 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structured Representations of Visual Scenes
Jul 09, 2022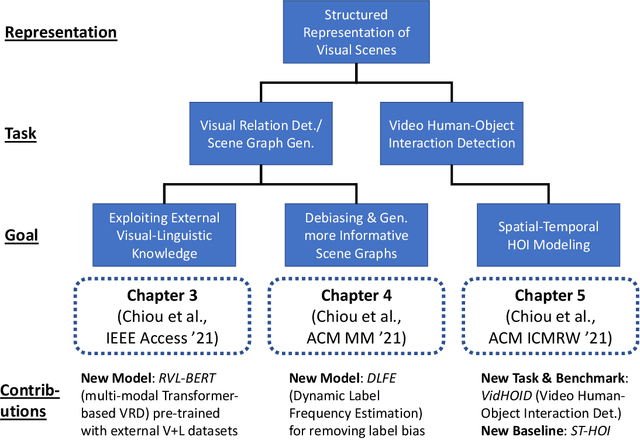

As the intermediate-level representations bridging the two levels, structured representations of visual scenes, such as visual relationships between pairwise objects, have been shown to not only benefit compositional models in learning to reason along with the structures but provide higher interpretability for model decisions. Nevertheless, these representations receive much less attention than traditional recognition tasks, leaving numerous open challenges unsolved. In the thesis, we study how machines can describe the content of the individual image or video with visual relationships as the structured representations. Specifically, we explore how structured representations of visual scenes can be effectively constructed and learned in both the static-image and video settings, with improvements resulting from external knowledge incorporation, bias-reducing mechanism, and enhanced representation models. At the end of this thesis, we also discuss some open challenges and limitations to shed light on future directions of structured representation learning for visual scenes.
Recovering the Unbiased Scene Graphs from the Biased Ones
Jul 05, 2021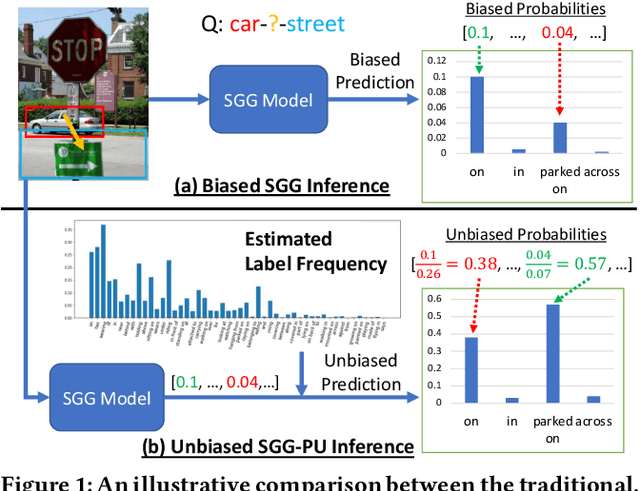
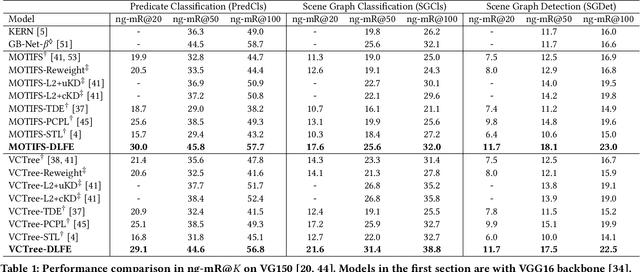
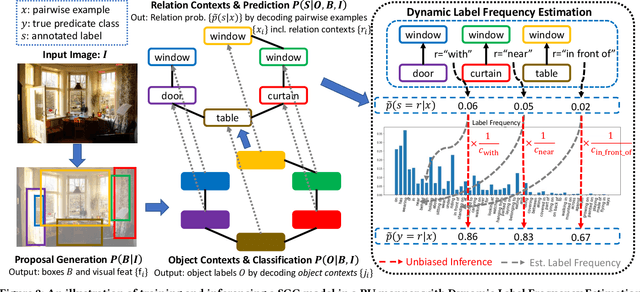
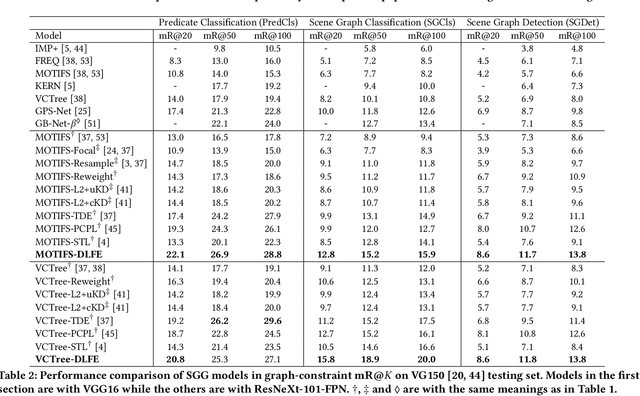
Given input images, scene graph generation (SGG) aims to produce comprehensive, graphical representations describing visual relationships among salient objects. Recently, more efforts have been paid to the long tail problem in SGG; however, the imbalance in the fraction of missing labels of different classes, or reporting bias, exacerbating the long tail is rarely considered and cannot be solved by the existing debiasing methods. In this paper we show that, due to the missing labels, SGG can be viewed as a "Learning from Positive and Unlabeled data" (PU learning) problem, where the reporting bias can be removed by recovering the unbiased probabilities from the biased ones by utilizing label frequencies, i.e., the per-class fraction of labeled, positive examples in all the positive examples. To obtain accurate label frequency estimates, we propose Dynamic Label Frequency Estimation (DLFE) to take advantage of training-time data augmentation and average over multiple training iterations to introduce more valid examples. Extensive experiments show that DLFE is more effective in estimating label frequencies than a naive variant of the traditional estimate, and DLFE significantly alleviates the long tail and achieves state-of-the-art debiasing performance on the VG dataset. We also show qualitatively that SGG models with DLFE produce prominently more balanced and unbiased scene graphs.
