 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Feb 15, 2026Pathology foundation models (PFMs) have enabled robust generalization in computational pathology through large-scale datasets and expansive architectures, but their substantial computational cost, particularly for gigapixel whole slide images, limits clinical accessibility and scalability. Here, we present LitePath, a deployment-friendly foundational framework designed to mitigate model over-parameterization and patch level redundancy. LitePath integrates LiteFM, a compact model distilled from three large PFMs (Virchow2, H-Optimus-1 and UNI2) using 190 million patches, and the Adaptive Patch Selector (APS), a lightweight component for task-specific patch selection. The framework reduces model parameters by 28x and lowers FLOPs by 403.5x relative to Virchow2, enabling deployment on low-power edge hardware such as the NVIDIA Jetson Orin Nano Super. On this device, LitePath processes 208 slides per hour, 104.5x faster than Virchow2, and consumes 0.36 kWh per 3,000 slides, 171x lower than Virchow2 on an RTX3090 GPU. We validated accuracy using 37 cohorts across four organs and 26 tasks (26 internal, 9 external, and 2 prospective), comprising 15,672 slides from 9,808 patients disjoint from the pretraining data. LitePath ranks second among 19 evaluated models and outperforms larger models including H-Optimus-1, mSTAR, UNI2 and GPFM, while retaining 99.71% of the AUC of Virchow2 on average. To quantify the balance between accuracy and efficiency, we propose the Deployability Score (D-Score), defined as the weighted geometric mean of normalized AUC and normalized FLOP, where LitePath achieves the highest value, surpassing Virchow2 by 10.64%. These results demonstrate that LitePath enables rapid, cost-effective and energy-efficient pathology image analysis on accessible hardware while maintaining accuracy comparable to state-of-the-art PFMs and reducing the carbon footprint of AI deployment.
A Multimodal Foundation Model to Enhance Generalizability and Data Efficiency for Pan-cancer Prognosis Prediction
Sep 16, 2025Multimodal data provides heterogeneous information for a holistic understanding of the tumor microenvironment. However, existing AI models often struggle to harness the rich information within multimodal data and extract poorly generalizable representations. Here we present MICE (Multimodal data Integration via Collaborative Experts), a multimodal foundation model that effectively integrates pathology images, clinical reports, and genomics data for precise pan-cancer prognosis prediction. Instead of conventional multi-expert modules, MICE employs multiple functionally diverse experts to comprehensively capture both cross-cancer and cancer-specific insights. Leveraging data from 11,799 patients across 30 cancer types, we enhanced MICE's generalizability by coupling contrastive and supervised learning. MICE outperformed both unimodal and state-of-the-art multi-expert-based multimodal models, demonstrating substantial improvements in C-index ranging from 3.8% to 11.2% on internal cohorts and 5.8% to 8.8% on independent cohorts, respectively. Moreover, it exhibited remarkable data efficiency across diverse clinical scenarios. With its enhanced generalizability and data efficiency, MICE establishes an effective and scalable foundation for pan-cancer prognosis prediction, holding strong potential to personalize tailored therapies and improve treatment outcomes.
PathBench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology
May 26, 2025



The emergence of pathology foundation models has revolutionized computational histopathology, enabling highly accurate, generalized whole-slide image analysis for improved cancer diagnosis, and prognosis assessment. While these models show remarkable potential across cancer diagnostics and prognostics, their clinical translation faces critical challenges including variability in optimal model across cancer types, potential data leakage in evaluation, and lack of standardized benchmarks. Without rigorous, unbiased evaluation, even the most advanced PFMs risk remaining confined to research settings, delaying their life-saving applications. Existing benchmarking efforts remain limited by narrow cancer-type focus, potential pretraining data overlaps, or incomplete task coverage. We present PathBench, the first comprehensive benchmark addressing these gaps through: multi-center in-hourse datasets spanning common cancers with rigorous leakage prevention, evaluation across the full clinical spectrum from diagnosis to prognosis, and an automated leaderboard system for continuous model assessment. Our framework incorporates large-scale data, enabling objective comparison of PFMs while reflecting real-world clinical complexity. All evaluation data comes from private medical providers, with strict exclusion of any pretraining usage to avoid data leakage risks. We have collected 15,888 WSIs from 8,549 patients across 10 hospitals, encompassing over 64 diagnosis and prognosis tasks. Currently, our evaluation of 19 PFMs shows that Virchow2 and H-Optimus-1 are the most effective models overall. This work provides researchers with a robust platform for model development and offers clinicians actionable insights into PFM performance across diverse clinical scenarios, ultimately accelerating the translation of these transformative technologies into routine pathology practice.
