 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Representation Learning on Large-Scale Bipartite Graphs
Jun 27, 2019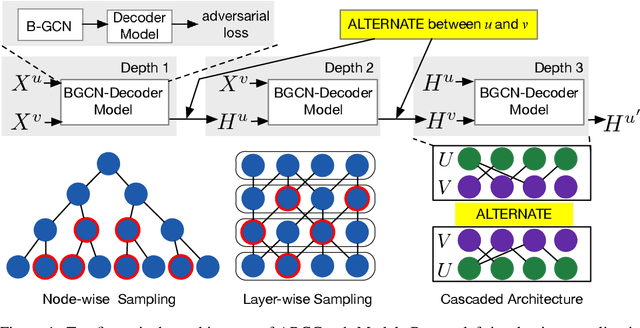
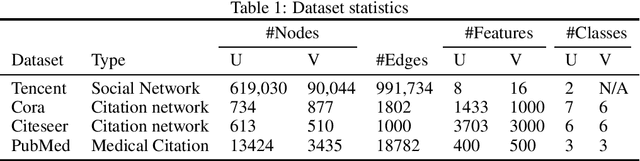
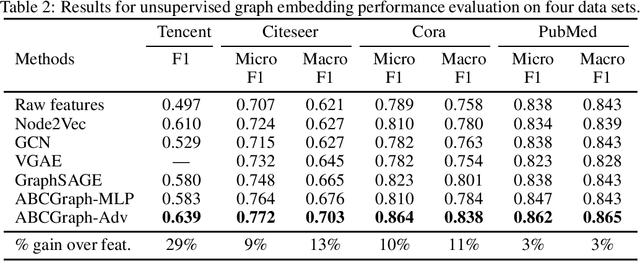
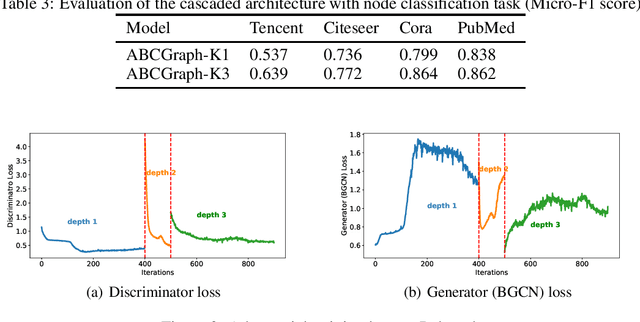
Graph representation on large-scale bipartite graphs is central for a variety of applications, ranging from social network analysis to recommendation system development. Existing methods exhibit two key drawbacks: 1. unable to characterize the inconsistency of the node features within the bipartite-specific structure; 2. unfriendly to support large-scale bipartite graphs. To this end, we propose ABCGraph, a scalable model for unsupervised learning on large-scale bipartite graphs. At its heart, ABCGraph utilizes the proposed Bipartite Graph Convolutional Network (BGCN) as the encoder and adversarial learning as the training loss to learn representations from nodes in two different domains and bipartite structures, in an unsupervised manner. Moreover, we devise a cascaded architecture to capture the multi-hop relationship in bipartite structure and improves the scalability as well. Extensive experiments on multiple datasets of varying scales verify the effectiveness of ABCGraph compared to state-of-the-arts. For the experiment on a real-world large-scale bipartite graph system, fast training speed and low memory cost demonstrate the scalability of ABCGraph model.
Semi-supervised Learning with Contrastive Predicative Coding
May 25, 2019

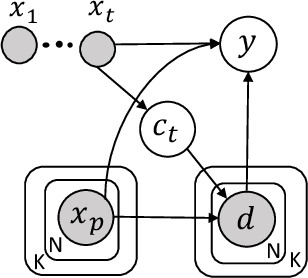
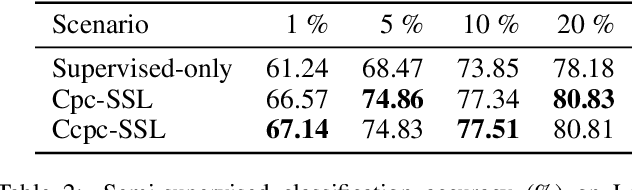
Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, many of them have thus far been either inflexible, inefficient or non-scalable. This paper explores recently developed contrastive predictive coding technique to improve discriminative power of deep learning models when a large portion of labels are absent. Two models, cpc-SSL and a class conditional variant~(ccpc-SSL) are presented. They effectively exploit the unlabeled data by extracting shared information between different parts of the (high-dimensional) data. The proposed approaches are inductive, and scale well to very large datasets like ImageNet, making them good candidates in real-world large scale applications.
