 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
Jun 28, 2026Reinforcement learning (RL) has gained growing attention in large language model (LLM) post-training, yet RL training remains fragile and can suffer from instability or collapse. One vital cause is training-inference mismatch: LLM adopts separate inference and training engines for generation efficiency and training precision, which in practice exhibits inconsistent probabilities for the same trajectories on training and inference sides, even with synchronized model parameters. This naturally induces a special type of off-policyness ever existing and poisoning the training. Prior works have made various efforts in addressing the off-policyness to stabilize the training policies under the mismatch. In this paper, we point out the objective misalignment neglected by existing works that an effective update to the policy in the training engine not necessarily ensures the improvement of the inference policy, i.e., the one used in deployment. To this end, we propose a new policy optimization objective for LLM RL, named Monotonic Inference Policy Improvement (MIPI). Following this principle, we introduce Monotonic Inference Policy Update (MIPU), a two-step LLM RL framework that constructs sampler-referenced candidate updates and selectively accepts synchronized candidates using an inference-side gap proxy. Experiments conducted on two model scales under high mismatch show that MIPU improves average reasoning performance and training stability.
Key Decision-Makers in Multi-Agent Debates: Who Holds the Power?
Nov 14, 2025Recent studies on LLM agent scaling have highlighted the potential of Multi-Agent Debate (MAD) to enhance reasoning abilities. However, the critical aspect of role allocation strategies remains underexplored. In this study, we demonstrate that allocating roles with differing viewpoints to specific positions significantly impacts MAD's performance in reasoning tasks. Specifically, we find a novel role allocation strategy, "Truth Last", which can improve MAD performance by up to 22% in reasoning tasks. To address the issue of unknown truth in practical applications, we propose the Multi-Agent Debate Consistency (MADC) strategy, which systematically simulates and optimizes its core mechanisms. MADC incorporates path consistency to assess agreement among independent roles, simulating the role with the highest consistency score as the truth. We validated MADC across a range of LLMs (9 models), including the DeepSeek-R1 Distilled Models, on challenging reasoning tasks. MADC consistently demonstrated advanced performance, effectively overcoming MAD's performance bottlenecks and providing a crucial pathway for further improvements in LLM agent scaling.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025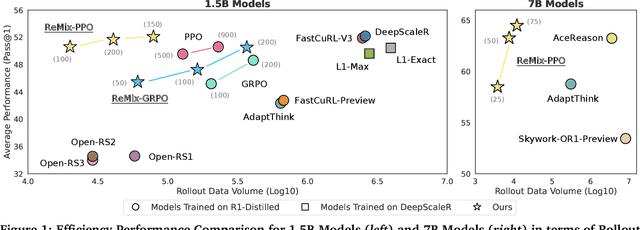
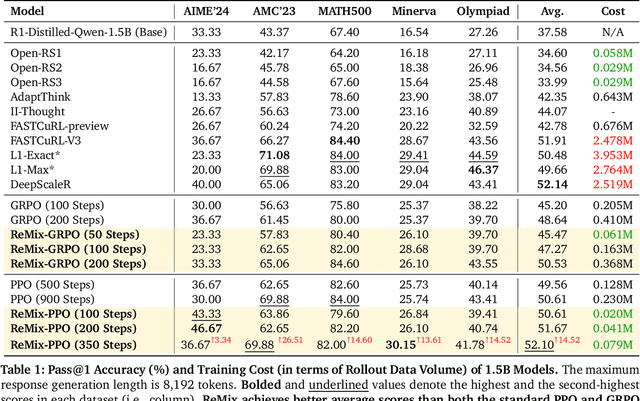
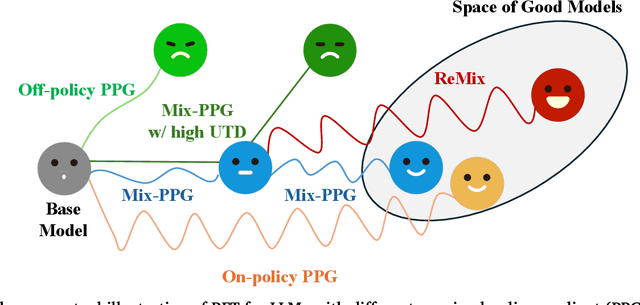

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025



Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
DualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answering
Apr 25, 2025



Multi-Hop Question Answering (MHQA) tasks permeate real-world applications, posing challenges in orchestrating multi-step reasoning across diverse knowledge domains. While existing approaches have been improved with iterative retrieval, they still struggle to identify and organize dynamic knowledge. To address this, we propose DualRAG, a synergistic dual-process framework that seamlessly integrates reasoning and retrieval. DualRAG operates through two tightly coupled processes: Reasoning-augmented Querying (RaQ) and progressive Knowledge Aggregation (pKA). They work in concert: as RaQ navigates the reasoning path and generates targeted queries, pKA ensures that newly acquired knowledge is systematically integrated to support coherent reasoning. This creates a virtuous cycle of knowledge enrichment and reasoning refinement. Through targeted fine-tuning, DualRAG preserves its sophisticated reasoning and retrieval capabilities even in smaller-scale models, demonstrating its versatility and core advantages across different scales. Extensive experiments demonstrate that this dual-process approach substantially improves answer accuracy and coherence, approaching, and in some cases surpassing, the performance achieved with oracle knowledge access. These results establish DualRAG as a robust and efficient solution for complex multi-hop reasoning tasks.
From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models
Mar 20, 2025



