 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Disentangled Feature Representation Beyond Face Identification
Apr 10, 2018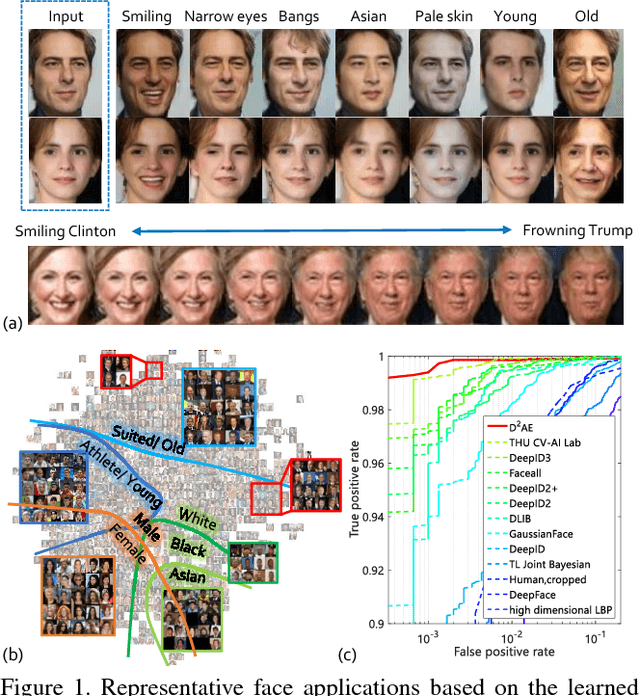
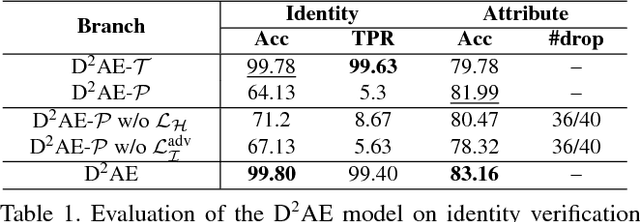
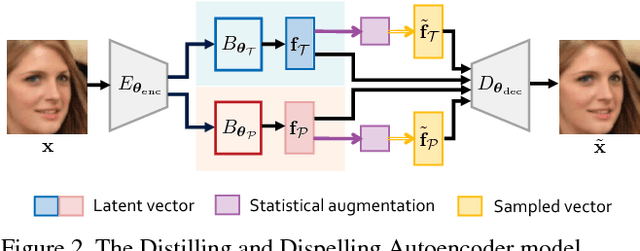
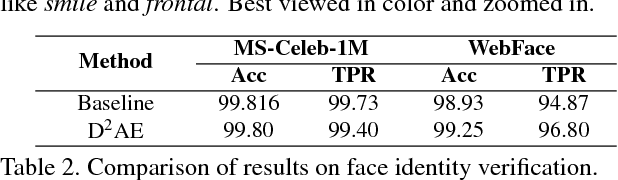
This paper proposes learning disentangled but complementary face features with minimal supervision by face identification. Specifically, we construct an identity Distilling and Dispelling Autoencoder (D2AE) framework that adversarially learns the identity-distilled features for identity verification and the identity-dispelled features to fool the verification system. Thanks to the design of two-stream cues, the learned disentangled features represent not only the identity or attribute but the complete input image. Comprehensive evaluations further demonstrate that the proposed features not only maintain state-of-the-art identity verification performance on LFW, but also acquire competitive discriminative power for face attribute recognition on CelebA and LFWA. Moreover, the proposed system is ready to semantically control the face generation/editing based on various identities and attributes in an unsupervised manner.
