 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Priors Guided Lung Disease Detection in 3D CT Scans
Mar 17, 2026Accurate classification of lung diseases from chest CT scans plays an important role in computer-aided diagnosis systems. However, medical imaging datasets often suffer from severe class imbalance, which may significantly degrade the performance of deep learning models, especially for minority disease categories. To address this issue, we propose a gender-aware two-stage lung disease classification framework. The proposed approach explicitly incorporates gender information into the disease recognition pipeline. In the first stage, a gender classifier is trained to predict the patient's gender from CT scans. In the second stage, the input CT image is routed to a corresponding gender-specific disease classifier to perform final disease prediction. This design enables the model to better capture gender-related imaging characteristics and alleviate the influence of imbalanced data distribution. Experimental results demonstrate that the proposed method improves the recognition performance for minority disease categories, particularly squamous cell carcinoma, while maintaining competitive performance on other classes.
Vision-Language Model Based Multi-Expert Fusion for CT Image Classification
Mar 16, 2026Robust detection of COVID-19 from chest CT remains challenging in multi-institutional settings due to substantial source shift, source imbalance, and hidden test-source identities. In this work, we propose a three-stage source-aware multi-expert framework for multi-source COVID-19 CT classification. First, we build a lung-aware 3D expert by combining original CT volumes and lung-extracted CT volumes for volumetric classification. Second, we develop two MedSigLIP-based experts: a slice-wise representation and probability learning module, and a Transformer-based inter-slice context modeling module for capturing cross-slice dependency. Third, we train a source classifier to predict the latent source identity of each test scan. By leveraging the predicted source information, we perform model fusion and voting based on different experts. On the validation set covering all four sources, the Stage 1 model achieves the best macro-F1 of 0.9711, ACC of 0.9712, and AUC of 0.9791. Stage~2a and Stage~2b achieve the best AUC scores of 0.9864 and 0.9854, respectively. Stage~3 source classifier reaches 0.9107 ACC and 0.9114 F1. These results demonstrate that source-aware expert modeling and hierarchical voting provide an effective solution for robust COVID-19 CT classification under heterogeneous multi-source conditions.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

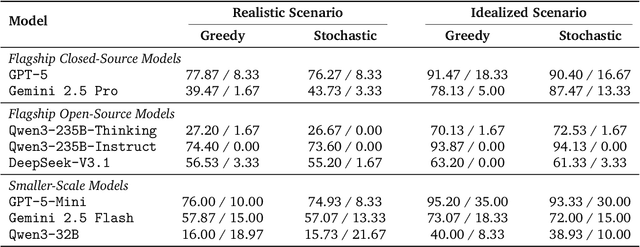
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.
Advancing Lung Disease Diagnosis in 3D CT Scans
Jul 01, 2025To enable more accurate diagnosis of lung disease in chest CT scans, we propose a straightforward yet effective model. Firstly, we analyze the characteristics of 3D CT scans and remove non-lung regions, which helps the model focus on lesion-related areas and reduces computational cost. We adopt ResNeSt50 as a strong feature extractor, and use a weighted cross-entropy loss to mitigate class imbalance, especially for the underrepresented squamous cell carcinoma category. Our model achieves a Macro F1 Score of 0.80 on the validation set of the Fair Disease Diagnosis Challenge, demonstrating its strong performance in distinguishing between different lung conditions.
CorBenchX: Large-Scale Chest X-Ray Error Dataset and Vision-Language Model Benchmark for Report Error Correction
May 17, 2025AI-driven models have shown great promise in detecting errors in radiology reports, yet the field lacks a unified benchmark for rigorous evaluation of error detection and further correction. To address this gap, we introduce CorBenchX, a comprehensive suite for automated error detection and correction in chest X-ray reports, designed to advance AI-assisted quality control in clinical practice. We first synthesize a large-scale dataset of 26,326 chest X-ray error reports by injecting clinically common errors via prompting DeepSeek-R1, with each corrupted report paired with its original text, error type, and human-readable description. Leveraging this dataset, we benchmark both open- and closed-source vision-language models,(e.g., InternVL, Qwen-VL, GPT-4o, o4-mini, and Claude-3.7) for error detection and correction under zero-shot prompting. Among these models, o4-mini achieves the best performance, with 50.6 % detection accuracy and correction scores of BLEU 0.853, ROUGE 0.924, BERTScore 0.981, SembScore 0.865, and CheXbertF1 0.954, remaining below clinical-level accuracy, highlighting the challenge of precise report correction. To advance the state of the art, we propose a multi-step reinforcement learning (MSRL) framework that optimizes a multi-objective reward combining format compliance, error-type accuracy, and BLEU similarity. We apply MSRL to QwenVL2.5-7B, the top open-source model in our benchmark, achieving an improvement of 38.3% in single-error detection precision and 5.2% in single-error correction over the zero-shot baseline.
AOR: Anatomical Ontology-Guided Reasoning for Medical Large Multimodal Model in Chest X-Ray Interpretation
May 05, 2025Chest X-rays (CXRs) are the most frequently performed imaging examinations in clinical settings. Recent advancements in Large Multimodal Models (LMMs) have enabled automated CXR interpretation, enhancing diagnostic accuracy and efficiency. However, despite their strong visual understanding, current Medical LMMs (MLMMs) still face two major challenges: (1) Insufficient region-level understanding and interaction, and (2) Limited accuracy and interpretability due to single-step reasoning. In this paper, we empower MLMMs with anatomy-centric reasoning capabilities to enhance their interactivity and explainability. Specifically, we first propose an Anatomical Ontology-Guided Reasoning (AOR) framework, which centers on cross-modal region-level information to facilitate multi-step reasoning. Next, under the guidance of expert physicians, we develop AOR-Instruction, a large instruction dataset for MLMMs training. Our experiments demonstrate AOR's superior performance in both VQA and report generation tasks.
EgoExo-Gen: Ego-centric Video Prediction by Watching Exo-centric Videos
Apr 16, 2025



