 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUMA: Empowering Unified MLLM with Multi-granular Visual Generation
Oct 17, 2024



Recent advancements in multimodal foundation models have yielded significant progress in vision-language understanding. Initial attempts have also explored the potential of multimodal large language models (MLLMs) for visual content generation. However, existing works have insufficiently addressed the varying granularity demands of different image generation tasks within a unified MLLM paradigm - from the diversity required in text-to-image generation to the precise controllability needed in image manipulation. In this work, we propose PUMA, emPowering Unified MLLM with Multi-grAnular visual generation. PUMA unifies multi-granular visual features as both inputs and outputs of MLLMs, elegantly addressing the different granularity requirements of various image generation tasks within a unified MLLM framework. Following multimodal pretraining and task-specific instruction tuning, PUMA demonstrates proficiency in a wide range of multimodal tasks. This work represents a significant step towards a truly unified MLLM capable of adapting to the granularity demands of various visual tasks. The code and model will be released in https://github.com/rongyaofang/PUMA.
big.LITTLE Vision Transformer for Efficient Visual Recognition
Oct 14, 2024



In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.
Mono-InternVL: Pushing the Boundaries of Monolithic Multimodal Large Language Models with Endogenous Visual Pre-training
Oct 10, 2024



The rapid advancement of Large Language Models (LLMs) has led to an influx of efforts to extend their capabilities to multimodal tasks. Among them, growing attention has been focused on monolithic Multimodal Large Language Models (MLLMs) that integrate visual encoding and language decoding into a single LLM. Despite the structural simplicity and deployment-friendliness, training a monolithic MLLM with promising performance still remains challenging. In particular, the popular approaches adopt continuous pre-training to extend a pre-trained LLM to a monolithic MLLM, which suffers from catastrophic forgetting and leads to performance degeneration. In this paper, we aim to overcome this limitation from the perspective of delta tuning. Specifically, our core idea is to embed visual parameters into a pre-trained LLM, thereby incrementally learning visual knowledge from massive data via delta tuning, i.e., freezing the LLM when optimizing the visual parameters. Based on this principle, we present Mono-InternVL, a novel monolithic MLLM that seamlessly integrates a set of visual experts via a multimodal mixture-of-experts structure. Moreover, we propose an innovative pre-training strategy to maximize the visual capability of Mono-InternVL, namely Endogenous Visual Pre-training (EViP). In particular, EViP is designed as a progressive learning process for visual experts, which aims to fully exploit the visual knowledge from noisy data to high-quality data. To validate our approach, we conduct extensive experiments on 16 benchmarks. Experimental results not only validate the superior performance of Mono-InternVL compared to the state-of-the-art MLLM on 6 multimodal benchmarks, e.g., +113 points over InternVL-1.5 on OCRBench, but also confirm its better deployment efficiency, with first token latency reduced by up to 67%.
MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
Aug 05, 2024



The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need. However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks. MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind. Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU. Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.
MMInstruct: A High-Quality Multi-Modal Instruction Tuning Dataset with Extensive Diversity
Jul 22, 2024



Despite the effectiveness of vision-language supervised fine-tuning in enhancing the performance of Vision Large Language Models (VLLMs). However, existing visual instruction tuning datasets include the following limitations: (1) Instruction annotation quality: despite existing VLLMs exhibiting strong performance, instructions generated by those advanced VLLMs may still suffer from inaccuracies, such as hallucinations. (2) Instructions and image diversity: the limited range of instruction types and the lack of diversity in image data may impact the model's ability to generate diversified and closer to real-world scenarios outputs. To address these challenges, we construct a high-quality, diverse visual instruction tuning dataset MMInstruct, which consists of 973K instructions from 24 domains. There are four instruction types: Judgement, Multiple-Choice, Long Visual Question Answering and Short Visual Question Answering. To construct MMInstruct, we propose an instruction generation data engine that leverages GPT-4V, GPT-3.5, and manual correction. Our instruction generation engine enables semi-automatic, low-cost, and multi-domain instruction generation at 1/6 the cost of manual construction. Through extensive experiment validation and ablation experiments, we demonstrate that MMInstruct could significantly improve the performance of VLLMs, e.g., the model fine-tuning on MMInstruct achieves new state-of-the-art performance on 10 out of 12 benchmarks. The code and data shall be available at https://github.com/yuecao0119/MMInstruct.
InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output
Jul 03, 2024



