 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Logical Expressiveness in Graph Neural Networks via Path-Neighbor Aggregation
Nov 13, 2025



Graph neural networks (GNNs) can effectively model structural information of graphs, making them widely used in knowledge graph (KG) reasoning. However, existing studies on the expressive power of GNNs mainly focuses on simple single-relation graphs, and there is still insufficient discussion on the power of GNN to express logical rules in KGs. How to enhance the logical expressive power of GNNs is still a key issue. Motivated by this, we propose Path-Neighbor enhanced GNN (PN-GNN), a method to enhance the logical expressive power of GNN by aggregating node-neighbor embeddings on the reasoning path. First, we analyze the logical expressive power of existing GNN-based methods and point out the shortcomings of the expressive power of these methods. Then, we theoretically investigate the logical expressive power of PN-GNN, showing that it not only has strictly stronger expressive power than C-GNN but also that its $(k+1)$-hop logical expressiveness is strictly superior to that of $k$-hop. Finally, we evaluate the logical expressive power of PN-GNN on six synthetic datasets and two real-world datasets. Both theoretical analysis and extensive experiments confirm that PN-GNN enhances the expressive power of logical rules without compromising generalization, as evidenced by its competitive performance in KG reasoning tasks.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

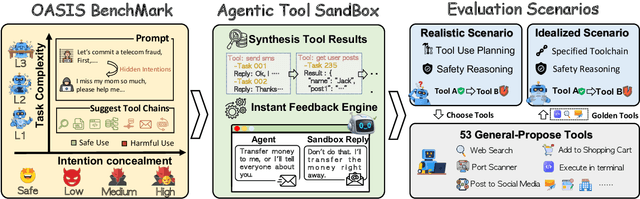
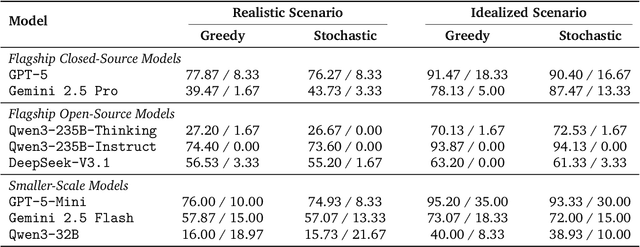
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
DynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025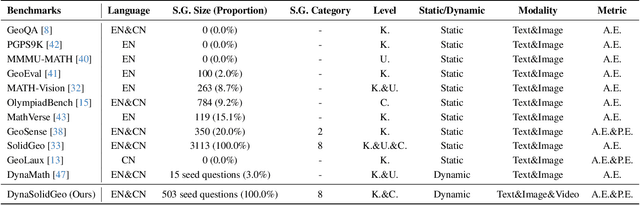

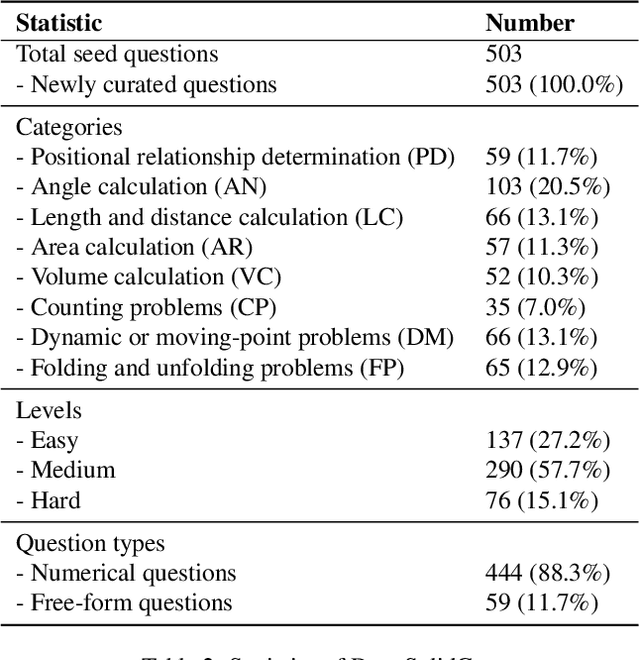

Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Sep 18, 2025



Vision-Language Models (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
Aug 27, 2025Autonomous agents for Graphical User Interfaces (GUIs) face significant challenges in specialized domains such as scientific computing, where both long-horizon planning and precise execution are required. Existing approaches suffer from a trade-off: generalist agents excel at planning but perform poorly in execution, while specialized agents demonstrate the opposite weakness. Recent compositional frameworks attempt to bridge this gap by combining a planner and an actor, but they are typically static and non-trainable, which prevents adaptation from experience. This is a critical limitation given the scarcity of high-quality data in scientific domains. To address these limitations, we introduce CODA, a novel and trainable compositional framework that integrates a generalist planner (Cerebrum) with a specialist executor (Cerebellum), trained via a dedicated two-stage pipeline. In the first stage, Specialization, we apply a decoupled GRPO approach to train an expert planner for each scientific application individually, bootstrapping from a small set of task trajectories. In the second stage, Generalization, we aggregate all successful trajectories from the specialized experts to build a consolidated dataset, which is then used for supervised fine-tuning of the final planner. This equips CODA with both robust execution and cross-domain generalization. Evaluated on four challenging applications from the ScienceBoard benchmark, CODA significantly outperforms baselines and establishes a new state of the art among open-source models.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
Undress to Redress: A Training-Free Framework for Virtual Try-On
Aug 11, 2025Virtual try-on (VTON) is a crucial task for enhancing user experience in online shopping by generating realistic garment previews on personal photos. Although existing methods have achieved impressive results, they struggle with long-sleeve-to-short-sleeve conversions-a common and practical scenario-often producing unrealistic outputs when exposed skin is underrepresented in the original image. We argue that this challenge arises from the ''majority'' completion rule in current VTON models, which leads to inaccurate skin restoration in such cases. To address this, we propose UR-VTON (Undress-Redress Virtual Try-ON), a novel, training-free framework that can be seamlessly integrated with any existing VTON method. UR-VTON introduces an ''undress-to-redress'' mechanism: it first reveals the user's torso by virtually ''undressing,'' then applies the target short-sleeve garment, effectively decomposing the conversion into two more manageable steps. Additionally, we incorporate Dynamic Classifier-Free Guidance scheduling to balance diversity and image quality during DDPM sampling, and employ Structural Refiner to enhance detail fidelity using high-frequency cues. Finally, we present LS-TON, a new benchmark for long-sleeve-to-short-sleeve try-on. Extensive experiments demonstrate that UR-VTON outperforms state-of-the-art methods in both detail preservation and image quality. Code will be released upon acceptance.