal with gas. Optical gas imaging (OGI) is a widely-used method to detect methane leaks, but is labor-intensive and cannot provide leak detection results without operators' judgment. In this paper, we develop a computer vision approach to OGI-based leak detection using convolutional neural networks (CNN) trained on methane leak images to enable automatic detection. First, we collect ~1 M frames of labeled video of methane leaks from different leaking equipment for building CNN model, covering a wide range of leak sizes (5.3-2051.6 gCH4/h) and imaging distances (4.6-15.6 m). Second, we examine different background subtraction methods to extract the methane plume in the foreground. Third, we then test three CNN model variants, collectively called GasNet, to detect plumes in videos taken at other pieces of leaking equipment. We assess the ability of GasNet to perform leak detection by comparing it to a baseline method that uses optical-flow based change detection algorithm. We explore the sensitivity of results to the CNN structure, with a moderate-complexity variant performing best across distances. We find that the detection accuracy can reach as high as 99%, the overall detection accuracy can exceed 95% for a case across all leak sizes and imaging distances. Binary detection accuracy exceeds 97% for large leaks (~710 gCH4/h) imaged closely (~5-7 m). At closer imaging distances (~5-10 m), CNN-based models have greater than 94% accuracy across all leak sizes. At farthest distances (~13-16 m), performance degrades rapidly, but it can achieve above 95% accuracy to detect large leaks (>950 gCH4/h). The GasNet-based computer vision approach could be deployed in OGI surveys to allow automatic vigilance of methane leak detection with high detection accuracy in the real world.
SEGCloud: Semantic Segmentation of 3D Point Clouds
Oct 20, 2017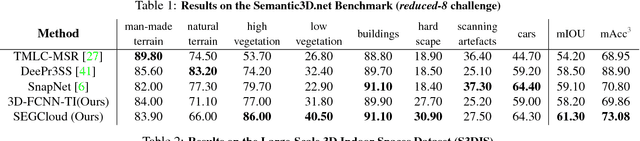
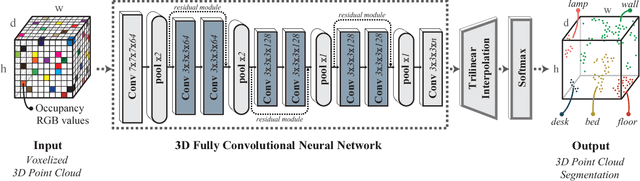
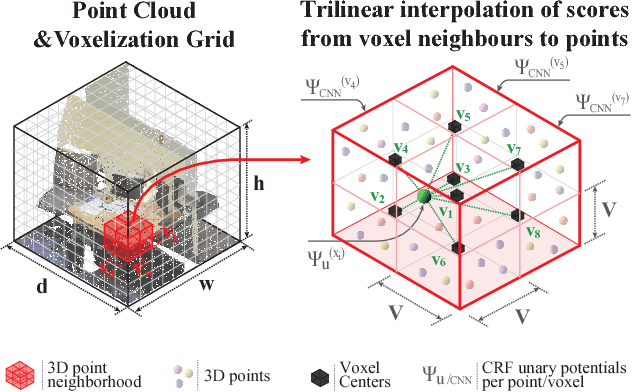

3D semantic scene labeling is fundamental to agents operating in the real world. In particular, labeling raw 3D point sets from sensors provides fine-grained semantics. Recent works leverage the capabilities of Neural Networks (NNs), but are limited to coarse voxel predictions and do not explicitly enforce global consistency. We present SEGCloud, an end-to-end framework to obtain 3D point-level segmentation that combines the advantages of NNs, trilinear interpolation(TI) and fully connected Conditional Random Fields (FC-CRF). Coarse voxel predictions from a 3D Fully Convolutional NN are transferred back to the raw 3D points via trilinear interpolation. Then the FC-CRF enforces global consistency and provides fine-grained semantics on the points. We implement the latter as a differentiable Recurrent NN to allow joint optimization. We evaluate the framework on two indoor and two outdoor 3D datasets (NYU V2, S3DIS, KITTI, Semantic3D.net), and show performance comparable or superior to the state-of-the-art on all datasets.