We present InternLM-XComposer-2.5 (IXC-2.5), a versatile large-vision language model that supports long-contextual input and output. IXC-2.5 excels in various text-image comprehension and composition applications, achieving GPT-4V level capabilities with merely 7B LLM backend. Trained with 24K interleaved image-text contexts, it can seamlessly extend to 96K long contexts via RoPE extrapolation. This long-context capability allows IXC-2.5 to excel in tasks requiring extensive input and output contexts. Compared to its previous 2.0 version, InternLM-XComposer-2.5 features three major upgrades in vision-language comprehension: (1) Ultra-High Resolution Understanding, (2) Fine-Grained Video Understanding, and (3) Multi-Turn Multi-Image Dialogue. In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles. IXC-2.5 has been evaluated on 28 benchmarks, outperforming existing open-source state-of-the-art models on 16 benchmarks. It also surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks. The InternLM-XComposer-2.5 is publicly available at https://github.com/InternLM/InternLM-XComposer.
Hierarchical Memory for Long Video QA
Jun 30, 2024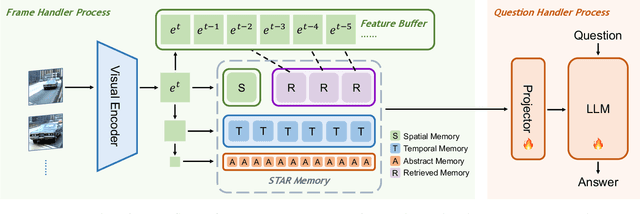
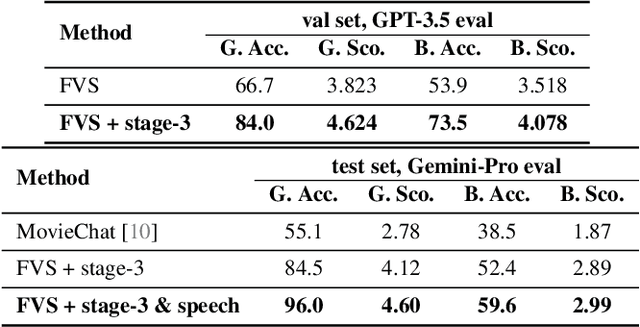
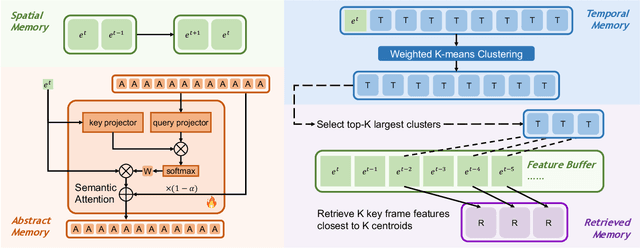
This paper describes our champion solution to the LOVEU Challenge @ CVPR'24, Track 1 (Long Video VQA). Processing long sequences of visual tokens is computationally expensive and memory-intensive, making long video question-answering a challenging task. The key is to compress visual tokens effectively, reducing memory footprint and decoding latency, while preserving the essential information for accurate question-answering. We adopt a hierarchical memory mechanism named STAR Memory, proposed in Flash-VStream, that is capable of processing long videos with limited GPU memory (VRAM). We further utilize the video and audio data of MovieChat-1K training set to fine-tune the pretrained weight released by Flash-VStream, achieving 1st place in the challenge. Code is available at project homepage https://invinciblewyq.github.io/vstream-page
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jun 20, 2024



Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
OmniCorpus: A Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 13, 2024



Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.
OmniCorpus: An Unified Multimodal Corpus of 10 Billion-Level Images Interleaved with Text
Jun 12, 2024Image-text interleaved data, consisting of multiple images and texts arranged in a natural document format, aligns with the presentation paradigm of internet data and closely resembles human reading habits. Recent studies have shown that such data aids multimodal in-context learning and maintains the capabilities of large language models during multimodal fine-tuning. However, the limited scale and diversity of current image-text interleaved data restrict the development of multimodal large language models. In this paper, we introduce OmniCorpus, a 10 billion-scale image-text interleaved dataset. Using an efficient data engine, we filter and extract large-scale high-quality documents, which contain 8.6 billion images and 1,696 billion text tokens. Compared to counterparts (e.g., MMC4, OBELICS), our dataset 1) has 15 times larger scales while maintaining good data quality; 2) features more diverse sources, including both English and non-English websites as well as video-centric websites; 3) is more flexible, easily degradable from an image-text interleaved format to pure text corpus and image-text pairs. Through comprehensive analysis and experiments, we validate the quality, usability, and effectiveness of the proposed dataset. We hope this could provide a solid data foundation for future multimodal model research. Code and data are released at https://github.com/OpenGVLab/OmniCorpus.