 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboPIN: Grounded Embodied Reasoning via Pinned Chain-of-Thought
Jun 14, 2026Embodied reasoning requires models to perceive task-relevant objects and spaces in physical environments and maintain consistent visual grounding throughout multi-step reasoning. However, current vision-language models rely on text-only or coordinate-augmented chain-of-thought, where entity references remain implicit and ambiguous. This may cause the reasoning process to decouple from visual evidence, entity references to drift across steps, and a causal disconnection between the reasoning trajectory and the final answer, with these problems further amplified in multi-view scenarios due to cross-view appearance changes. To address these issues, we propose Pinned Chain-of-Thought (\pincot{}), a structured reasoning paradigm that pins every reasoning step to visual evidence. \pincot{} introduces the concept of \reasoninganchor{}, which binds each task-relevant entity to a structured visual anchor with entity name, unique identity, view index, and spatial grounding, enabling consistent entity tracking across reasoning steps and views. We build a fully automated data generation pipeline to construct \dataset{}, a high-quality \pincot{}-formatted reasoning dataset. We then train \method{} through three-stage post-training that progressively injects embodied knowledge, structured reasoning ability, and process-supervised alignment, with rewards that directly constrain both anchor localization and identity consistency during reasoning. On 14 benchmarks covering embodied spatial reasoning, multi-view reasoning, and pointing, \method{} with only 4B parameters consistently outperforms 7B level open-source embodied models, achieving a 12\% average improvement over the strongest 7B baseline, Mimo-Embodied. Further analysis shows that \pincot{} improves grounding accuracy and cross-step identity consistency, validating the effectiveness of process supervision.
Embodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
Reformulate LLM Reinforcement Learning for Efficient Training under Black-box Discrepancy
Jun 09, 2026Reinforcement Learning (RL) has emerged as a pivotal post-training paradigm, yet it frequently suffers from unpredictable sub-optimum performance or even training collapses. Recent findings attribute these failures to a hidden train-inference discrepancy (or mismatch), stemming from the disparate underlying engines and architecture. We find that the training policy can actively self-correct such a discrepancy when provided with an appropriate learning signal. Then, we further empirically identify a discrepancy tolerance region: within this region, aggressively narrowing the discrepancy can suppress policy exploration and reduce learning efficiency, whereas outside this region, reducing excessive discrepancy improves optimization consistency and raises the achievable local performance ceiling. According to such findings, we formulate this problem as a Discrepancy-Constrained Markov Decision Process (DCMDP), where reward maximization is coupled with a constraint that aligns training-Inference behavior, achieving stable dual-objective optimization. To adaptively balance performance improvement and discrepancy control, we introduce a Lagrangian relaxation mechanism that dynamically adjusts the relative weight of the two objectives according to the current degree of discrepancy violation. This enables stable dual-objective optimization: the policy is allowed to explore freely within the tolerance region, while being guided back when the discrepancy exceeds the safe boundary. Empirically, DCMDP significantly improves the performance of 8B dense model (Qwen-3-8b) and 30B Mixture-of-Expert model (Qwen-3-30bA3b), and enables a heterogeneous training paradigm, where LLMs can be optimized in high-fidelity training setup while being explicitly aligned for low-cost, resource-constrained inference deployment.
The Rank and Gradient Lost in Non-stationarity: Sample Weight Decay for Mitigating Plasticity Loss in Reinforcement Learning
Apr 02, 2026Deep reinforcement learning (RL) suffers from plasticity loss severely due to the nature of non-stationarity, which impairs the ability to adapt to new data and learn continually. Unfortunately, our understanding of how plasticity loss arises, dissipates, and can be dissolved remains limited to empirical findings, leaving the theoretical end underexplored.To address this gap, we study the plasticity loss problem from the theoretical perspective of network optimization. By formally characterizing the two culprit factors in online RL process: the non-stationarity of data distributions and the non-stationarity of targets induced by bootstrapping, our theory attributes the loss of plasticity to two mechanisms: the rank collapse of the Neural Tangent Kernel (NTK) Gram matrix and the $Θ(\frac{1}{k})$ decay of gradient magnitude. The first mechanism echoes prior empirical findings from the theoretical perspective and sheds light on the effects of existing methods, e.g., network reset, neuron recycle, and noise injection. Against this backdrop, we focus primarily on the second mechanism and aim to alleviate plasticity loss by addressing the gradient attenuation issue, which is orthogonal to existing methods. We propose Sample Weight Decay -- a lightweight method to restore gradient magnitude, as a general remedy to plasticity loss for deep RL methods based on experience replay. In experiments, we evaluate the efficacy of \methodName upon TD3, \myadded{Double DQN} and SAC with SimBa architecture in MuJoCo, \myadded{ALE} and DeepMind Control Suite tasks. The results demonstrate that \methodName effectively alleviates plasticity loss and consistently improves learning performance across various configurations of deep RL algorithms, UTD, network architectures, and environments, achieving SOTA performance on challenging DMC Humanoid tasks.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025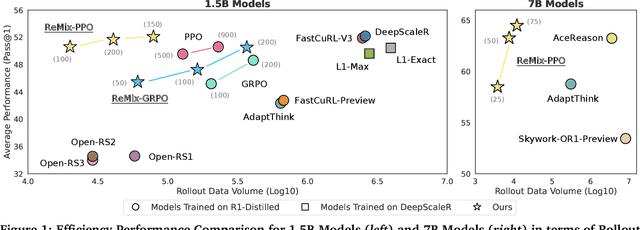
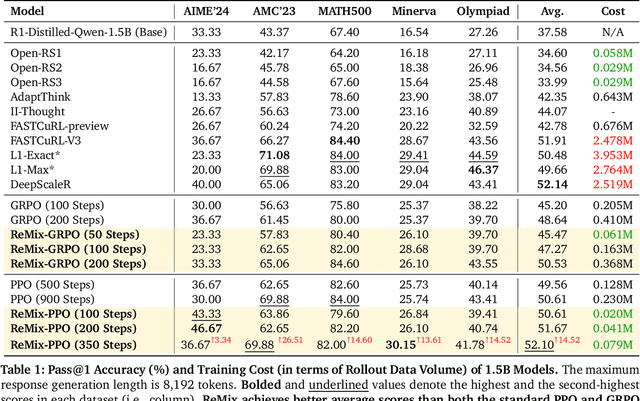
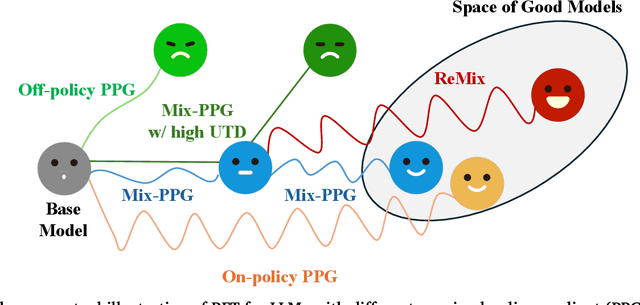

