 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Laplacian Representation in Reinforcement Learning with Generalized Graph Drawing
Jul 12, 2021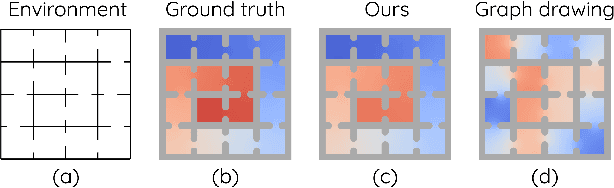

The Laplacian representation recently gains increasing attention for reinforcement learning as it provides succinct and informative representation for states, by taking the eigenvectors of the Laplacian matrix of the state-transition graph as state embeddings. Such representation captures the geometry of the underlying state space and is beneficial to RL tasks such as option discovery and reward shaping. To approximate the Laplacian representation in large (or even continuous) state spaces, recent works propose to minimize a spectral graph drawing objective, which however has infinitely many global minimizers other than the eigenvectors. As a result, their learned Laplacian representation may differ from the ground truth. To solve this problem, we reformulate the graph drawing objective into a generalized form and derive a new learning objective, which is proved to have eigenvectors as its unique global minimizer. It enables learning high-quality Laplacian representations that faithfully approximate the ground truth. We validate this via comprehensive experiments on a set of gridworld and continuous control environments. Moreover, we show that our learned Laplacian representations lead to more exploratory options and better reward shaping.
Recovering the Unbiased Scene Graphs from the Biased Ones
Jul 05, 2021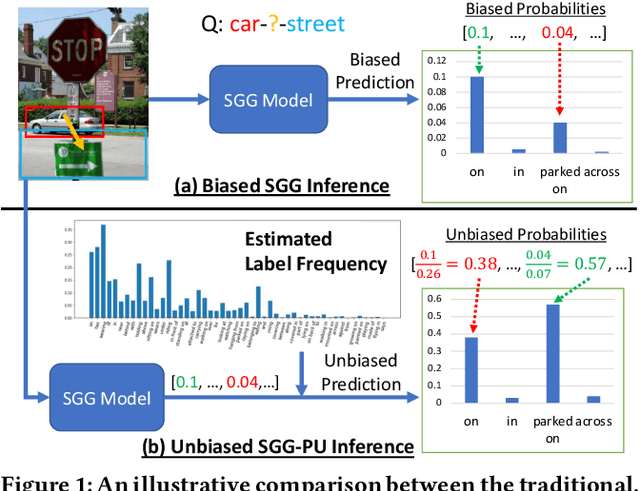
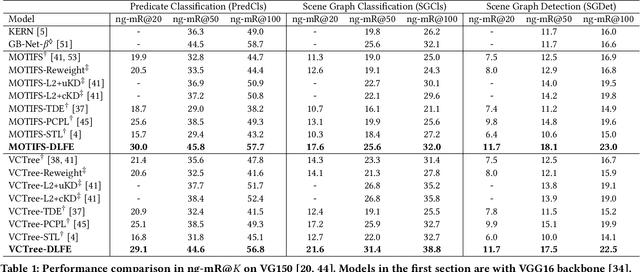
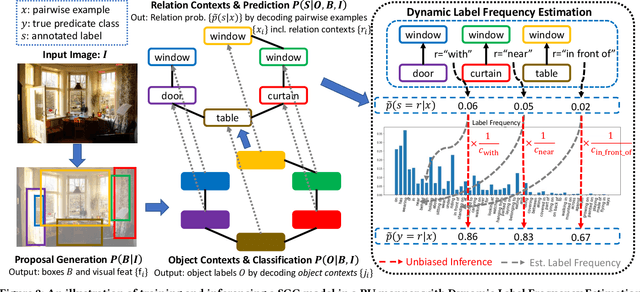
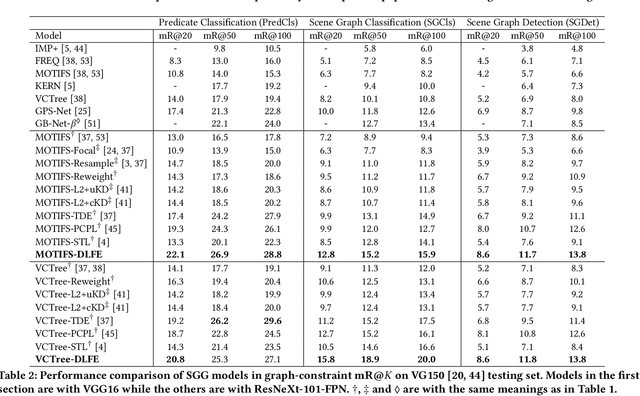
Given input images, scene graph generation (SGG) aims to produce comprehensive, graphical representations describing visual relationships among salient objects. Recently, more efforts have been paid to the long tail problem in SGG; however, the imbalance in the fraction of missing labels of different classes, or reporting bias, exacerbating the long tail is rarely considered and cannot be solved by the existing debiasing methods. In this paper we show that, due to the missing labels, SGG can be viewed as a "Learning from Positive and Unlabeled data" (PU learning) problem, where the reporting bias can be removed by recovering the unbiased probabilities from the biased ones by utilizing label frequencies, i.e., the