 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrainable Log-linear Sparse Attention for Efficient Diffusion Transformers
Dec 18, 2025



Diffusion Transformers (DiTs) set the state of the art in visual generation, yet their quadratic self-attention cost fundamentally limits scaling to long token sequences. Recent Top-K sparse attention approaches reduce the computation of DiTs by compressing tokens into block-wise representation and selecting a small set of relevant key blocks, but still suffer from (i) quadratic selection cost on compressed tokens and (ii) increasing K required to maintain model quality as sequences grow. We identify that their inefficiency is due to the single-level design, as a single coarse level is insufficient to represent the global structure. In this paper, we introduce Log-linear Sparse Attention (LLSA), a trainable sparse attention mechanism for extremely long token sequences that reduces both selection and attention costs from quadratic to log-linear complexity by utilizing a hierarchical structure. LLSA performs hierarchical Top-K selection, progressively adopting sparse Top-K selection with the indices found at the previous level, and introduces a Hierarchical KV Enrichment mechanism that preserves global context while using fewer tokens of different granularity during attention computation. To support efficient training, we develop a high-performance GPU implementation that uses only sparse indices for both the forward and backward passes, eliminating the need for dense attention masks. We evaluate LLSA on high-resolution pixel-space image generation without using patchification and VAE encoding. LLSA accelerates attention inference by 28.27x and DiT training by 6.09x on 256x256 pixel token sequences, while maintaining generation quality. The results demonstrate that LLSA offers a promising direction for training long-sequence DiTs efficiently. Code is available at: https://github.com/SingleZombie/LLSA
Recurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025
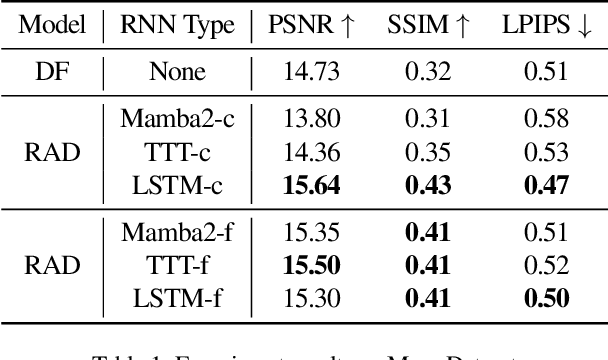

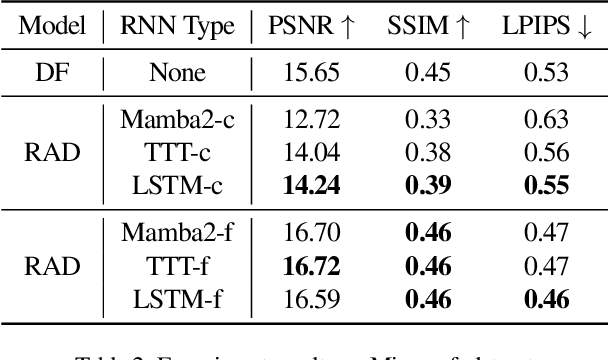
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
WORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025



World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
Alias-Free Latent Diffusion Models:Improving Fractional Shift Equivariance of Diffusion Latent Space
Mar 12, 2025Latent Diffusion Models (LDMs) are known to have an unstable generation process, where even small perturbations or shifts in the input noise can lead to significantly different outputs. This hinders their applicability in applications requiring consistent results. In this work, we redesign LDMs to enhance consistency by making them shift-equivariant. While introducing anti-aliasing operations can partially improve shift-equivariance, significant aliasing and inconsistency persist due to the unique challenges in LDMs, including 1) aliasing amplification during VAE training and multiple U-Net inferences, and 2) self-attention modules that inherently lack shift-equivariance. To address these issues, we redesign the attention modules to be shift-equivariant and propose an equivariance loss that effectively suppresses the frequency bandwidth of the features in the continuous domain. The resulting alias-free LDM (AF-LDM) achieves strong shift-equivariance and is also robust to irregular warping. Extensive experiments demonstrate that AF-LDM produces significantly more consistent results than vanilla LDM across various applications, including video editing and image-to-image translation. Code is available at: https://github.com/SingleZombie/AFLDM
Trajectory Attention for Fine-grained Video Motion Control
Nov 28, 2024



Recent advancements in video generation have been greatly driven by video diffusion models, with camera motion control emerging as a crucial challenge in creating view-customized visual content. This paper introduces trajectory attention, a novel approach that performs attention along available pixel trajectories for fine-grained camera motion control. Unlike existing methods that often yield imprecise outputs or neglect temporal correlations, our approach possesses a stronger inductive bias that seamlessly injects trajectory information into the video generation process. Importantly, our approach models trajectory attention as an auxiliary branch alongside traditional temporal attention. This design enables the original temporal attention and the trajectory attention to work in synergy, ensuring both precise motion control and new content generation capability, which is critical when the trajectory is only partially available. Experiments on camera motion control for images and videos demonstrate significant improvements in precision and long-range consistency while maintaining high-quality generation. Furthermore, we show that our approach can be extended to other video motion control tasks, such as first-frame-guided video editing, where it excels in maintaining content consistency over large spatial and temporal ranges.
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jun 20, 2024