Urban Representation Learning for Fine-grained Economic Mapping: A Semi-supervised Graph-based Approach
May 16, 2025



Fine-grained economic mapping through urban representation learning has emerged as a crucial tool for evidence-based economic decisions. While existing methods primarily rely on supervised or unsupervised approaches, they often overlook semi-supervised learning in data-scarce scenarios and lack unified multi-task frameworks for comprehensive sectoral economic analysis. To address these gaps, we propose SemiGTX, an explainable semi-supervised graph learning framework for sectoral economic mapping. The framework is designed with dedicated fusion encoding modules for various geospatial data modalities, seamlessly integrating them into a cohesive graph structure. It introduces a semi-information loss function that combines spatial self-supervision with locally masked supervised regression, enabling more informative and effective region representations. Through multi-task learning, SemiGTX concurrently maps GDP across primary, secondary, and tertiary sectors within a unified model. Extensive experiments conducted in the Pearl River Delta region of China demonstrate the model's superior performance compared to existing methods, achieving R2 scores of 0.93, 0.96, and 0.94 for the primary, secondary and tertiary sectors, respectively. Cross-regional experiments in Beijing and Chengdu further illustrate its generality. Systematic analysis reveals how different data modalities influence model predictions, enhancing explainability while providing valuable insights for regional development planning. This representation learning framework advances regional economic monitoring through diverse urban data integration, providing a robust foundation for precise economic forecasting.
Prototype Learning Guided Hybrid Network for Breast Tumor Segmentation in DCE-MRI
Aug 11, 2024



Automated breast tumor segmentation on the basis of dynamic contrast-enhancement magnetic resonance imaging (DCE-MRI) has shown great promise in clinical practice, particularly for identifying the presence of breast disease. However, accurate segmentation of breast tumor is a challenging task, often necessitating the development of complex networks. To strike an optimal trade-off between computational costs and segmentation performance, we propose a hybrid network via the combination of convolution neural network (CNN) and transformer layers. Specifically, the hybrid network consists of a encoder-decoder architecture by stacking convolution and decovolution layers. Effective 3D transformer layers are then implemented after the encoder subnetworks, to capture global dependencies between the bottleneck features. To improve the efficiency of hybrid network, two parallel encoder subnetworks are designed for the decoder and the transformer layers, respectively. To further enhance the discriminative capability of hybrid network, a prototype learning guided prediction module is proposed, where the category-specified prototypical features are calculated through on-line clustering. All learned prototypical features are finally combined with the features from decoder for tumor mask prediction. The experimental results on private and public DCE-MRI datasets demonstrate that the proposed hybrid network achieves superior performance than the state-of-the-art (SOTA) methods, while maintaining balance between segmentation accuracy and computation cost. Moreover, we demonstrate that automatically generated tumor masks can be effectively applied to identify HER2-positive subtype from HER2-negative subtype with the similar accuracy to the analysis based on manual tumor segmentation. The source code is available at https://github.com/ZhouL-lab/PLHN.