per-class fraction of labeled, positive examples in all the positive examples. To obtain accurate label frequency estimates, we propose Dynamic Label Frequency Estimation (DLFE) to take advantage of training-time data augmentation and average over multiple training iterations to introduce more valid examples. Extensive experiments show that DLFE is more effective in estimating label frequencies than a naive variant of the traditional estimate, and DLFE significantly alleviates the long tail and achieves state-of-the-art debiasing performance on the VG dataset. We also show qualitatively that SGG models with DLFE produce prominently more balanced and unbiased scene graphs.
VOLO: Vision Outlooker for Visual Recognition
Jun 28, 2021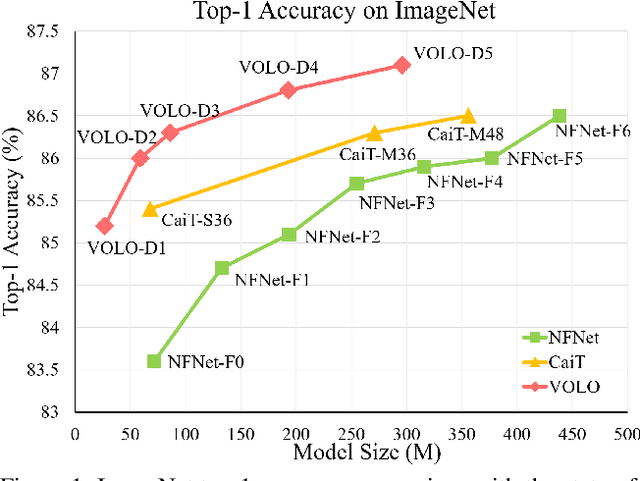
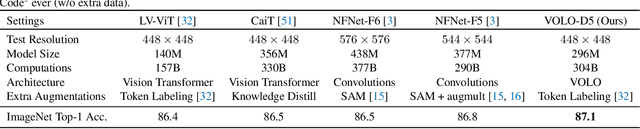
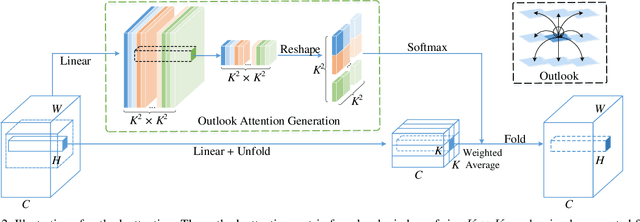

Visual recognition has been dominated by convolutional neural networks (CNNs) for years. Though recently the prevailing vision transformers (ViTs) have shown great potential of self-attention based models in ImageNet classification, their performance is still inferior to that of the latest SOTA CNNs if no extra data are provided. In this work, we try to close the performance gap and demonstrate that attention-based models are indeed able to outperform CNNs. We find a major factor limiting the performance of ViTs for ImageNet classification is their low efficacy in encoding fine-level features into the token representations. To resolve this, we introduce a novel outlook attention and present a simple and general architecture, termed Vision Outlooker (VOLO). Unlike self-attention that focuses on global dependency modeling at a coarse level, the outlook attention efficiently encodes finer-level features and contexts into tokens, which is shown to be critically beneficial to recognition performance but largely ignored by the self-attention. Experiments show that our VOLO achieves 87.1% top-1 accuracy on ImageNet-1K classification, which is the first model exceeding 87% accuracy on this competitive benchmark, without using any extra training data In addition, the pre-trained VOLO transfers well to downstream tasks, such as semantic segmentation. We achieve 84.3% mIoU score on the cityscapes validation set and 54.3% on the ADE20K validation set. Code is available at \url{https://github.com/sail-sg/volo}.