RaFM: Rank-Aware Factorization Machines
May 18, 2019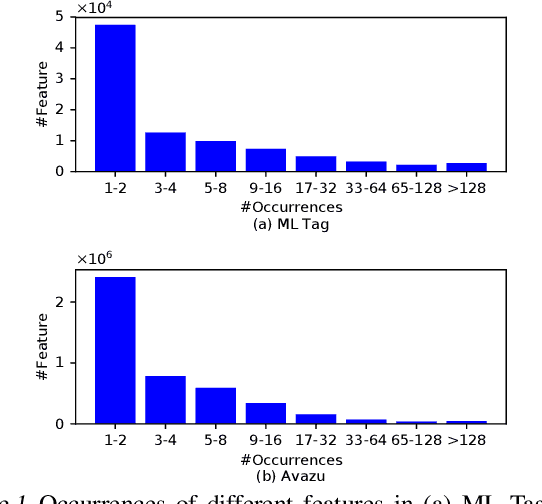

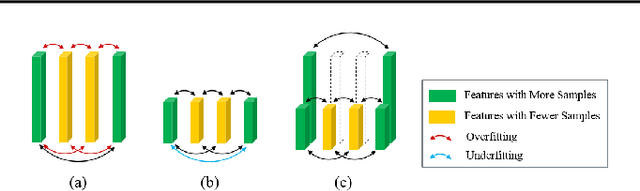
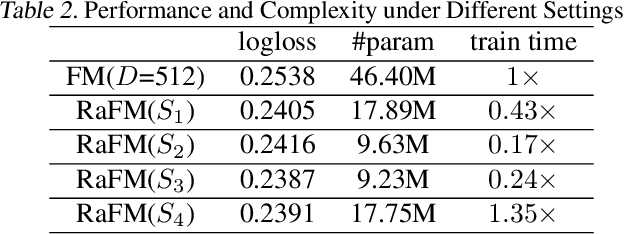
Factorization machines (FM) are a popular model class to learn pairwise interactions by a low-rank approximation. Different from existing FM-based approaches which use a fixed rank for all features, this paper proposes a Rank-Aware FM (RaFM) model which adopts pairwise interactions from embeddings with different ranks. The proposed model achieves a better performance on real-world datasets where different features have significantly varying frequencies of occurrences. Moreover, we prove that the RaFM model can be stored, evaluated, and trained as efficiently as one single FM, and under some reasonable conditions it can be even significantly more efficient than FM. RaFM improves the performance of FMs in both regression tasks and classification tasks while incurring less computational burden, therefore also has attractive potential in industrial applications.