Deep Cocktail Network: Multi-source Unsupervised Domain Adaptation with Category Shift
Mar 02, 2018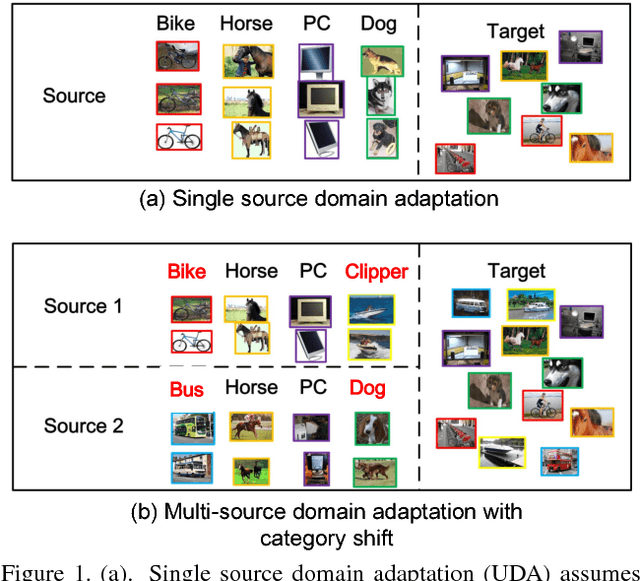
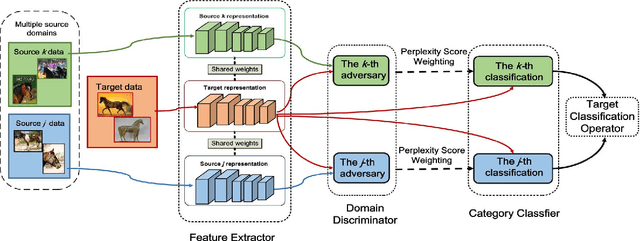
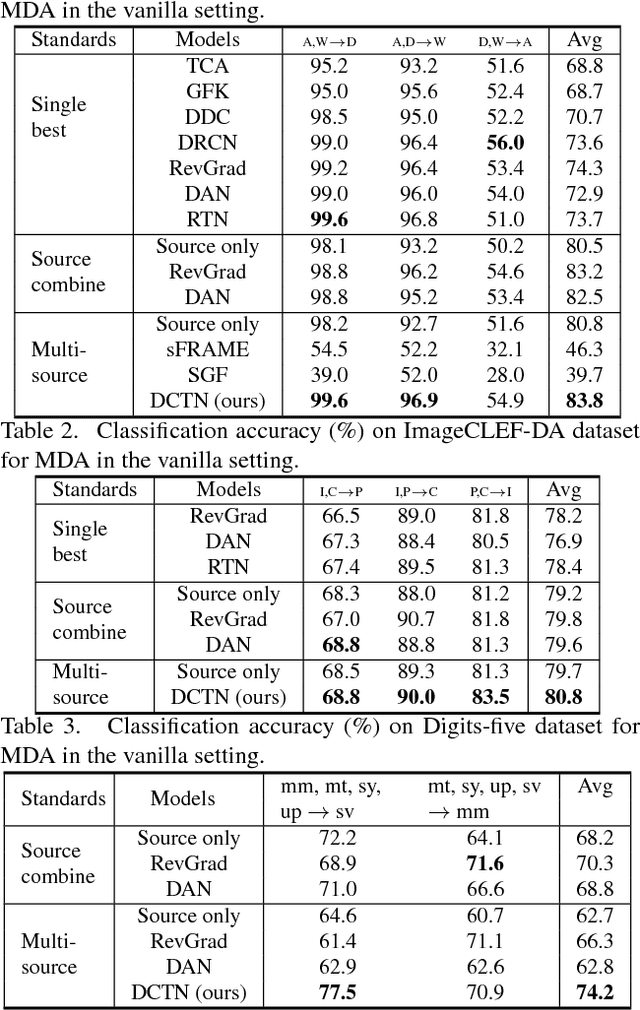

Unsupervised domain adaptation (UDA) conventionally assumes labeled source samples coming from a single underlying source distribution. Whereas in practical scenario, labeled data are typically collected from diverse sources. The multiple sources are different not only from the target but also from each other, thus, domain adaptater should not be modeled in the same way. Moreover, those sources may not completely share their categories, which further brings a new transfer challenge called category shift. In this paper, we propose a deep cocktail network (DCTN) to battle the domain and category shifts among multiple sources. Motivated by the theoretical results in \cite{mansour2009domain}, the target distribution can be represented as the weighted combination of source distributions, and, the multi-source unsupervised domain adaptation via DCTN is then performed as two alternating steps: i) It deploys multi-way adversarial learning to minimize the discrepancy between the target and each of the multiple source domains, which also obtains the source-specific perplexity scores to denote the possibilities that a target sample belongs to different source domains. ii) The multi-source category classifiers are integrated with the perplexity scores to classify target sample, and the pseudo-labeled target samples together with source samples are utilized to update the multi-source category classifier and the feature extractor. We evaluate DCTN in three domain adaptation benchmarks, which clearly demonstrate the superiority of our framework.