LV-BERT: Exploiting Layer Variety for BERT
Jun 25, 2021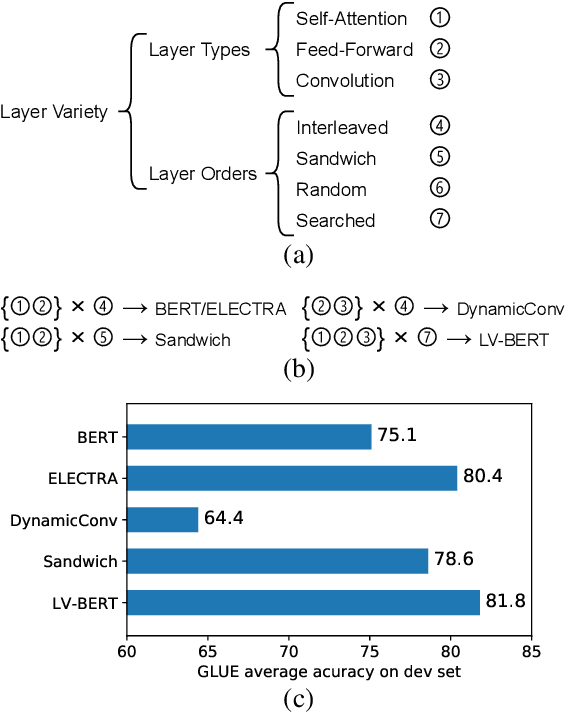
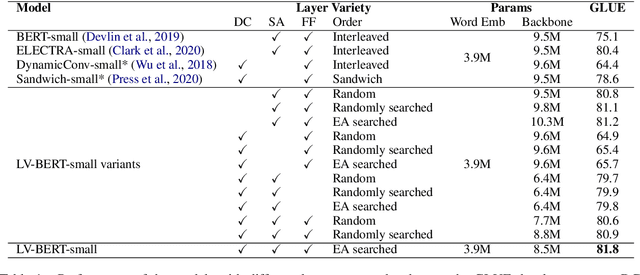
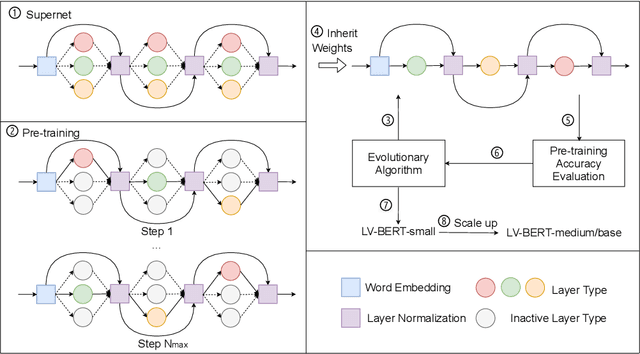
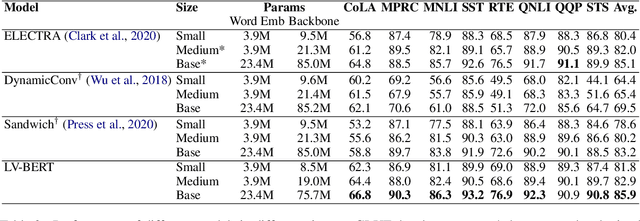
Modern pre-trained language models are mostly built upon backbones stacking self-attention and feed-forward layers in an interleaved order. In this paper, beyond this stereotyped layer pattern, we aim to improve pre-trained models by exploiting layer variety from two aspects: the layer type set and the layer order. Specifically, besides the original self-attention and feed-forward layers, we introduce convolution into the layer type set, which is experimentally found beneficial to pre-trained models. Furthermore, beyond the original interleaved order, we explore more layer orders to discover more powerful architectures. However, the introduced layer variety leads to a large architecture space of more than billions of candidates, while training a single candidate model from scratch already requires huge computation cost, making it not affordable to search such a space by directly training large amounts of candidate models. To solve this problem, we first pre-train a supernet from which the weights of all candidate models can be inherited, and then adopt an evolutionary algorithm guided by pre-training accuracy to find the optimal architecture. Extensive experiments show that LV-BERT model obtained by our method outperforms BERT and its variants on various downstream tasks. For example, LV-BERT-small achieves 79.8 on the GLUE testing set, 1.8 higher than the strong baseline ELECTRA-small.