Hierarchically Structured Meta-learning
May 13, 2019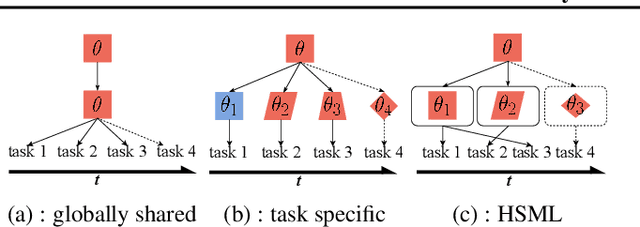
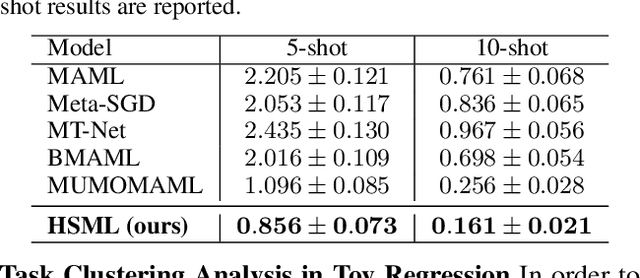
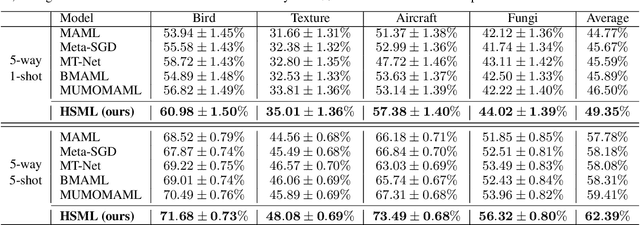
In order to learn quickly with few samples, meta-learning utilizes prior knowledge learned from previous tasks. However, a critical challenge in meta-learning is task uncertainty and heterogeneity, which can not be handled via globally sharing knowledge among tasks. In this paper, based on gradient-based meta-learning, we propose a hierarchically structured meta-learning (HSML) algorithm that explicitly tailors the transferable knowledge to different clusters of tasks. Inspired by the way human beings organize knowledge, we resort to a hierarchical task clustering structure to cluster tasks. As a result, the proposed approach not only addresses the challenge via the knowledge customization to different clusters of tasks, but also preserves knowledge generalization among a cluster of similar tasks. To tackle the changing of task relationship, in addition, we extend the hierarchical structure to a continual learning environment. The experimental results show that our approach can achieve state-of-the-art performance in both toy-regression and few-shot image classification problems.
Semi-Supervised Graph Classification: A Hierarchical Graph Perspective
Apr 10, 2019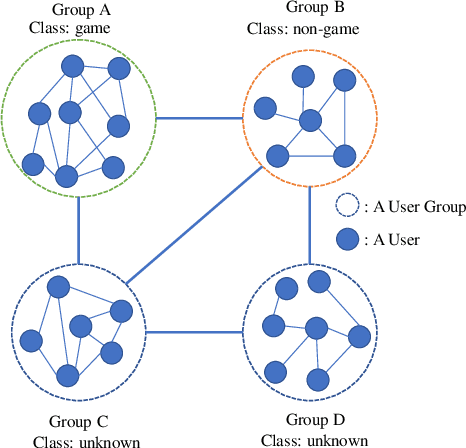

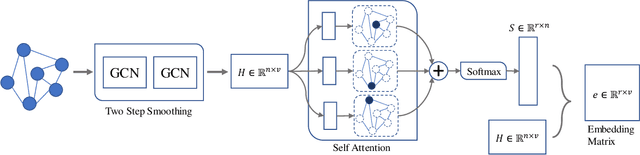
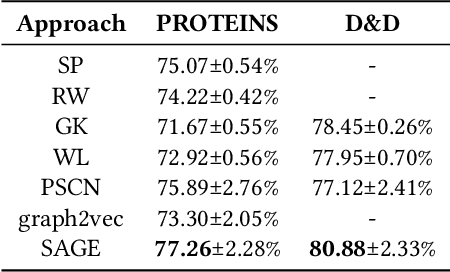
Node classification and graph classification are two graph learning problems that predict the class label of a node and the class label of a graph respectively. A node of a graph usually represents a real-world entity, e.g., a user in a social network, or a protein in a protein-protein interaction network. In this work, we consider a more challenging but practically useful setting, in which a node itself is a graph instance. This leads to a hierarchical graph perspective which arises in many domains such as social network, biological network and document collection. For example, in a social network, a group of people with shared interests forms a user group, whereas a number of user groups are interconnected via interactions or common members. We study the node classification problem in the hierarchical graph where a `node' is a graph instance, e.g., a user group in the above example. As labels are usually limited in real-world data, we design two novel semi-supervised solutions named \underline{SE}mi-supervised gr\underline{A}ph c\underline{L}assification via \underline{C}autious/\underline{A}ctive \underline{I}teration (or SEAL-C/AI in short). SEAL-C/AI adopt an iterative framework that takes turns to build or update two classifiers, one working at the graph instance level and the other at the hierarchical graph level. To simplify the representation of the hierarchical graph, we propose a novel supervised, self-attentive graph embedding method called SAGE, which embeds graph instances of arbitrary size into fixed-length vectors. Through experiments on synthetic data and Tencent QQ group data, we demonstrate that SEAL-C/AI not only outperform competing methods by a significant margin in terms of accuracy/Macro-F1, but also generate meaningful interpretations of the learned representations.
Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning
Jan 08, 2019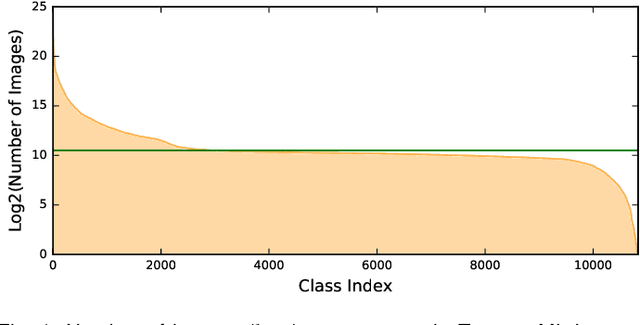
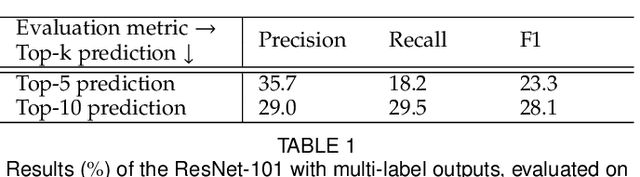
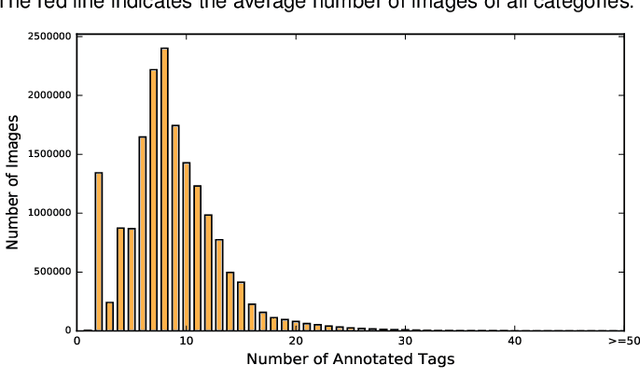
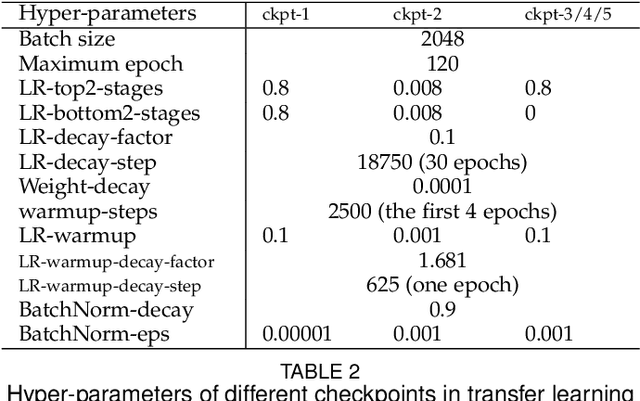
In existing visual representation learning tasks, deep convolutional neural networks (CNNs) are often trained on images annotated with single tags, such as ImageNet. However, a single tag cannot describe all important contents of one image, and some useful visual information may be wasted during training. In this work, we propose to train CNNs from images annotated with multiple tags, to enhance the quality of visual representation of the trained CNN model. To this end, we build a large-scale multi-label image database with 18M images and 11K categories, dubbed Tencent ML-Images. We efficiently train the ResNet-101 model with multi-label outputs on Tencent ML-Images, taking 90 hours for 60 epochs, based on a large-scale distributed deep learning framework,i.e.,TFplus. The good quality of the visual representation of the Tencent ML-Images checkpoint is verified through three transfer learning tasks, including single-label image classification on ImageNet and Caltech-256, object detection on PASCAL VOC 2007, and semantic segmentation on PASCAL VOC 2012. The Tencent ML-Images database, the checkpoints of ResNet-101, and all the training codehave been released at https://github.com/Tencent/tencent-ml-images. It is expected to promote other vision tasks in the research and industry community.