End-to-end Flow Correlation Tracking with Spatial-temporal Attention
Feb 27, 2018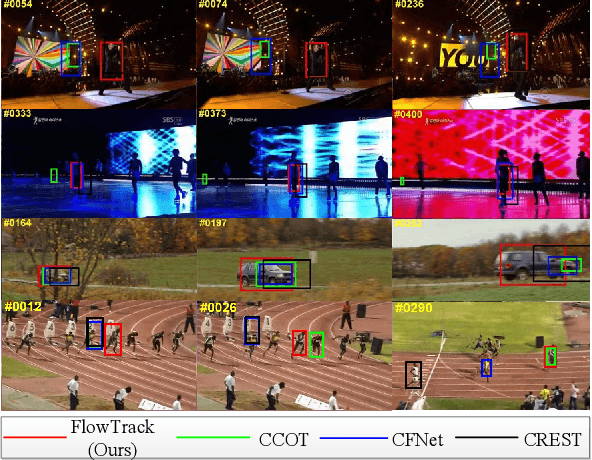
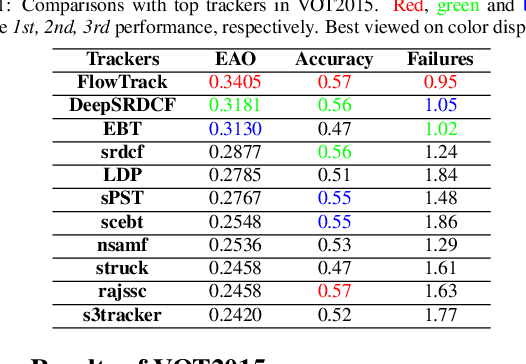
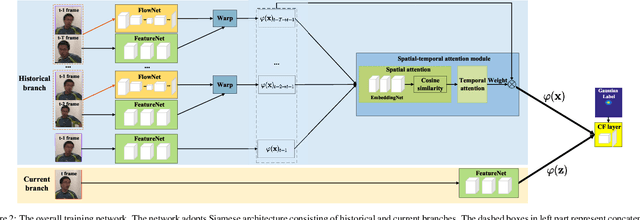
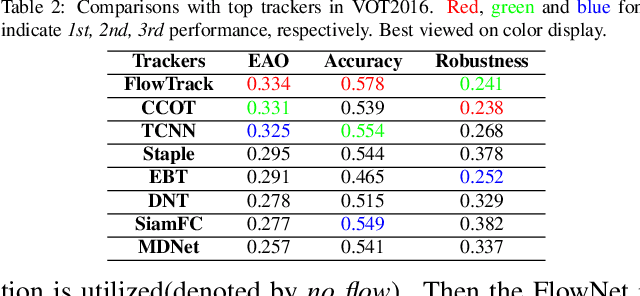
Discriminative correlation filters (DCF) with deep convolutional features have achieved favorable performance in recent tracking benchmarks. However, most of existing DCF trackers only consider appearance features of current frame, and hardly benefit from motion and inter-frame information. The lack of temporal information degrades the tracking performance during challenges such as partial occlusion and deformation. In this work, we focus on making use of the rich flow information in consecutive frames to improve the feature representation and the tracking accuracy. Firstly, individual components, including optical flow estimation, feature extraction, aggregation and correlation filter tracking are formulated as special layers in network. To the best of our knowledge, this is the first work to jointly train flow and tracking task in a deep learning framework. Then the historical feature maps at predefined intervals are warped and aggregated with current ones by the guiding of flow. For adaptive aggregation, we propose a novel spatial-temporal attention mechanism. Extensive experiments are performed on four challenging tracking datasets: OTB2013, OTB2015, VOT2015 and VOT2016, and the proposed method achieves superior results on these benchmarks.