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition
Jun 23, 2021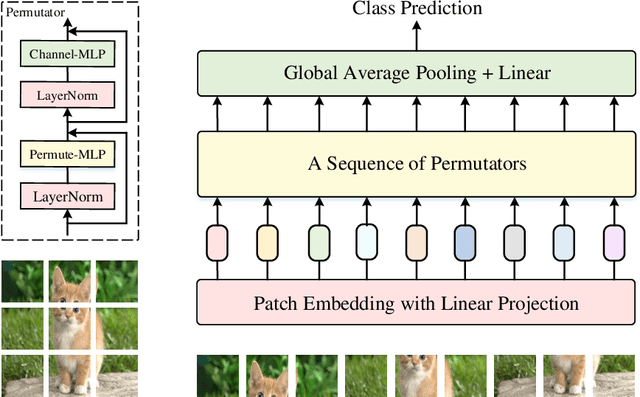
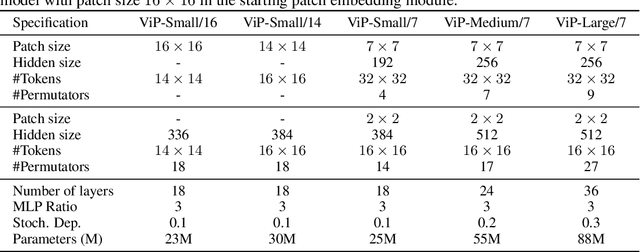
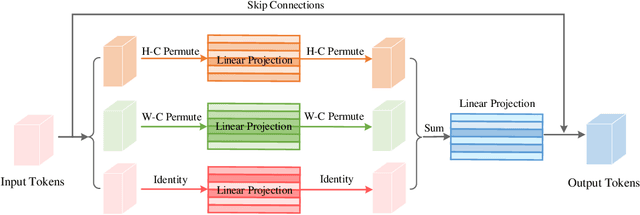
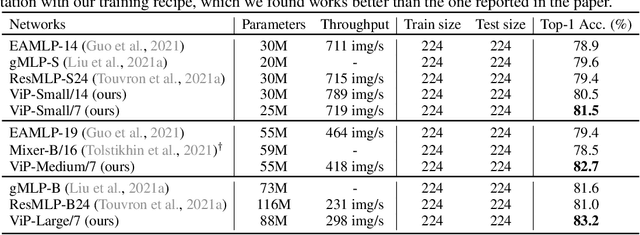
In this paper, we present Vision Permutator, a conceptually simple and data efficient MLP-like architecture for visual recognition. By realizing the importance of the positional information carried by 2D feature representations, unlike recent MLP-like models that encode the spatial information along the flattened spatial dimensions, Vision Permutator separately encodes the feature representations along the height and width dimensions with linear projections. This allows Vision Permutator to capture long-range dependencies along one spatial direction and meanwhile preserve precise positional information along the other direction. The resulting position-sensitive outputs are then aggregated in a mutually complementing manner to form expressive representations of the objects of interest. We show that our Vision Permutators are formidable competitors to convolutional neural networks (CNNs) and vision transformers. Without the dependence on spatial convolutions or attention mechanisms, Vision Permutator achieves 81.5% top-1 accuracy on ImageNet without extra large-scale training data (e.g., ImageNet-22k) using only 25M learnable parameters, which is much better than most CNNs and vision transformers under the same model size constraint. When scaling up to 88M, it attains 83.2% top-1 accuracy. We hope this work could encourage research on rethinking the way of encoding spatial information and facilitate the development of MLP-like models. Code is available at https://github.com/Andrew-Qibin/VisionPermutator.