Recent years have seen significant advancements in humanoid control, largely due to the availability of large-scale motion capture data and the application of reinforcement learning methodologies. However, many real-world tasks, such as moving large and heavy furniture, require multi-character collaboration. Given the scarcity of data on multi-character collaboration and the efficiency challenges associated with multi-agent learning, these tasks cannot be straightforwardly addressed using training paradigms designed for single-agent scenarios. In this paper, we introduce Cooperative Human-Object Interaction (CooHOI), a novel framework that addresses multi-character objects transporting through a two-phase learning paradigm: individual skill acquisition and subsequent transfer. Initially, a single agent learns to perform tasks using the Adversarial Motion Priors (AMP) framework. Following this, the agent learns to collaborate with others by considering the shared dynamics of the manipulated object during parallel training using Multi Agent Proximal Policy Optimization (MAPPO). When one agent interacts with the object, resulting in specific object dynamics changes, the other agents learn to respond appropriately, thereby achieving implicit communication and coordination between teammates. Unlike previous approaches that relied on tracking-based methods for multi-character HOI, CooHOI is inherently efficient, does not depend on motion capture data of multi-character interactions, and can be seamlessly extended to include more participants and a wide range of object types
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
May 23, 2024In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
Video Diffusion Models are Training-free Motion Interpreter and Controller
May 23, 2024



Video generation primarily aims to model authentic and customized motion across frames, making understanding and controlling the motion a crucial topic. Most diffusion-based studies on video motion focus on motion customization with training-based paradigms, which, however, demands substantial training resources and necessitates retraining for diverse models. Crucially, these approaches do not explore how video diffusion models encode cross-frame motion information in their features, lacking interpretability and transparency in their effectiveness. To answer this question, this paper introduces a novel perspective to understand, localize, and manipulate motion-aware features in video diffusion models. Through analysis using Principal Component Analysis (PCA), our work discloses that robust motion-aware feature already exists in video diffusion models. We present a new MOtion FeaTure (MOFT) by eliminating content correlation information and filtering motion channels. MOFT provides a distinct set of benefits, including the ability to encode comprehensive motion information with clear interpretability, extraction without the need for training, and generalizability across diverse architectures. Leveraging MOFT, we propose a novel training-free video motion control framework. Our method demonstrates competitive performance in generating natural and faithful motion, providing architecture-agnostic insights and applicability in a variety of downstream tasks.
Unified Human-Scene Interaction via Prompted Chain-of-Contacts
Sep 17, 2023



Human-Scene Interaction (HSI) is a vital component of fields like embodied AI and virtual reality. Despite advancements in motion quality and physical plausibility, two pivotal factors, versatile interaction control and the development of a user-friendly interface, require further exploration before the practical application of HSI. This paper presents a unified HSI framework, UniHSI, which supports unified control of diverse interactions through language commands. This framework is built upon the definition of interaction as Chain of Contacts (CoC): steps of human joint-object part pairs, which is inspired by the strong correlation between interaction types and human-object contact regions. Based on the definition, UniHSI constitutes a Large Language Model (LLM) Planner to translate language prompts into task plans in the form of CoC, and a Unified Controller that turns CoC into uniform task execution. To facilitate training and evaluation, we collect a new dataset named ScenePlan that encompasses thousands of task plans generated by LLMs based on diverse scenarios. Comprehensive experiments demonstrate the effectiveness of our framework in versatile task execution and generalizability to real scanned scenes. The project page is at https://github.com/OpenRobotLab/UniHSI .
Position-Guided Point Cloud Panoptic Segmentation Transformer
Mar 23, 2023DEtection TRansformer (DETR) started a trend that uses a group of learnable queries for unified visual perception. This work begins by applying this appealing paradigm to LiDAR-based point cloud segmentation and obtains a simple yet effective baseline. Although the naive adaptation obtains fair results, the instance segmentation performance is noticeably inferior to previous works. By diving into the details, we observe that instances in the sparse point clouds are relatively small to the whole scene and often have similar geometry but lack distinctive appearance for segmentation, which are rare in the image domain. Considering instances in 3D are more featured by their positional information, we emphasize their roles during the modeling and design a robust Mixed-parameterized Positional Embedding (MPE) to guide the segmentation process. It is embedded into backbone features and later guides the mask prediction and query update processes iteratively, leading to Position-Aware Segmentation (PA-Seg) and Masked Focal Attention (MFA). All these designs impel the queries to attend to specific regions and identify various instances. The method, named Position-guided Point cloud Panoptic segmentation transFormer (P3Former), outperforms previous state-of-the-art methods by 3.4% and 1.2% PQ on SemanticKITTI and nuScenes benchmark, respectively. The source code and models are available at https://github.com/SmartBot-PJLab/P3Former .