Recurrent Scale Approximation for Object Detection in CNN
Feb 08, 2018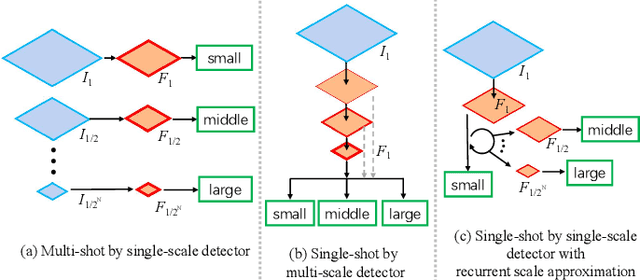

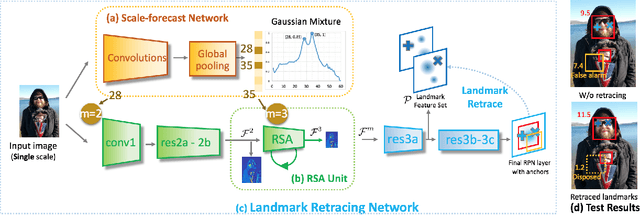
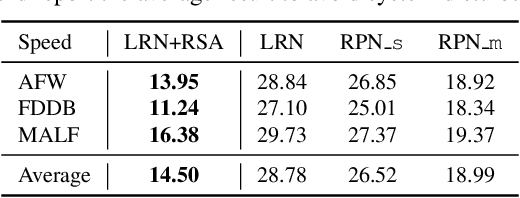
Since convolutional neural network (CNN) lacks an inherent mechanism to handle large scale variations, we always need to compute feature maps multiple times for multi-scale object detection, which has the bottleneck of computational cost in practice. To address this, we devise a recurrent scale approximation (RSA) to compute feature map once only, and only through this map can we approximate the rest maps on other levels. At the core of RSA is the recursive rolling out mechanism: given an initial map at a particular scale, it generates the prediction at a smaller scale that is half the size of input. To further increase efficiency and accuracy, we (a): design a scale-forecast network to globally predict potential scales in the image since there is no need to compute maps on all levels of the pyramid. (b): propose a landmark retracing network (LRN) to trace back locations of the regressed landmarks and generate a confidence score for each landmark; LRN can effectively alleviate false positives caused by the accumulated error in RSA. The whole system can be trained end-to-end in a unified CNN framework. Experiments demonstrate that our proposed algorithm is superior against state-of-the-art methods on face detection benchmarks and achieves comparable results for generic proposal generation. The source code of RSA is available at github.com/sciencefans/RSA-for-object-detection.
FOTS: Fast Oriented Text Spotting with a Unified Network
Jan 15, 2018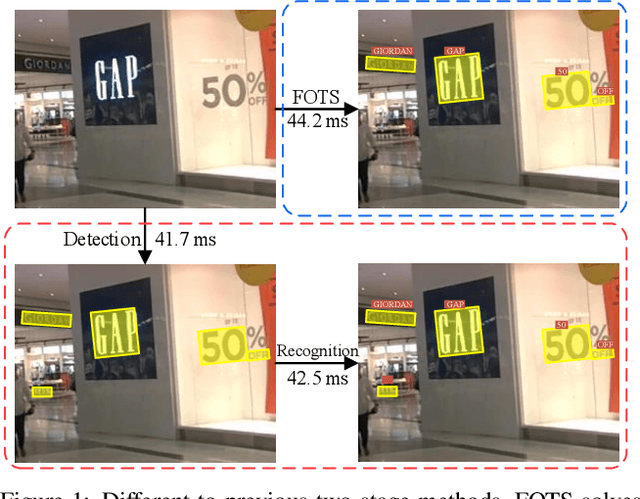
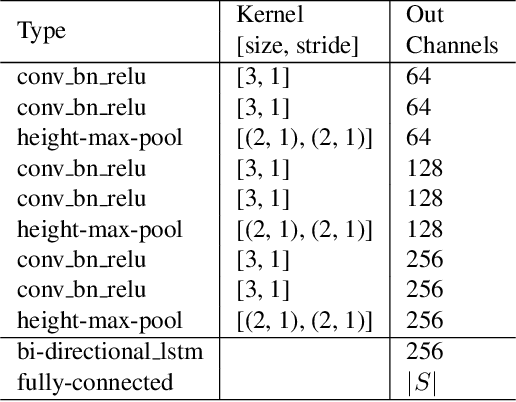

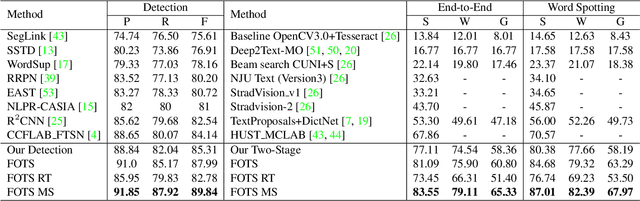