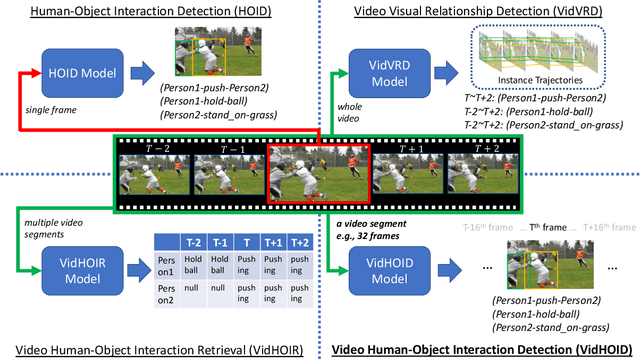
ST-HOI: A Spatial-Temporal Baseline for Human-Object Interaction Detection in Videos
May 25, 2021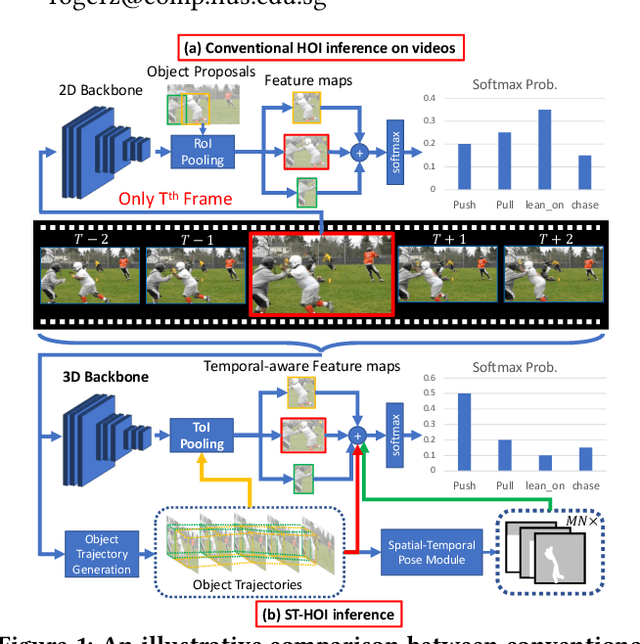

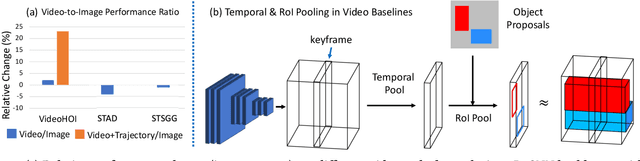
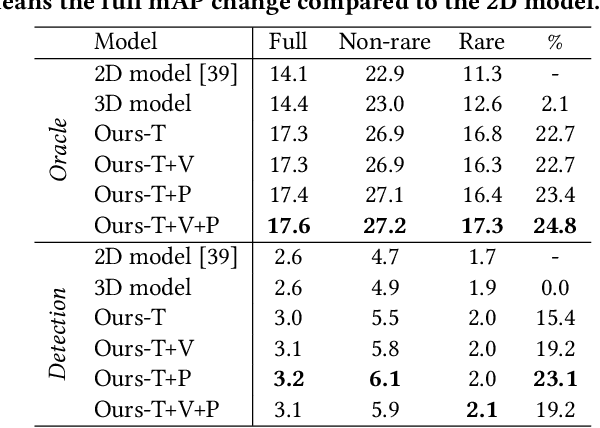
Detecting human-object interactions (HOI) is an important step toward a comprehensive visual understanding of machines. While detecting non-temporal HOIs (e.g., sitting on a chair) from static images is feasible, it is unlikely even for humans to guess temporal-related HOIs (e.g., opening/closing a door) from a single video frame, where the neighboring frames play an essential role. However, conventional HOI methods operating on only static images have been used to predict temporal-related interactions, which is essentially guessing without temporal contexts and may lead to sub-optimal performance. In this paper, we bridge this gap by detecting video-based HOIs with explicit temporal information. We first show that a naive temporal-aware variant of a common action detection baseline does not work on video-based HOIs due to a feature-inconsistency issue. We then propose a simple yet effective architecture named Spatial-Temporal HOI Detection (ST-HOI) utilizing temporal information such as human and object trajectories, correctly-localized visual features, and spatial-temporal masking pose features. We construct a new video HOI benchmark dubbed VidHOI where our proposed approach serves as a solid baseline.