iMD4GC: Incomplete Multimodal Data Integration to Advance Precise Treatment Response Prediction and Survival Analysis for Gastric Cancer
Apr 01, 2024



Gastric cancer (GC) is a prevalent malignancy worldwide, ranking as the fifth most common cancer with over 1 million new cases and 700 thousand deaths in 2020. Locally advanced gastric cancer (LAGC) accounts for approximately two-thirds of GC diagnoses, and neoadjuvant chemotherapy (NACT) has emerged as the standard treatment for LAGC. However, the effectiveness of NACT varies significantly among patients, with a considerable subset displaying treatment resistance. Ineffective NACT not only leads to adverse effects but also misses the optimal therapeutic window, resulting in lower survival rate. However, existing multimodal learning methods assume the availability of all modalities for each patient, which does not align with the reality of clinical practice. The limited availability of modalities for each patient would cause information loss, adversely affecting predictive accuracy. In this study, we propose an incomplete multimodal data integration framework for GC (iMD4GC) to address the challenges posed by incomplete multimodal data, enabling precise response prediction and survival analysis. Specifically, iMD4GC incorporates unimodal attention layers for each modality to capture intra-modal information. Subsequently, the cross-modal interaction layers explore potential inter-modal interactions and capture complementary information across modalities, thereby enabling information compensation for missing modalities. To evaluate iMD4GC, we collected three multimodal datasets for GC study: GastricRes (698 cases) for response prediction, GastricSur (801 cases) for survival analysis, and TCGA-STAD (400 cases) for survival analysis. The scale of our datasets is significantly larger than previous studies. The iMD4GC achieved impressive performance with an 80.2% AUC on GastricRes, 71.4% C-index on GastricSur, and 66.1% C-index on TCGA-STAD, significantly surpassing other compared methods.
CBLab: Scalable Traffic Simulation with Enriched Data Supporting
Oct 03, 2022
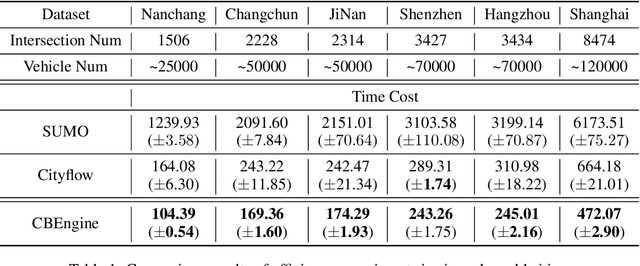
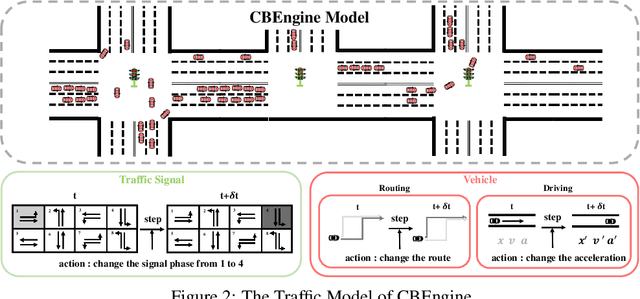
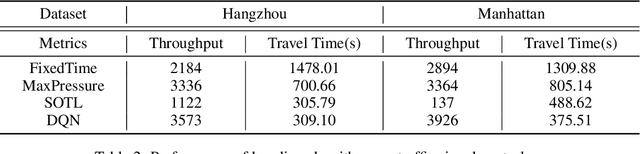
Traffic simulation provides interactive data for the optimization of traffic policies. However, existing traffic simulators are limited by their lack of scalability and shortage in input data, which prevents them from generating interactive data from traffic simulation in the scenarios of real large-scale city road networks. In this paper, we present City Brain Lab, a toolkit for scalable traffic simulation. CBLab is consist of three components: CBEngine, CBData, and CBScenario. CBEngine is a highly efficient simulators supporting large scale traffic simulation. CBData includes a traffic dataset with road network data of 100 cities all around the world. We also develop a pipeline to conduct one-click transformation from raw road networks to input data of our traffic simulation. Combining CBEngine and CBData allows researchers to run scalable traffic simulation in the road network of real large-scale cities. Based on that, CBScenario implements an interactive environment and several baseline methods for two scenarios of traffic policies respectively, with which traffic policies adaptable for large-scale urban traffic can be trained and tuned. To the best of our knowledge, CBLab is the first infrastructure supporting traffic policy optimization on large-scale urban scenarios. The code is available on Github: https://github.com/CityBrainLab/CityBrainLab.git.