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
Can We Optimize Deep RL Policy Weights as Trajectory Modeling?
Mar 06, 2025

Learning the optimal policy from a random network initialization is the theme of deep Reinforcement Learning (RL). As the scale of DRL training increases, treating DRL policy network weights as a new data modality and exploring the potential becomes appealing and possible. In this work, we focus on the policy learning path in deep RL, represented by the trajectory of network weights of historical policies, which reflects the evolvement of the policy learning process. Taking the idea of trajectory modeling with Transformer, we propose Transformer as Implicit Policy Learner (TIPL), which processes policy network weights in an autoregressive manner. We collect the policy learning path data by running independent RL training trials, with which we then train our TIPL model. In the experiments, we demonstrate that TIPL is able to fit the implicit dynamics of policy learning and perform the optimization of policy network by inference.
Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer
Feb 04, 2025



Overestimation in single-agent reinforcement learning has been extensively studied. In contrast, overestimation in the multiagent setting has received comparatively little attention although it increases with the number of agents and leads to severe learning instability. Previous works concentrate on reducing overestimation in the estimation process of target Q-value. They ignore the follow-up optimization process of online Q-network, thus making it hard to fully address the complex multiagent overestimation problem. To solve this challenge, in this study, we first establish an iterative estimation-optimization analysis framework for multiagent value-mixing Q-learning. Our analysis reveals that multiagent overestimation not only comes from the computation of target Q-value but also accumulates in the online Q-network's optimization. Motivated by it, we propose the Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer algorithm to tackle multiagent overestimation from two aspects. First, we extend the random ensemble technique into the estimation of target individual and global Q-values to derive a lower update target. Second, we propose a novel hypernet regularizer on hypernetwork weights and biases to constrain the optimization of online global Q-network to prevent overestimation accumulation. Extensive experiments in MPE and SMAC show that the proposed method successfully addresses overestimation across various tasks.
Improving Deep Reinforcement Learning by Reducing the Chain Effect of Value and Policy Churn
Sep 07, 2024



Deep neural networks provide Reinforcement Learning (RL) powerful function approximators to address large-scale decision-making problems. However, these approximators introduce challenges due to the non-stationary nature of RL training. One source of the challenges in RL is that output predictions can churn, leading to uncontrolled changes after each batch update for states not included in the batch. Although such a churn phenomenon exists in each step of network training, how churn occurs and impacts RL remains under-explored. In this work, we start by characterizing churn in a view of Generalized Policy Iteration with function approximation, and we discover a chain effect of churn that leads to a cycle where the churns in value estimation and policy improvement compound and bias the learning dynamics throughout the iteration. Further, we concretize the study and focus on the learning issues caused by the chain effect in different settings, including greedy action deviation in value-based methods, trust region violation in proximal policy optimization, and dual bias of policy value in actor-critic methods. We then propose a method to reduce the chain effect across different settings, called Churn Approximated ReductIoN (CHAIN), which can be easily plugged into most existing DRL algorithms. Our experiments demonstrate the effectiveness of our method in both reducing churn and improving learning performance across online and offline, value-based and policy-based RL settings, as well as a scaling setting.
MFE-ETP: A Comprehensive Evaluation Benchmark for Multi-modal Foundation Models on Embodied Task Planning
Jul 06, 2024In recent years, Multi-modal Foundation Models (MFMs) and Embodied Artificial Intelligence (EAI) have been advancing side by side at an unprecedented pace. The integration of the two has garnered significant attention from the AI research community. In this work, we attempt to provide an in-depth and comprehensive evaluation of the performance of MFM s on embodied task planning, aiming to shed light on their capabilities and limitations in this domain. To this end, based on the characteristics of embodied task planning, we first develop a systematic evaluation framework, which encapsulates four crucial capabilities of MFMs: object understanding, spatio-temporal perception, task understanding, and embodied reasoning. Following this, we propose a new benchmark, named MFE-ETP, characterized its complex and variable task scenarios, typical yet diverse task types, task instances of varying difficulties, and rich test case types ranging from multiple embodied question answering to embodied task reasoning. Finally, we offer a simple and easy-to-use automatic evaluation platform that enables the automated testing of multiple MFMs on the proposed benchmark. Using the benchmark and evaluation platform, we evaluated several state-of-the-art MFMs and found that they significantly lag behind human-level performance. The MFE-ETP is a high-quality, large-scale, and challenging benchmark relevant to real-world tasks.