 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneWorld: Taming Scene Generation with 3D Unified Representation Autoencoder
Mar 17, 2026Existing diffusion-based 3D scene generation methods primarily operate in 2D image/video latent spaces, which makes maintaining cross-view appearance and geometric consistency inherently challenging. To bridge this gap, we present OneWorld, a framework that performs diffusion directly within a coherent 3D representation space. Central to our approach is the 3D Unified Representation Autoencoder (3D-URAE); it leverages pretrained 3D foundation models and augments their geometry-centric nature by injecting appearance and distilling semantics into a unified 3D latent space. Furthermore, we introduce token-level Cross-View-Correspondence (CVC) consistency loss to explicitly enforce structural alignment across views, and propose Manifold-Drift Forcing (MDF) to mitigate train-inference exposure bias and shape a robust 3D manifold by mixing drifted and original representations. Comprehensive experiments demonstrate that OneWorld generates high-quality 3D scenes with superior cross-view consistency compared to state-of-the-art 2D-based methods. Our code will be available at https://github.com/SensenGao/OneWorld.
MMGen: Unified Multi-modal Image Generation and Understanding in One Go
Mar 26, 2025A unified diffusion framework for multi-modal generation and understanding has the transformative potential to achieve seamless and controllable image diffusion and other cross-modal tasks. In this paper, we introduce MMGen, a unified framework that integrates multiple generative tasks into a single diffusion model. This includes: (1) multi-modal category-conditioned generation, where multi-modal outputs are generated simultaneously through a single inference process, given category information; (2) multi-modal visual understanding, which accurately predicts depth, surface normals, and segmentation maps from RGB images; and (3) multi-modal conditioned generation, which produces corresponding RGB images based on specific modality conditions and other aligned modalities. Our approach develops a novel diffusion transformer that flexibly supports multi-modal output, along with a simple modality-decoupling strategy to unify various tasks. Extensive experiments and applications demonstrate the effectiveness and superiority of MMGen across diverse tasks and conditions, highlighting its potential for applications that require simultaneous generation and understanding.
LaVin-DiT: Large Vision Diffusion Transformer
Nov 18, 2024This paper presents the Large Vision Diffusion Transformer (LaVin-DiT), a scalable and unified foundation model designed to tackle over 20 computer vision tasks in a generative framework. Unlike existing large vision models directly adapted from natural language processing architectures, which rely on less efficient autoregressive techniques and disrupt spatial relationships essential for vision data, LaVin-DiT introduces key innovations to optimize generative performance for vision tasks. First, to address the high dimensionality of visual data, we incorporate a spatial-temporal variational autoencoder that encodes data into a continuous latent space. Second, for generative modeling, we develop a joint diffusion transformer that progressively produces vision outputs. Third, for unified multi-task training, in-context learning is implemented. Input-target pairs serve as task context, which guides the diffusion transformer to align outputs with specific tasks within the latent space. During inference, a task-specific context set and test data as queries allow LaVin-DiT to generalize across tasks without fine-tuning. Trained on extensive vision datasets, the model is scaled from 0.1B to 3.4B parameters, demonstrating substantial scalability and state-of-the-art performance across diverse vision tasks. This work introduces a novel pathway for large vision foundation models, underscoring the promising potential of diffusion transformers. The code and models will be open-sourced.
TrackGo: A Flexible and Efficient Method for Controllable Video Generation
Aug 21, 2024



Recent years have seen substantial progress in diffusion-based controllable video generation. However, achieving precise control in complex scenarios, including fine-grained object parts, sophisticated motion trajectories, and coherent background movement, remains a challenge. In this paper, we introduce TrackGo, a novel approach that leverages free-form masks and arrows for conditional video generation. This method offers users with a flexible and precise mechanism for manipulating video content. We also propose the TrackAdapter for control implementation, an efficient and lightweight adapter designed to be seamlessly integrated into the temporal self-attention layers of a pretrained video generation model. This design leverages our observation that the attention map of these layers can accurately activate regions corresponding to motion in videos. Our experimental results demonstrate that our new approach, enhanced by the TrackAdapter, achieves state-of-the-art performance on key metrics such as FVD, FID, and ObjMC scores. The project page of TrackGo can be found at: https://zhtjtcz.github.io/TrackGo-Page/
Deep Understanding of Soccer Match Videos
Jul 11, 2024



Soccer is one of the most popular sport worldwide, with live broadcasts frequently available for major matches. However, extracting detailed, frame-by-frame information on player actions from these videos remains a challenge. Utilizing state-of-the-art computer vision technologies, our system can detect key objects such as soccer balls, players and referees. It also tracks the movements of players and the ball, recognizes player numbers, classifies scenes, and identifies highlights such as goal kicks. By analyzing live TV streams of soccer matches, our system can generate highlight GIFs, tactical illustrations, and diverse summary graphs of ongoing games. Through these visual recognition techniques, we deliver a comprehensive understanding of soccer game videos, enriching the viewer's experience with detailed and insightful analysis.