Recent advances in large language models (LLMs) have shown remarkable progress, yet their capacity for logical ``slow-thinking'' reasoning persists as a critical research frontier. Current inference scaling paradigms suffer from two fundamental constraints: fragmented thought flows compromising logical coherence, and intensively computational complexity that escalates with search space dimensions. To overcome these limitations, we present \textbf{Atomic Reasoner} (\textbf{AR}), a cognitive inference strategy that enables fine-grained reasoning through systematic atomic-level operations. AR decomposes the reasoning process into atomic cognitive units, employing a cognitive routing mechanism to dynamically construct reasoning representations and orchestrate inference pathways. This systematic methodology implements stepwise, structured cognition, which ensures logical coherence while significantly reducing cognitive load, effectively simulating the cognitive patterns observed in human deep thinking processes. Extensive experimental results demonstrate AR's superior reasoning capabilities without the computational burden of exhaustive solution searches, particularly excelling in linguistic logic puzzles. These findings substantiate AR's effectiveness in enhancing LLMs' capacity for robust, long-sequence logical reasoning and deliberation.
CellAgent: An LLM-driven Multi-Agent Framework for Automated Single-cell Data Analysis
Jul 13, 2024Single-cell RNA sequencing (scRNA-seq) data analysis is crucial for biological research, as it enables the precise characterization of cellular heterogeneity. However, manual manipulation of various tools to achieve desired outcomes can be labor-intensive for researchers. To address this, we introduce CellAgent (http://cell.agent4science.cn/), an LLM-driven multi-agent framework, specifically designed for the automatic processing and execution of scRNA-seq data analysis tasks, providing high-quality results with no human intervention. Firstly, to adapt general LLMs to the biological field, CellAgent constructs LLM-driven biological expert roles - planner, executor, and evaluator - each with specific responsibilities. Then, CellAgent introduces a hierarchical decision-making mechanism to coordinate these biological experts, effectively driving the planning and step-by-step execution of complex data analysis tasks. Furthermore, we propose a self-iterative optimization mechanism, enabling CellAgent to autonomously evaluate and optimize solutions, thereby guaranteeing output quality. We evaluate CellAgent on a comprehensive benchmark dataset encompassing dozens of tissues and hundreds of distinct cell types. Evaluation results consistently show that CellAgent effectively identifies the most suitable tools and hyperparameters for single-cell analysis tasks, achieving optimal performance. This automated framework dramatically reduces the workload for science data analyses, bringing us into the "Agent for Science" era.
vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
May 14, 2024


Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.
SheetAgent: A Generalist Agent for Spreadsheet Reasoning and Manipulation via Large Language Models
Mar 06, 2024Spreadsheet manipulation is widely existing in most daily works and significantly improves working efficiency. Large language model (LLM) has been recently attempted for automatic spreadsheet manipulation but has not yet been investigated in complicated and realistic tasks where reasoning challenges exist (e.g., long horizon manipulation with multi-step reasoning and ambiguous requirements). To bridge the gap with the real-world requirements, we introduce $\textbf{SheetRM}$, a benchmark featuring long-horizon and multi-category tasks with reasoning-dependent manipulation caused by real-life challenges. To mitigate the above challenges, we further propose $\textbf{SheetAgent}$, a novel autonomous agent that utilizes the power of LLMs. SheetAgent consists of three collaborative modules: $\textit{Planner}$, $\textit{Informer}$, and $\textit{Retriever}$, achieving both advanced reasoning and accurate manipulation over spreadsheets without human interaction through iterative task reasoning and reflection. Extensive experiments demonstrate that SheetAgent delivers 20-30% pass rate improvements on multiple benchmarks over baselines, achieving enhanced precision in spreadsheet manipulation and demonstrating superior table reasoning abilities. More details and visualizations are available at https://sheetagent.github.io.
Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models
Feb 22, 2024



Recently, there has been considerable attention towards leveraging large language models (LLMs) to enhance decision-making processes. However, aligning the natural language text instructions generated by LLMs with the vectorized operations required for execution presents a significant challenge, often necessitating task-specific details. To circumvent the need for such task-specific granularity, inspired by preference-based policy learning approaches, we investigate the utilization of multimodal LLMs to provide automated preference feedback solely from image inputs to guide decision-making. In this study, we train a multimodal LLM, termed CriticGPT, capable of understanding trajectory videos in robot manipulation tasks, serving as a critic to offer analysis and preference feedback. Subsequently, we validate the effectiveness of preference labels generated by CriticGPT from a reward modeling perspective. Experimental evaluation of the algorithm's preference accuracy demonstrates its effective generalization ability to new tasks. Furthermore, performance on Meta-World tasks reveals that CriticGPT's reward model efficiently guides policy learning, surpassing rewards based on state-of-the-art pre-trained representation models.