Weakly Supervised Dense Event Captioning in Videos
Dec 10, 2018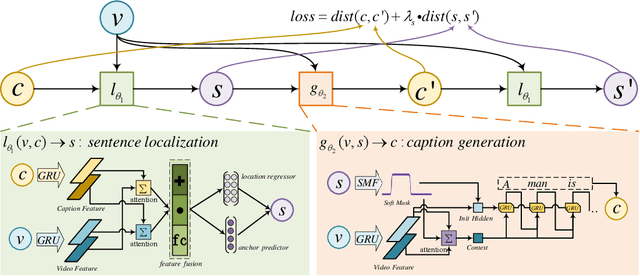
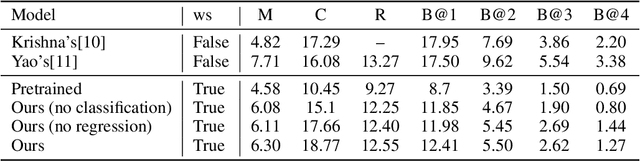
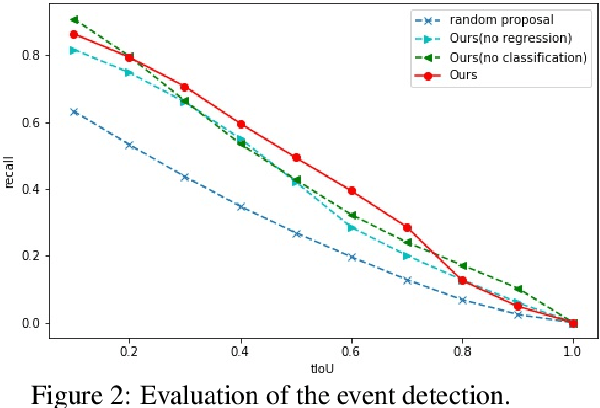

Dense event captioning aims to detect and describe all events of interest contained in a video. Despite the advanced development in this area, existing methods tackle this task by making use of dense temporal annotations, which is dramatically source-consuming. This paper formulates a new problem: weakly supervised dense event captioning, which does not require temporal segment annotations for model training. Our solution is based on the one-to-one correspondence assumption, each caption describes one temporal segment, and each temporal segment has one caption, which holds in current benchmark datasets and most real-world cases. We decompose the problem into a pair of dual problems: event captioning and sentence localization and present a cycle system to train our model. Extensive experimental results are provided to demonstrate the ability of our model on both dense event captioning and sentence localization in videos.
An Efficient Approach to Informative Feature Extraction from Multimodal Data
Nov 22, 2018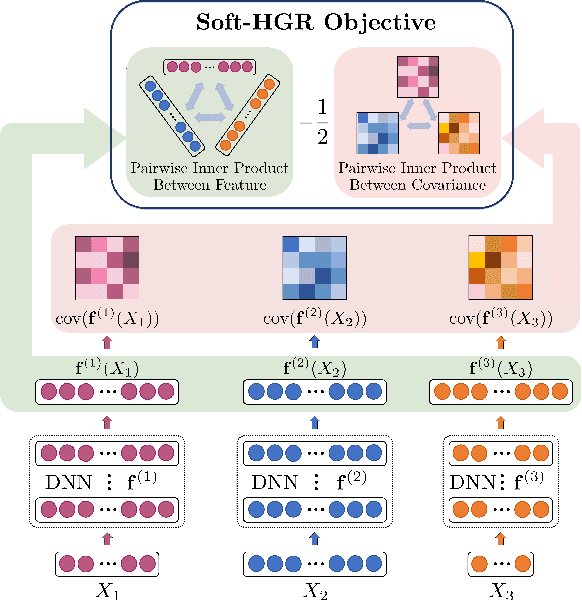
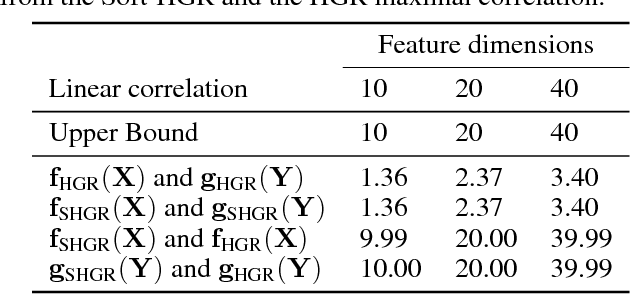