Contextual Text Block Detection towards Scene Text Understanding
Jul 26, 2022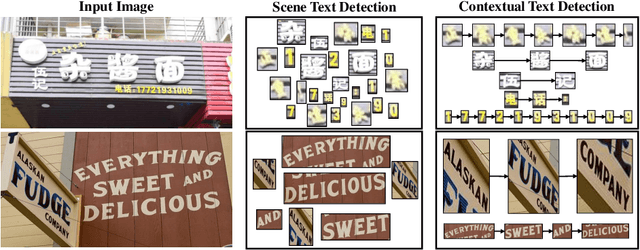

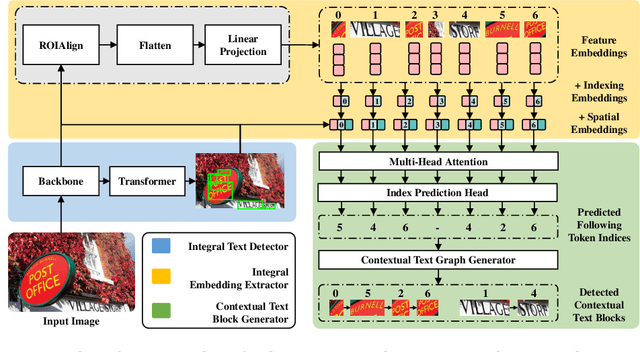
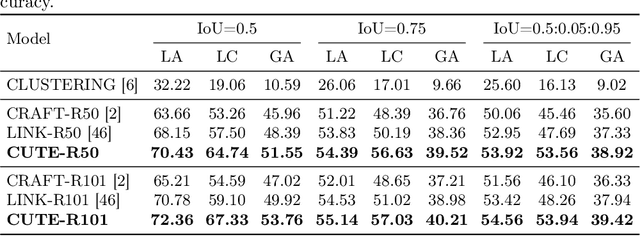
Most existing scene text detectors focus on detecting characters or words that only capture partial text messages due to missing contextual information. For a better understanding of text in scenes, it is more desired to detect contextual text blocks (CTBs) which consist of one or multiple integral text units (e.g., characters, words, or phrases) in natural reading order and transmit certain complete text messages. This paper presents contextual text detection, a new setup that detects CTBs for better understanding of texts in scenes. We formulate the new setup by a dual detection task which first detects integral text units and then groups them into a CTB. To this end, we design a novel scene text clustering technique that treats integral text units as tokens and groups them (belonging to the same CTB) into an ordered token sequence. In addition, we create two datasets SCUT-CTW-Context and ReCTS-Context to facilitate future research, where each CTB is well annotated by an ordered sequence of integral text units. Further, we introduce three metrics that measure contextual text detection in local accuracy, continuity, and global accuracy. Extensive experiments show that our method accurately detects CTBs which effectively facilitates downstream tasks such as text classification and translation. The project is available at https://sg-vilab.github.io/publication/xue2022contextual/.