Boosting Offline Reinforcement Learning with Residual Generative Modeling
Jun 22, 2021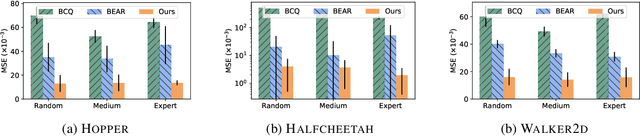
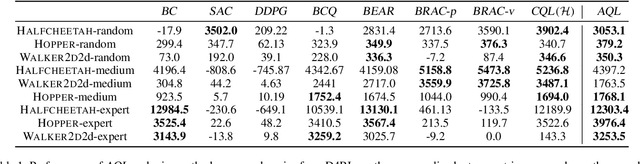
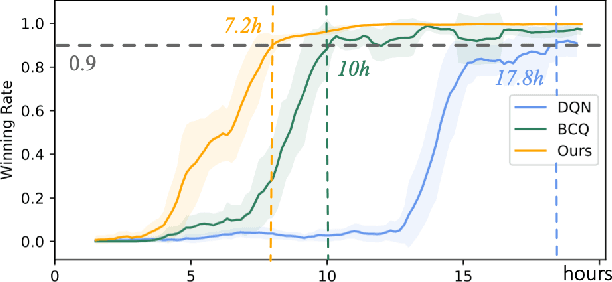
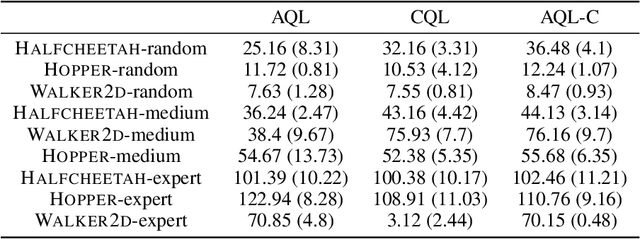
Offline reinforcement learning (RL) tries to learn the near-optimal policy with recorded offline experience without online exploration. Current offline RL research includes: 1) generative modeling, i.e., approximating a policy using fixed data; and 2) learning the state-action value function. While most research focuses on the state-action function part through reducing the bootstrapping error in value function approximation induced by the distribution shift of training data, the effects of error propagation in generative modeling have been neglected. In this paper, we analyze the error in generative modeling. We propose AQL (action-conditioned Q-learning), a residual generative model to reduce policy approximation error for offline RL. We show that our method can learn more accurate policy approximations in different benchmark datasets. In addition, we show that the proposed offline RL method can learn more competitive AI agents in complex control tasks under the multiplayer online battle arena (MOBA) game Honor of Kings.
Learning to Route via Theory-Guided Residual Network
May 26, 2021
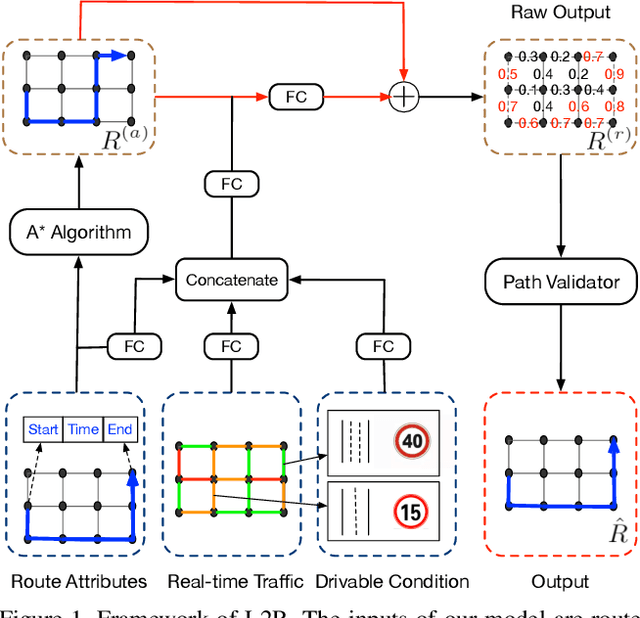
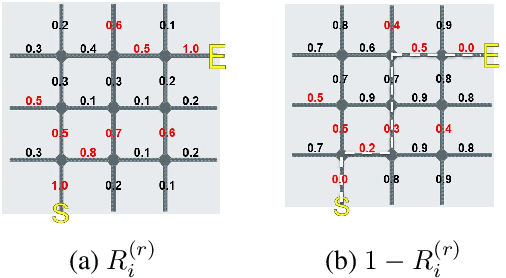
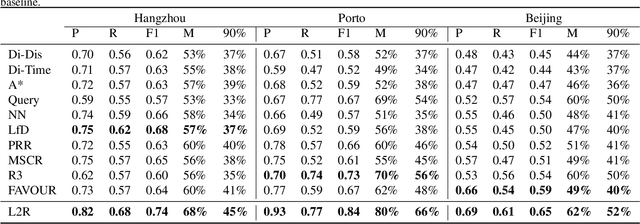
The heavy traffic and related issues have always been concerns for modern cities. With the help of deep learning and reinforcement learning, people have proposed various policies to solve these traffic-related problems, such as smart traffic signal control systems and taxi dispatching systems. People usually validate these policies in a city simulator, since directly applying them in the real city introduces real cost. However, these policies validated in the city simulator may fail in the real city if the simulator is significantly different from the real world. To tackle this problem, we need to build a real-like traffic simulation system. Therefore, in this paper, we propose to learn the human routing model, which is one of the most essential part in the traffic simulator. This problem has two major challenges. First, human routing