No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data
Jun 09, 2021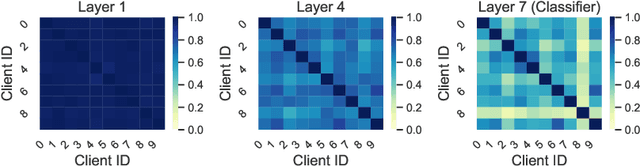
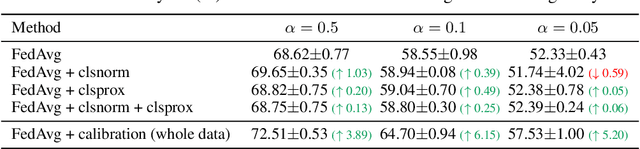
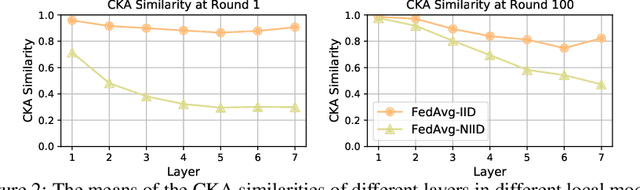
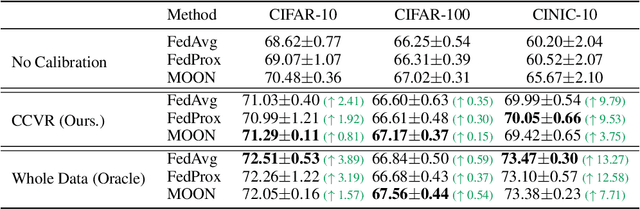
A central challenge in training classification models in the real-world federated system is learning with non-IID data. To cope with this, most of the existing works involve enforcing regularization in local optimization or improving the model aggregation scheme at the server. Other works also share public datasets or synthesized samples to supplement the training of under-represented classes or introduce a certain level of personalization. Though effective, they lack a deep understanding of how the data heterogeneity affects each layer of a deep classification model. In this paper, we bridge this gap by performing an experimental analysis of the representations learned by different layers. Our observations are surprising: (1) there exists a greater bias in the classifier than other layers, and (2) the classification performance can be significantly improved by post-calibrating the classifier after federated training. Motivated by the above findings, we propose a novel and simple algorithm called Classifier Calibration with Virtual Representations (CCVR), which adjusts the classifier using virtual representations sampled from an approximated gaussian mixture model. Experimental results demonstrate that CCVR achieves state-of-the-art performance on popular federated learning benchmarks including CIFAR-10, CIFAR-100, and CINIC-10. We hope that our simple yet effective method can shed some light on the future research of federated learning with non-IID data.
Refiner: Refining Self-attention for Vision Transformers
Jun 07, 2021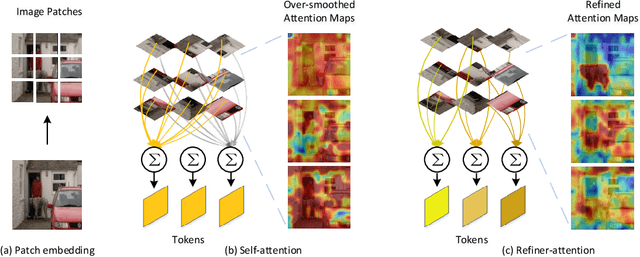
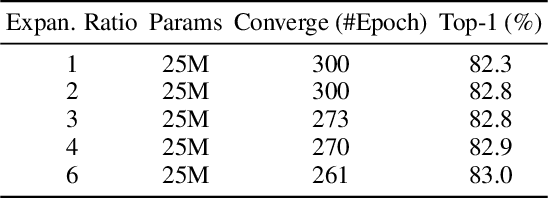
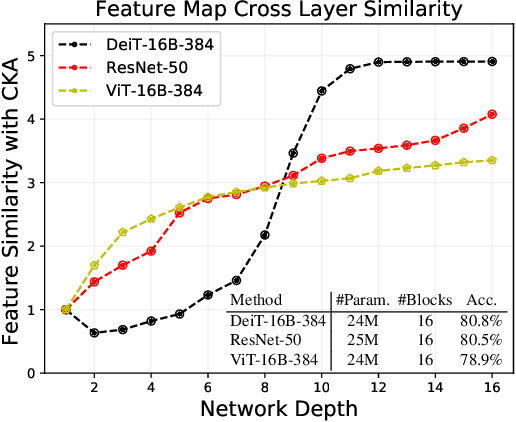
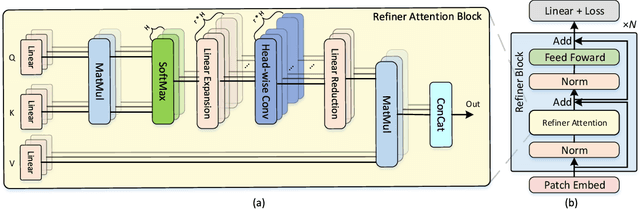
Vision Transformers (ViTs) have shown competitive accuracy in image classification tasks compared with CNNs. Yet, they generally require much more data for model pre-training. Most of recent works thus are dedicated to designing more complex architectures or training methods to address the data-efficiency issue of ViTs. However, few of them explore improving the self-attention mechanism, a key factor distinguishing ViTs from CNNs. Different from existing works, we introduce a conceptually simple scheme, called refiner, to directly refine the self-attention maps of ViTs. Specifically, refiner explores attention expansion that projects the multi-head attention maps to a higher-dimensional space to promote their diversity. Further, refiner applies convolutions to augment local patterns of the attention maps, which we show is equivalent to a distributed local attention features are aggregated locally with learnable kernels and then globally aggregated with self-attention. Extensive experiments demonstrate that refiner works surprisingly well. Significantly, it enables ViTs to achieve 86% top-1 classification accuracy on ImageNet with only 81M parameters.