Birds of A Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation
Apr 05, 2022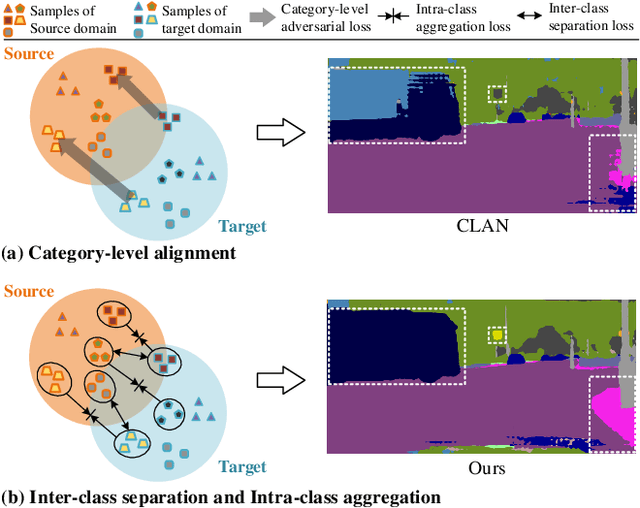

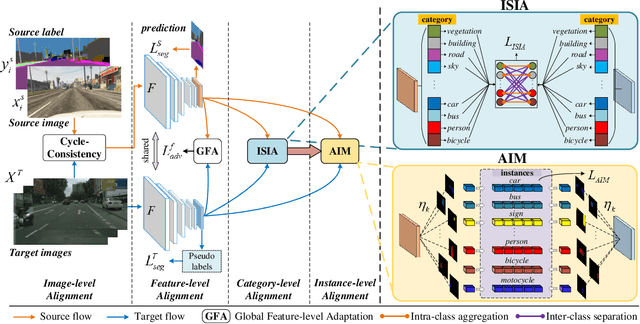
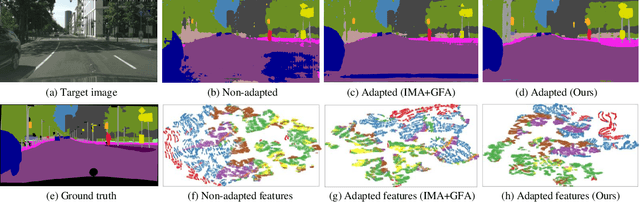
Unsupervised domain adaptation (UDA) aims to enhance the generalization capability of a certain model from a source domain to a target domain. Present UDA models focus on alleviating the domain shift by minimizing the feature discrepancy between the source domain and the target domain but usually ignore the class confusion problem. In this work, we propose an Inter-class Separation and Intra-class Aggregation (ISIA) mechanism. It encourages the cross-domain representative consistency between the same categories and differentiation among diverse categories. In this way, the features belonging to the same categories are aligned together and the confusable categories are separated. By measuring the align complexity of each category, we design an Adaptive-weighted Instance Matching (AIM) strategy to further optimize the instance-level adaptation. Based on our proposed methods, we also raise a hierarchical unsupervised domain adaptation framework for cross-domain semantic segmentation task. Through performing the image-level, feature-level, category-level and instance-level alignment, our method achieves a stronger generalization performance of the model from the source domain to the target domain. In two typical cross-domain semantic segmentation tasks, i.e., GTA5 to Cityscapes and SYNTHIA to Cityscapes, our method achieves the state-of-the-art segmentation accuracy. We also build two cross-domain semantic segmentation datasets based on the publicly available data, i.e., remote sensing building segmentation and road segmentation, for domain adaptive segmentation.
Content-Variant Reference Image Quality Assessment via Knowledge Distillation
Feb 26, 2022
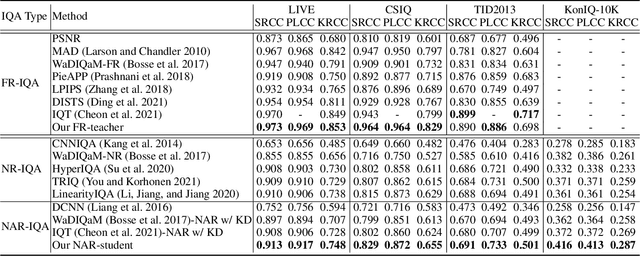
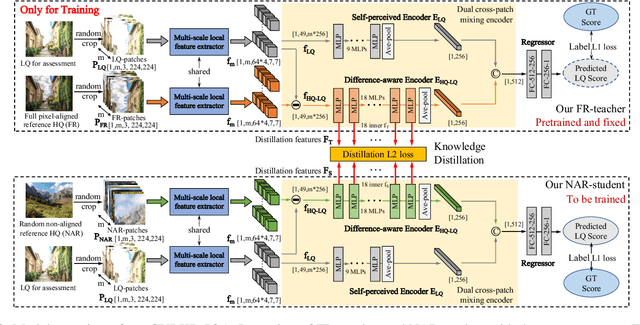

Generally, humans are more skilled at perceiving differences between high-quality (HQ) and low-quality (LQ) images than directly judging the quality of a single LQ image. This situation also applies to image quality assessment (IQA). Although recent no-reference (NR-IQA) methods have made great progress to predict image quality free from the reference image, they still have the potential to achieve better performance since HQ image information is not fully exploited. In contrast, full-reference (FR-IQA) methods tend to provide more reliable quality evaluation, but its practicability is affected by the requirement for pixel-level aligned reference images. To address this, we firstly propose the content-variant reference method via knowledge distillation (CVRKD-IQA). Specifically, we use non-aligned reference (NAR) images to introduce various prior distributions of high-quality images. The comparisons of distribution differences between HQ and LQ images can help our model better assess the image quality. Further, the knowledge distillation transfers more HQ-LQ distribution difference information from the FR-teacher to the NAR-student and stabilizing CVRKD-IQA performance. Moreover, to fully mine the local-global combined information, while achieving faster inference speed, our model directly processes multiple image patches from the input with the MLP-mixer. Cross-dataset experiments verify that our model can outperform all NAR/NR-IQA SOTAs, even reach comparable performance with FR-IQA methods on some occasions. Since the content-variant and non-aligned reference HQ images are easy to obtain, our model can support more IQA applications with its relative robustness to content variations. Our code and more detailed elaborations of supplements are available: https://github.com/guanghaoyin/CVRKD-IQA.