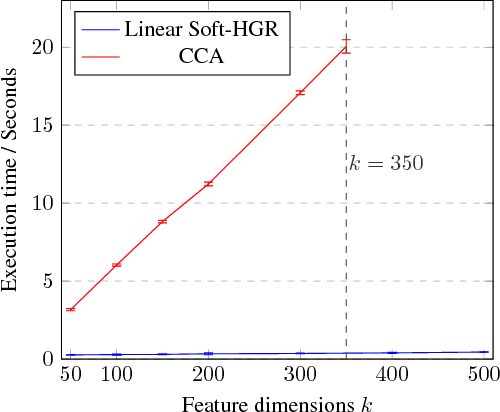
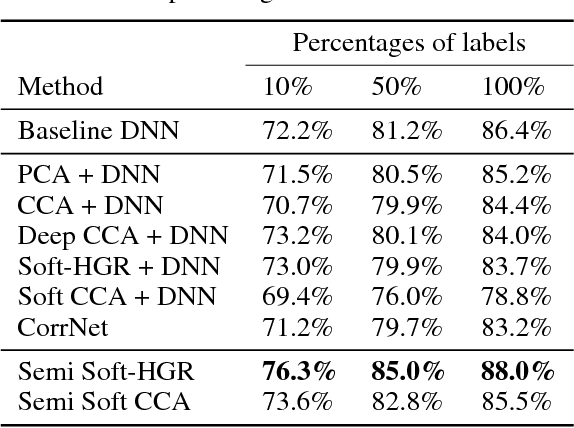
One primary focus in multimodal feature extraction is to find the representations of individual modalities that are maximally correlated. As a well-known measure of dependence, the Hirschfeld-Gebelein-R\'{e}nyi (HGR) maximal correlation becomes an appealing objective because of its operational meaning and desirable properties. However, the strict whitening constraints formalized in the HGR maximal correlation limit its application. To address this problem, this paper proposes Soft-HGR, a novel framework to extract informative features from multiple data modalities. Specifically, our framework prevents the "hard" whitening constraints, while simultaneously preserving the same feature geometry as in the HGR maximal correlation. The objective of Soft-HGR is straightforward, only involving two inner products, which guarantees the efficiency and stability in optimization. We further generalize the framework to handle more than two modalities and missing modalities. When labels are partially available, we enhance the discriminative power of the feature representations by making a semi-supervised adaptation. Empirical evaluation implies that our approach learns more informative feature mappings and is more efficient to optimize.