decisions are determined by multiple factors, besides the common time and distance factor. Second, current historical routes data usually covers just a small portion of vehicles, due to privacy and device availability issues. To address these problems, we propose a theory-guided residual network model, where the theoretical part can emphasize the general principles for human routing decisions (e.g., fastest route), and the residual part can capture drivable condition preferences (e.g., local road or highway). Since the theoretical part is composed of traditional shortest path algorithms that do not need data to train, our residual network can learn human routing models from limited data. We have conducted extensive experiments on multiple real-world datasets to show the superior performance of our model, especially with small data. Besides, we have also illustrated why our model is better at recovering real routes through case studies.
Objective-aware Traffic Simulation via Inverse Reinforcement Learning
May 20, 2021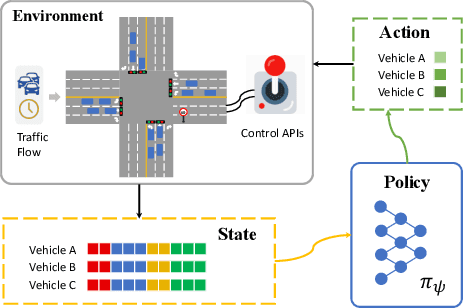

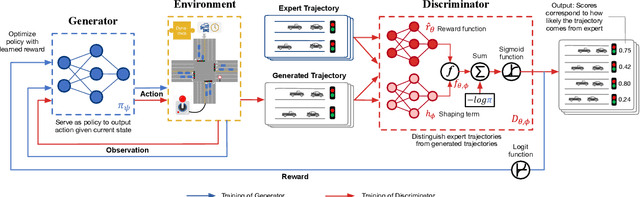
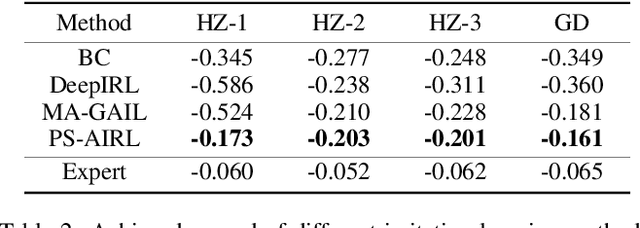
Traffic simulators act as an essential component in the operating and planning of transportation systems. Conventional traffic simulators usually employ a calibrated physical car-following model to describe vehicles' behaviors and their interactions with traffic environment. However, there is no universal physical model that can accurately predict the pattern of vehicle's behaviors in different situations. A fixed physical model tends to be less effective in a complicated environment given the non-stationary nature of traffic dynamics. In this paper, we formulate traffic simulation as an inverse reinforcement learning problem, and propose a parameter sharing adversarial inverse reinforcement learning model for dynamics-robust simulation learning. Our proposed model is able to imitate a vehicle's trajectories in the real world while simultaneously recovering the reward function that reveals the vehicle's true objective which is invariant to different dynamics. Extensive experiments on synthetic and real-world datasets show the superior performance of our approach compared to state-of-the-art methods and its robustness to variant dynamics of traffic.