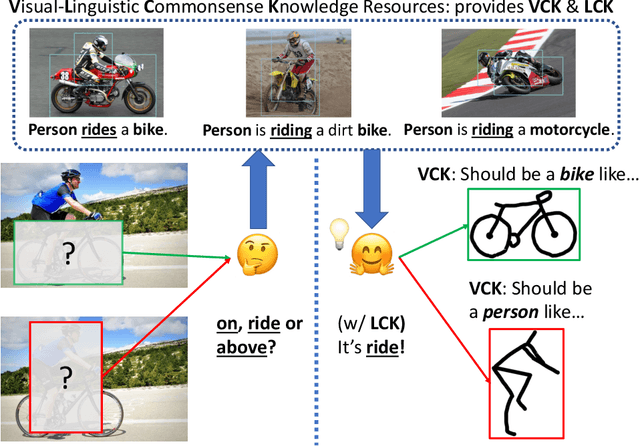
RVL-BERT: Visual Relationship Detection with Visual-Linguistic Knowledge from Pre-trained Representations
Sep 10, 2020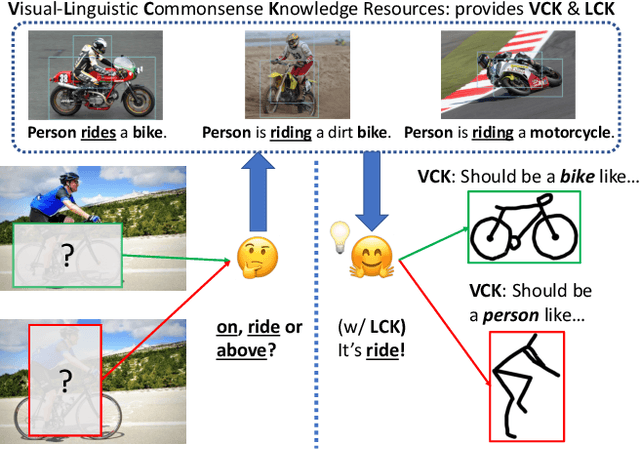

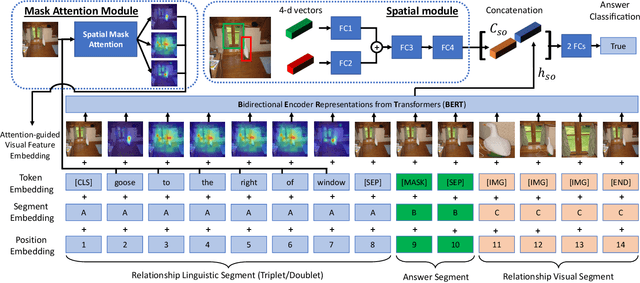
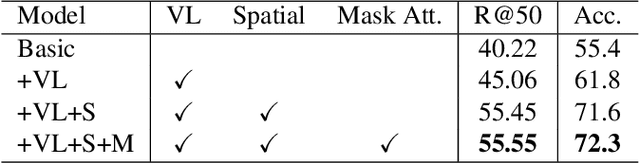
Visual relationship detection aims to reason over relationships among salient objects in images, which has drawn increasing attention over the past few years. Inspired by human reasoning mechanism, it is believed that external visual commonsense knowledge is beneficial for reasoning visual relationships of objects in images, which is however rarely considered in existing methods. In this paper, we propose a novel approach named Relational Visual-Linguistic Bidirectional Encoder Representations from Transformers (RVL-BERT), which performs relational reasoning with both visual and language commonsense knowledge learned via self-supervised pre-training with multimodal representations. RVL-BERT also uses an effective spatial module and a novel mask attention module to explicitly capture spatial information among the objects. Moreover, our model decouples object detection from visual relationship recognition by taking in object names directly, enabling it to be used on top of any object detection system. We show through quantitative and qualitative experiments that, with the transferred knowledge and novel modules, RVL-BERT surpasses previous state-of-the-art on two challenging visual relationship detection datasets. The source code will be publicly available soon.