Generating videos in the first-person perspective has broad application prospects in the field of augmented reality and embodied intelligence. In this work, we explore the cross-view video prediction task, where given an exo-centric video, the first frame of the corresponding ego-centric video, and textual instructions, the goal is to generate futur frames of the ego-centric video. Inspired by the notion that hand-object interactions (HOI) in ego-centric videos represent the primary intentions and actions of the current actor, we present EgoExo-Gen that explicitly models the hand-object dynamics for cross-view video prediction. EgoExo-Gen consists of two stages. First, we design a cross-view HOI mask prediction model that anticipates the HOI masks in future ego-frames by modeling the spatio-temporal ego-exo correspondence. Next, we employ a video diffusion model to predict future ego-frames using the first ego-frame and textual instructions, while incorporating the HOI masks as structural guidance to enhance prediction quality. To facilitate training, we develop an automated pipeline to generate pseudo HOI masks for both ego- and exo-videos by exploiting vision foundation models. Extensive experiments demonstrate that our proposed EgoExo-Gen achieves better prediction performance compared to previous video prediction models on the Ego-Exo4D and H2O benchmark datasets, with the HOI masks significantly improving the generation of hands and interactive objects in the ego-centric videos.
UGNA-VPR: A Novel Training Paradigm for Visual Place Recognition Based on Uncertainty-Guided NeRF Augmentation
Mar 27, 2025



Visual place recognition (VPR) is crucial for robots to identify previously visited locations, playing an important role in autonomous navigation in both indoor and outdoor environments. However, most existing VPR datasets are limited to single-viewpoint scenarios, leading to reduced recognition accuracy, particularly in multi-directional driving or feature-sparse scenes. Moreover, obtaining additional data to mitigate these limitations is often expensive. This paper introduces a novel training paradigm to improve the performance of existing VPR networks by enhancing multi-view diversity within current datasets through uncertainty estimation and NeRF-based data augmentation. Specifically, we initially train NeRF using the existing VPR dataset. Then, our devised self-supervised uncertainty estimation network identifies places with high uncertainty. The poses of these uncertain places are input into NeRF to generate new synthetic observations for further training of VPR networks. Additionally, we propose an improved storage method for efficient organization of augmented and original training data. We conducted extensive experiments on three datasets and tested three different VPR backbone networks. The results demonstrate that our proposed training paradigm significantly improves VPR performance by fully utilizing existing data, outperforming other training approaches. We further validated the effectiveness of our approach on self-recorded indoor and outdoor datasets, consistently demonstrating superior results. Our dataset and code have been released at \href{https://github.com/nubot-nudt/UGNA-VPR}{https://github.com/nubot-nudt/UGNA-VPR}.
Advancing COVID-19 Detection in 3D CT Scans
Mar 18, 2024


To make a more accurate diagnosis of COVID-19, we propose a straightforward yet effective model. Firstly, we analyse the characteristics of 3D CT scans and remove the non-lung parts, facilitating the model to focus on lesion-related areas and reducing computational cost. We use ResNeSt50 as the strong feature extractor, initializing it with pretrained weights which have COVID-19-specific prior knowledge. Our model achieves a Macro F1 Score of 0.94 on the validation set of the 4th COV19D Competition Challenge $\mathrm{I}$, surpassing the baseline by 16%. This indicates its effectiveness in distinguishing between COVID-19 and non-COVID-19 cases, making it a robust method for COVID-19 detection.
Domain Adaptation Using Pseudo Labels for COVID-19 Detection
Mar 18, 2024

In response to the need for rapid and accurate COVID-19 diagnosis during the global pandemic, we present a two-stage framework that leverages pseudo labels for domain adaptation to enhance the detection of COVID-19 from CT scans. By utilizing annotated data from one domain and non-annotated data from another, the model overcomes the challenge of data scarcity and variability, common in emergent health crises. The innovative approach of generating pseudo labels enables the model to iteratively refine its learning process, thereby improving its accuracy and adaptability across different hospitals and medical centres. Experimental results on COV19-CT-DB database showcase the model's potential to achieve high diagnostic precision, significantly contributing to efficient patient management and alleviating the strain on healthcare systems. Our method achieves 0.92 Macro F1 Score on the validation set of Covid-19 domain adaptation challenge.