Progressive Feature Alignment for Unsupervised Domain Adaptation
Nov 21, 2018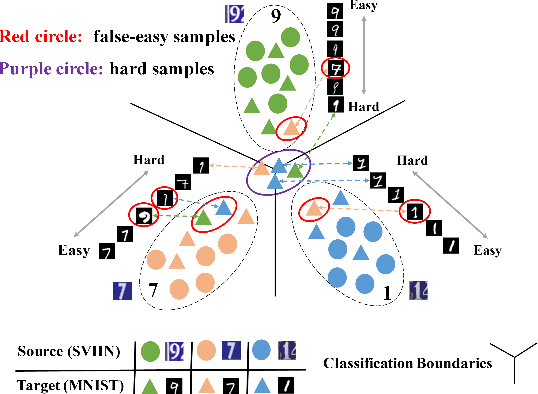
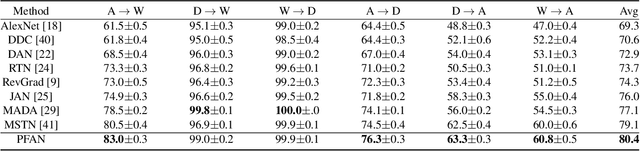
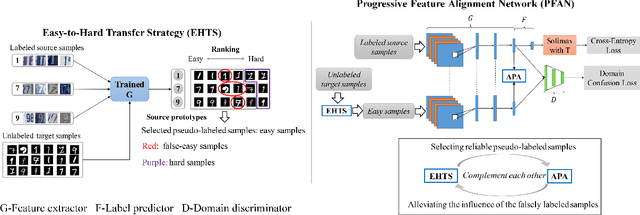

Unsupervised domain adaptation (UDA) transfers knowledge from a label-rich source domain to a fully-unlabeled target domain. To tackle this task, recent approaches resort to discriminative domain transfer in virtue of pseudo-labels to enforce the class-level distribution alignment across the source and target domains. These methods, however, are vulnerable to the error accumulation and thus incapable of preserving cross-domain category consistency, as the pseudo-labeling accuracy is not guaranteed explicitly. In this paper, we propose the Progressive Feature Alignment Network (PFAN) to align the discriminative features across domains progressively and effectively, via exploiting the intra-class variation in the target domain. To be specific, we first develop an Easy-to-Hard Transfer Strategy (EHTS) and an Adaptive Prototype Alignment (APA) step to train our model iteratively and alternatively. Moreover, upon observing that a good domain adaptation usually requires a non-saturated source classifier, we consider a simple yet efficient way to retard the convergence speed of the source classification loss by further involving a temperature variate into the soft-max function. The extensive experimental results reveal that the proposed PFAN exceeds the state-of-the-art performance on three UDA datasets.
Discrimination-aware Channel Pruning for Deep Neural Networks
Oct 30, 2018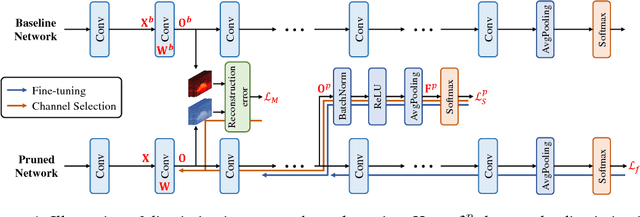
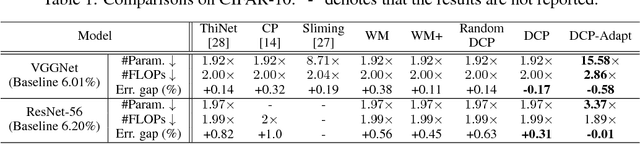
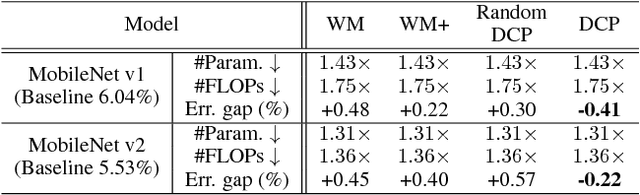

Channel pruning is one of the predominant approaches for deep model compression. Existing pruning methods either train from scratch with sparsity constraints on channels, or minimize the reconstruction error between the pre-trained feature maps and the compressed ones. Both strategies suffer from some limitations: the former kind is computationally expensive and difficult to converge, whilst the latter kind optimizes the reconstruction error but ignores the discriminative power of channels. To overcome these drawbacks, we investigate a simple-yet-effective method, called discrimination-aware channel pruning, to choose those channels that really contribute to discriminative power. To this end, we introduce additional losses into the network to increase the discriminative power of intermediate layers and then select the most discriminative channels for each layer by considering the additional loss and the reconstruction error. Last, we propose a greedy algorithm to conduct channel selection and parameter optimization in an iterative way. Extensive experiments demonstrate the effectiveness of our method. For example, on ILSVRC-12, our pruned ResNet-50 with 30% reduction of channels even outperforms the original model by 0.39% in top-1 accuracy.