Incidental scene text spotting is considered one of the most difficult and valuable challenges in the document analysis community. Most existing methods treat text detection and recognition as separate tasks. In this work, we propose a unified end-to-end trainable Fast Oriented Text Spotting (FOTS) network for simultaneous detection and recognition, sharing computation and visual information among the two complementary tasks. Specially, RoIRotate is introduced to share convolutional features between detection and recognition. Benefiting from convolution sharing strategy, our FOTS has little computation overhead compared to baseline text detection network, and the joint training method learns more generic features to make our method perform better than these two-stage methods. Experiments on ICDAR 2015, ICDAR 2017 MLT, and ICDAR 2013 datasets demonstrate that the proposed method outperforms state-of-the-art methods significantly, which further allows us to develop the first real-time oriented text spotting system which surpasses all previous state-of-the-art results by more than 5% on ICDAR 2015 text spotting task while keeping 22.6 fps.
Accelerated Training for Massive Classification via Dynamic Class Selection
Jan 05, 2018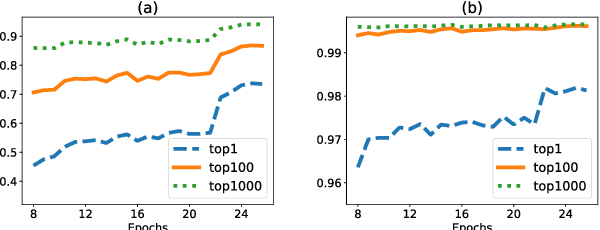
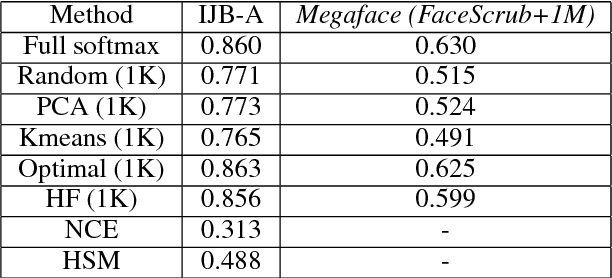
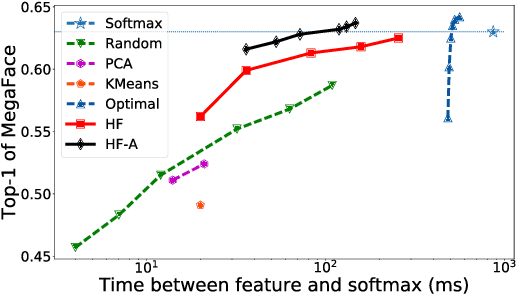
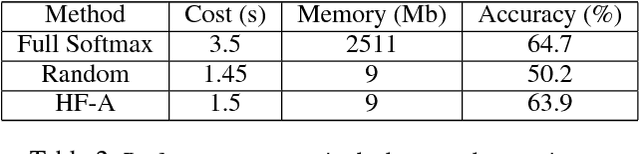
Massive classification, a classification task defined over a vast number of classes (hundreds of thousands or even millions), has become an essential part of many real-world systems, such as face recognition. Existing methods, including the deep networks that achieved remarkable success in recent years, were mostly devised for problems with a moderate number of classes. They would meet with substantial difficulties, e.g. excessive memory demand and computational cost, when applied to massive problems. We present a new method to tackle this problem. This method can efficiently and accurately identify a small number of "active classes" for each mini-batch, based on a set of dynamic class hierarchies constructed on the fly. We also develop an adaptive allocation scheme thereon, which leads to a better tradeoff between performance and cost. On several large-scale benchmarks, our method significantly reduces the training cost and memory demand, while maintaining competitive performance.