Image-to-Video Generation via 3D Facial Dynamics
May 31, 2021
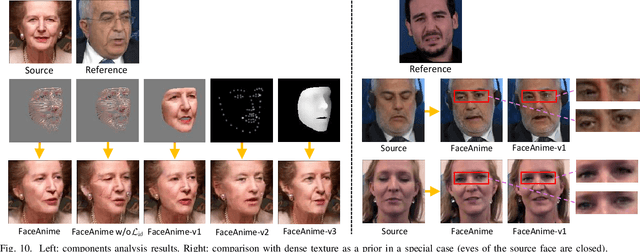
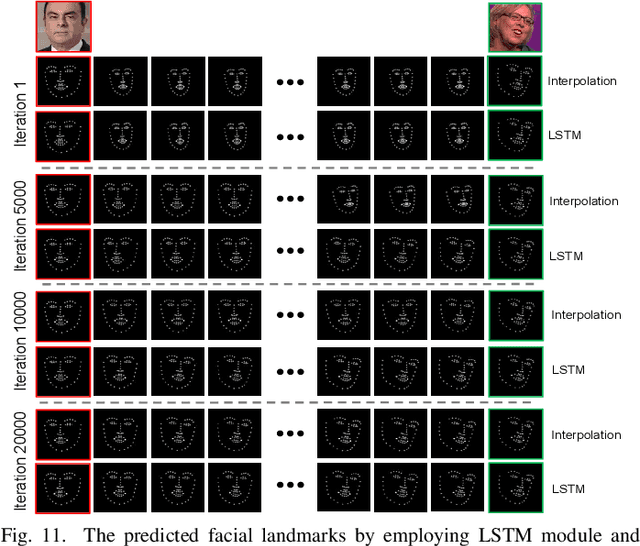
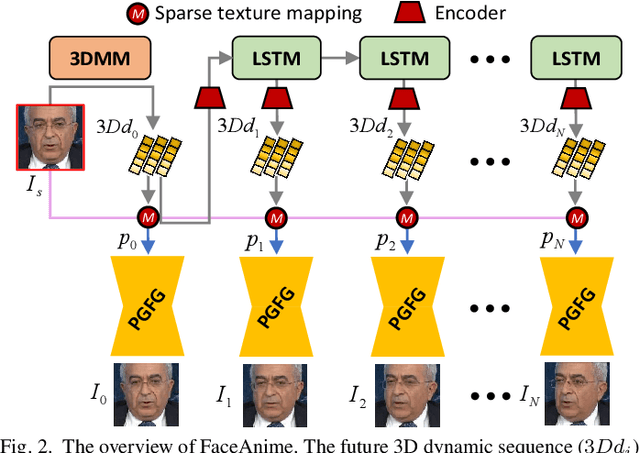
We present a versatile model, FaceAnime, for various video generation tasks from still images. Video generation from a single face image is an interesting problem and usually tackled by utilizing Generative Adversarial Networks (GANs) to integrate information from the input face image and a sequence of sparse facial landmarks. However, the generated face images usually suffer from quality loss, image distortion, identity change, and expression mismatching due to the weak representation capacity of the facial landmarks. In this paper, we propose to "imagine" a face video from a single face image according to the reconstructed 3D face dynamics, aiming to generate a realistic and identity-preserving face video, with precisely predicted pose and facial expression. The 3D dynamics reveal changes of the facial expression and motion, and can serve as a strong prior knowledge for guiding highly realistic face video generation. In particular, we explore face video prediction and exploit a well-designed 3D dynamic prediction network to predict a 3D dynamic sequence for a single face image. The 3D dynamics are then further rendered by the sparse texture mapping algorithm to recover structural details and sparse textures for generating face frames. Our model is versatile for various AR/VR and entertainment applications, such as face video retargeting and face video prediction. Superior experimental results have well demonstrated its effectiveness in generating high-fidelity, identity-preserving, and visually pleasant face video clips from a single source face image.
PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal
May 26, 2021
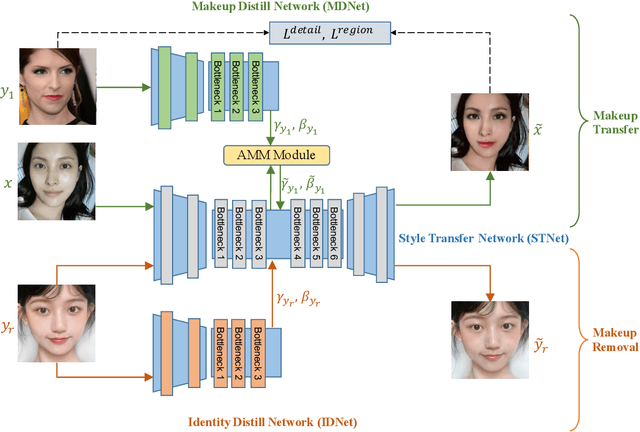
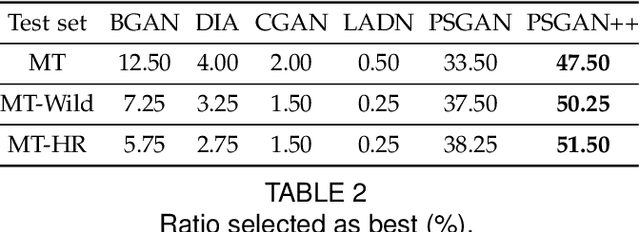
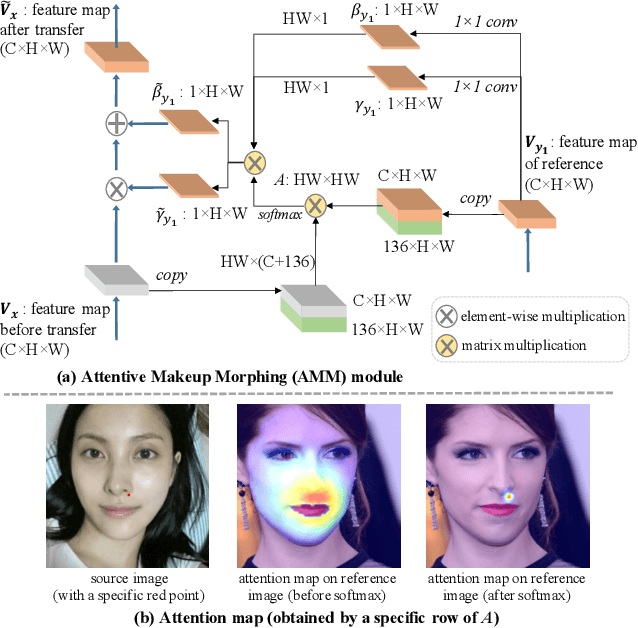
In this paper, we address the makeup transfer and removal tasks simultaneously, which aim to transfer the makeup from a reference image to a source image and remove the makeup from the with-makeup image respectively. Existing methods have achieved much advancement in constrained scenarios, but it is still very challenging for them to transfer makeup between images with large pose and expression differences, or handle makeup details like blush on cheeks or highlight on the nose. In addition, they are hardly able to control the degree of makeup during transferring or to transfer a specified part in the input face. In this work, we propose the PSGAN++, which is capable of performing both detail-preserving makeup transfer and effective makeup removal. For makeup transfer, PSGAN++ uses a Makeup Distill Network to extract makeup information, which is embedded into spatial-aware makeup matrices. We also devise an Attentive Makeup Morphing module that specifies how the makeup in the source image is morphed from the reference image, and a makeup detail loss to supervise the model within the selected makeup detail area. On the other hand, for makeup removal, PSGAN++ applies an Identity Distill Network to embed the identity information from with-makeup images into identity matrices. Finally, the obtained makeup/identity matrices are fed to a Style Transfer Network that is able to edit the feature maps to achieve makeup transfer or removal. To evaluate the effectiveness of our PSGAN++, we collect a Makeup Transfer In the Wild dataset that contains images with diverse poses and expressions and a Makeup Transfer High-Resolution dataset that contains high-resolution images. Experiments demonstrate that PSGAN++ not only achieves state-of-the-art results with fine makeup details even in cases of large pose/expression differences but also can perform partial or degree-controllable makeup transfer.