Zero-Shot Multi-View Indoor Localization via Graph Location Networks
Aug 06, 2020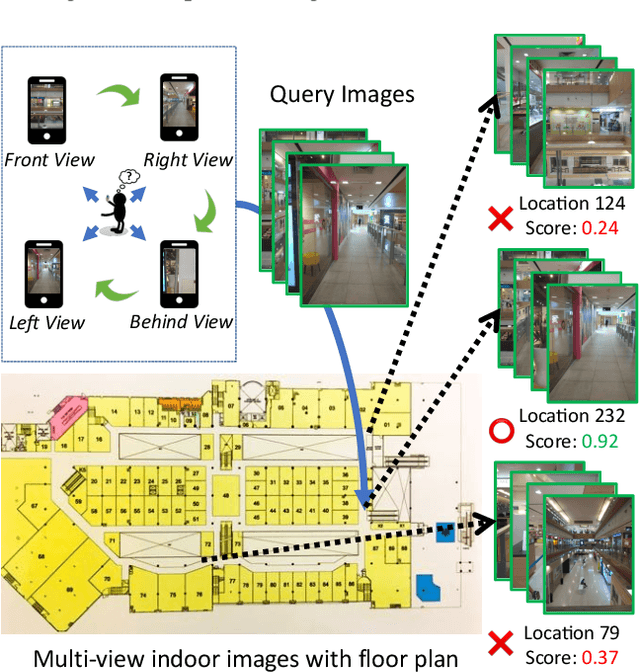
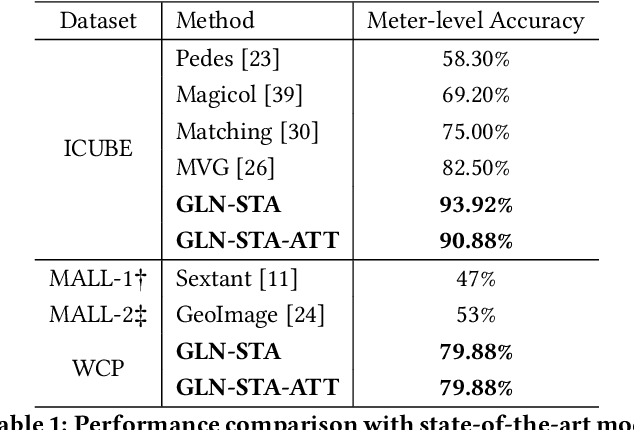
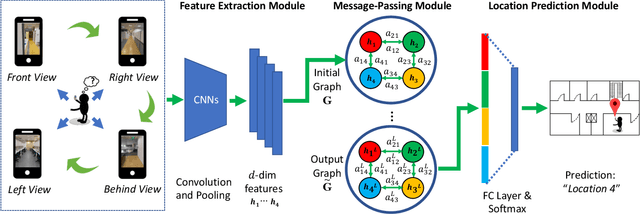
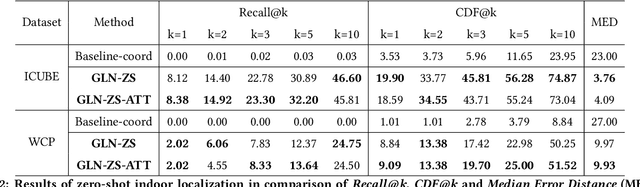
Indoor localization is a fundamental problem in location-based applications. Current approaches to this problem typically rely on Radio Frequency technology, which requires not only supporting infrastructures but human efforts to measure and calibrate the signal. Moreover, data collection for all locations is indispensable in existing methods, which in turn hinders their large-scale deployment. In this paper, we propose a novel neural network based architecture Graph Location Networks (GLN) to perform infrastructure-free, multi-view image based indoor localization. GLN makes location predictions based on robust location representations extracted from images through message-passing networks. Furthermore, we introduce a novel zero-shot indoor localization setting and tackle it by extending the proposed GLN to a dedicated zero-shot version, which exploits a novel mechanism Map2Vec to train location-aware embeddings and make predictions on novel unseen locations. Our extensive experiments show that the proposed approach outperforms state-of-the-art methods in the standard setting, and achieves promising accuracy even in the zero-shot setting where data for half of the locations are not available. The source code and datasets are publicly available at https://github.com/coldmanck/zero-shot-indoor-localization-release.
* Accepted at ACM MM 2020. 10 pages, 7 figures. Code and datasets available at https://github.com/coldmanck/zero-shot-indoor-localization-release