Impression Network for Video Object Detection
Dec 16, 2017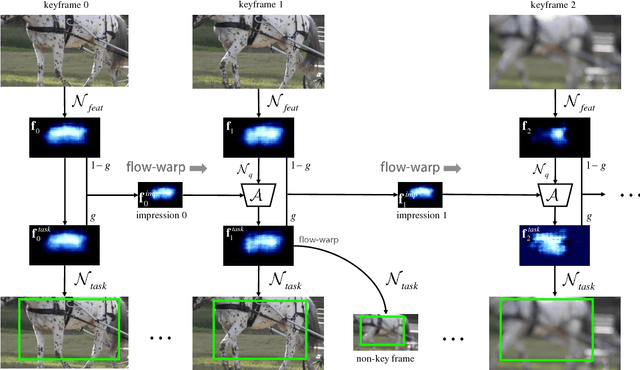
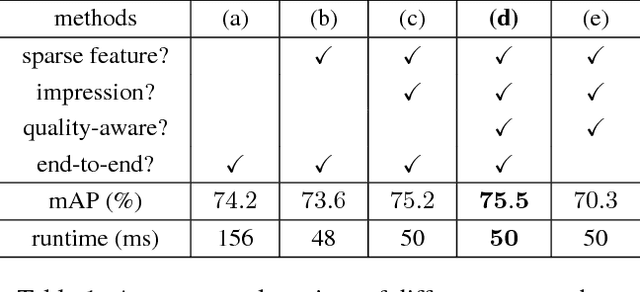

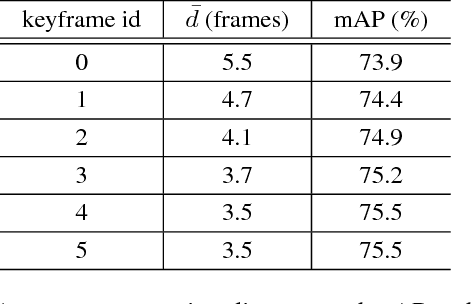
Video object detection is more challenging compared to image object detection. Previous works proved that applying object detector frame by frame is not only slow but also inaccurate. Visual clues get weakened by defocus and motion blur, causing failure on corresponding frames. Multi-frame feature fusion methods proved effective in improving the accuracy, but they dramatically sacrifice the speed. Feature propagation based methods proved effective in improving the speed, but they sacrifice the accuracy. So is it possible to improve speed and performance simultaneously? Inspired by how human utilize impression to recognize objects from blurry frames, we propose Impression Network that embodies a natural and efficient feature aggregation mechanism. In our framework, an impression feature is established by iteratively absorbing sparsely extracted frame features. The impression feature is propagated all the way down the video, helping enhance features of low-quality frames. This impression mechanism makes it possible to perform long-range multi-frame feature fusion among sparse keyframes with minimal overhead. It significantly improves per-frame detection baseline on ImageNet VID while being 3 times faster (20 fps). We hope Impression Network can provide a new perspective on video feature enhancement. Code will be made available.