ST-HOI: A Spatial-Temporal Baseline for Human-Object Interaction Detection in Videos
May 25, 2021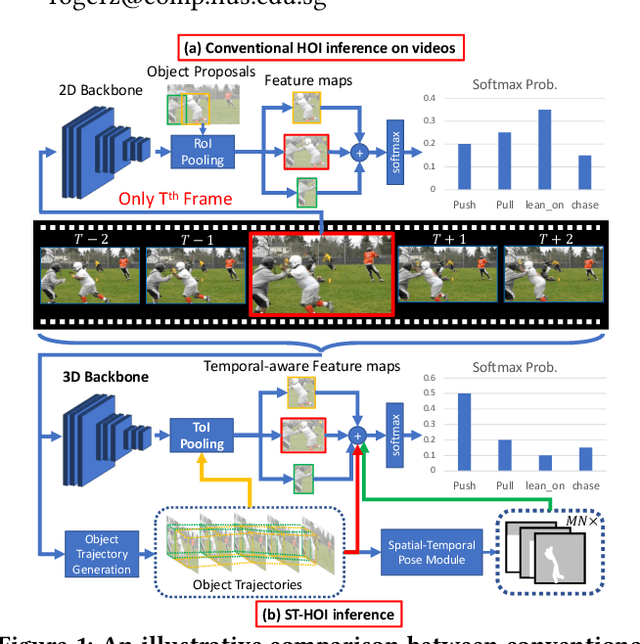

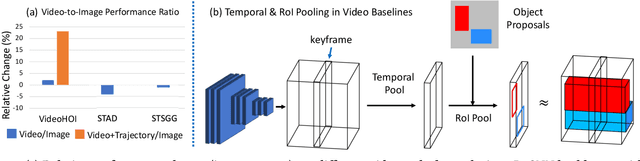
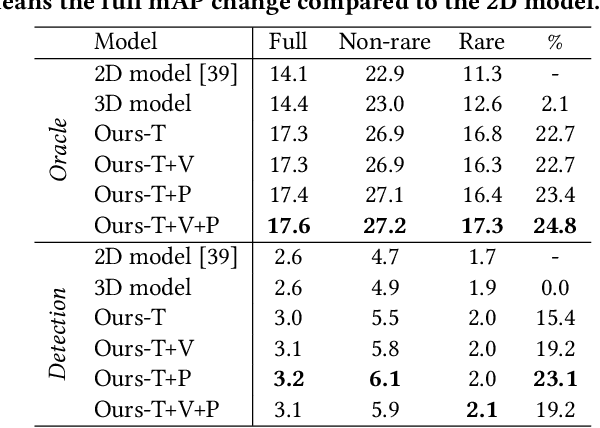
Detecting human-object interactions (HOI) is an important step toward a comprehensive visual understanding of machines. While detecting non-temporal HOIs (e.g., sitting on a chair) from static images is feasible, it is unlikely even for humans to guess temporal-related HOIs (e.g., opening/closing a door) from a single video frame, where the neighboring frames play an essential role. However, conventional HOI methods operating on only static images have been used to predict temporal-related interactions, which is essentially guessing without temporal contexts and may lead to sub-optimal performance. In this paper, we bridge this gap by detecting video-based HOIs with explicit temporal information. We first show that a naive temporal-aware variant of a common action detection baseline does not work on video-based HOIs due to a feature-inconsistency issue. We then propose a simple yet effective architecture named Spatial-Temporal HOI Detection (ST-HOI) utilizing temporal information such as human and object trajectories, correctly-localized visual features, and spatial-temporal masking pose features. We construct a new video HOI benchmark dubbed VidHOI where our proposed approach serves as a solid baseline.