Peephole: Predicting Network Performance Before Training
Dec 09, 2017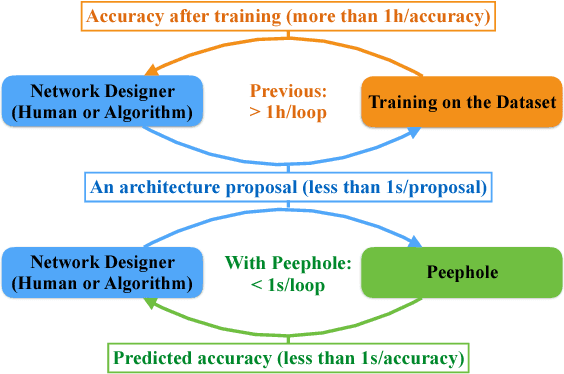
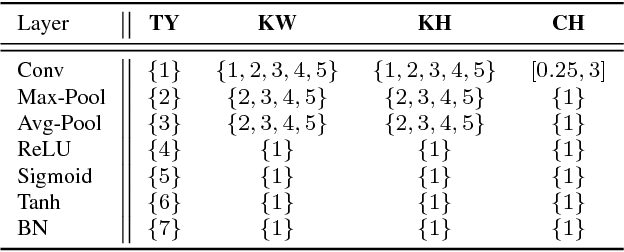
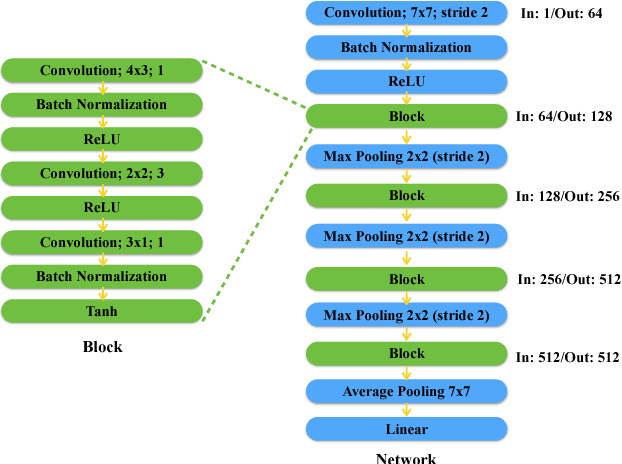
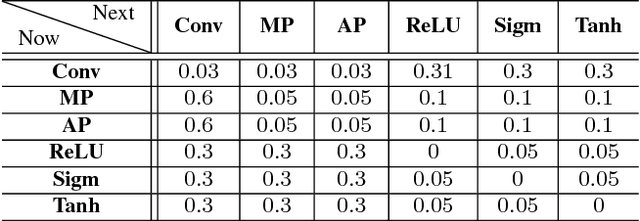
The quest for performant networks has been a significant force that drives the advancements of deep learning in recent years. While rewarding, improving network design has never been an easy journey. The large design space combined with the tremendous cost required for network training poses a major obstacle to this endeavor. In this work, we propose a new approach to this problem, namely, predicting the performance of a network before training, based on its architecture. Specifically, we develop a unified way to encode individual layers into vectors and bring them together to form an integrated description via LSTM. Taking advantage of the recurrent network's strong expressive power, this method can reliably predict the performances of various network architectures. Our empirical studies showed that it not only achieved accurate predictions but also produced consistent rankings across datasets -- a key desideratum in performance prediction.
HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
Sep 28, 2017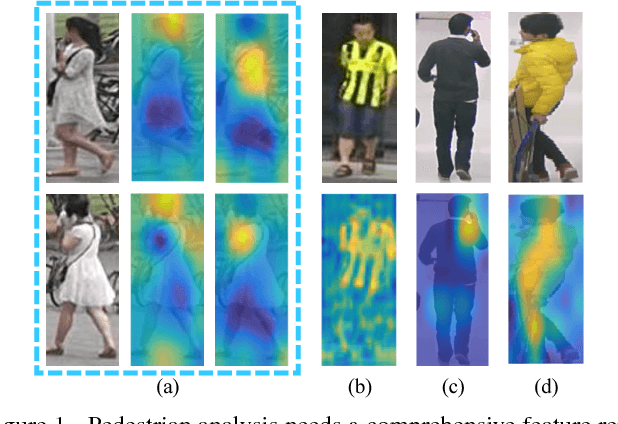
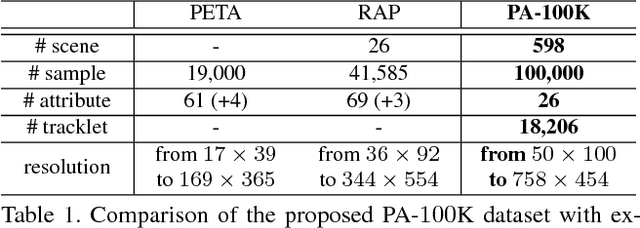
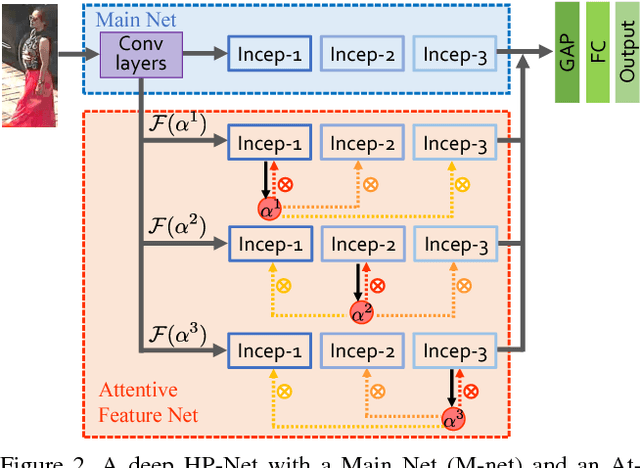

Pedestrian analysis plays a vital role in intelligent video surveillance and is a key component for security-centric computer vision systems. Despite that the convolutional neural networks are remarkable in learning discriminative features from images, the learning of comprehensive features of pedestrians for fine-grained tasks remains an open problem. In this study, we propose a new attention-based deep neural network, named as HydraPlus-Net (HP-net), that multi-directionally feeds the multi-level attention maps to different feature layers. The attentive deep features learned from the proposed HP-net bring unique advantages: (1) the model is capable of capturing multiple attentions from low-level to semantic-level, and (2) it explores the multi-scale selectiveness of attentive features to enrich the final feature representations for a pedestrian image. We demonstrate the effectiveness and generality of the proposed HP-net for pedestrian analysis on two tasks, i.e. pedestrian attribute recognition and person re-identification. Intensive experimental results have been provided to prove that the HP-net outperforms the state-of-the-art methods on various datasets.
T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
Aug 03, 2017
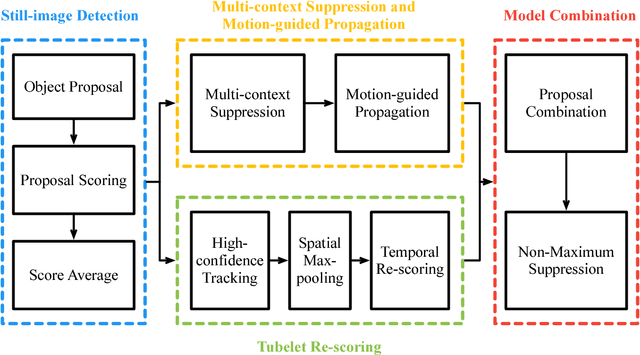

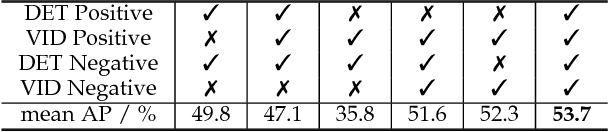
The state-of-the-art performance for object detection has been significantly improved over the past two years. Besides the introduction of powerful deep neural networks such as GoogleNet and VGG, novel object detection frameworks such as R-CNN and its successors, Fast R-CNN and Faster R-CNN, play an essential role in improving the state-of-the-art. Despite their effectiveness on still images, those frameworks are not specifically designed for object detection from videos. Temporal and contextual information of videos are not fully investigated and utilized. In this work, we propose a deep learning framework that incorporates temporal and contextual information from tubelets obtained in videos, which dramatically improves the baseline performance of existing still-image detection frameworks when they are applied to videos. It is called T-CNN, i.e. tubelets with convolutional neueral networks. The proposed framework won the recently introduced object-detection-from-video (VID) task with provided data in the ImageNet Large-Scale Visual Recognition Challenge 2015 (ILSVRC2015).