Time-Aware Neighbor Sampling for Temporal Graph Networks
Dec 18, 2021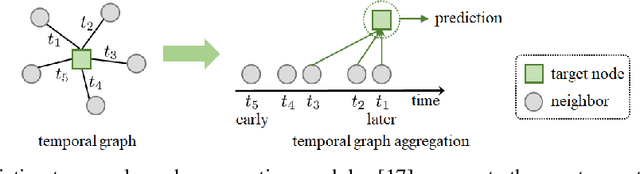


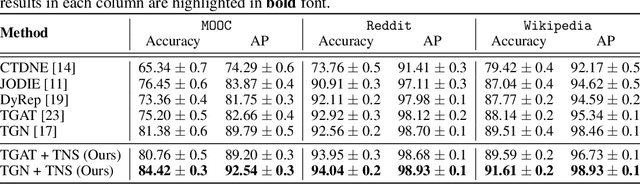
We present a new neighbor sampling method on temporal graphs. In a temporal graph, predicting different nodes' time-varying properties can require the receptive neighborhood of various temporal scales. In this work, we propose the TNS (Time-aware Neighbor Sampling) method: TNS learns from temporal information to provide an adaptive receptive neighborhood for every node at any time. Learning how to sample neighbors is non-trivial, since the neighbor indices in time order are discrete and not differentiable. To address this challenge, we transform neighbor indices from discrete values to continuous ones by interpolating the neighbors' messages. TNS can be flexibly incorporated into popular temporal graph networks to improve their effectiveness without increasing their time complexity. TNS can be trained in an end-to-end manner. It needs no extra supervision and is automatically and implicitly guided to sample the neighbors that are most beneficial for prediction. Empirical results on multiple standard datasets show that TNS yields significant gains on edge prediction and node classification.
Objects in Semantic Topology
Oct 06, 2021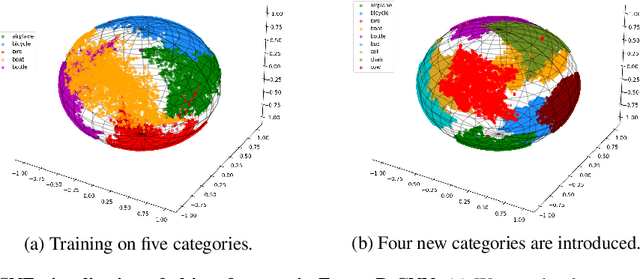
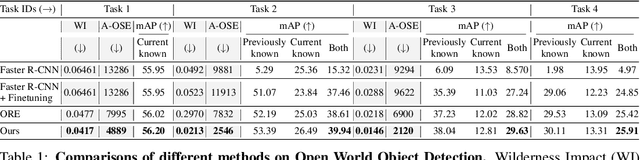
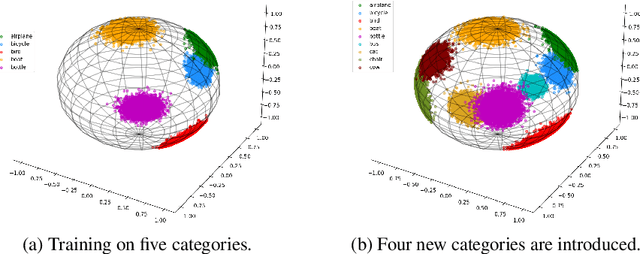
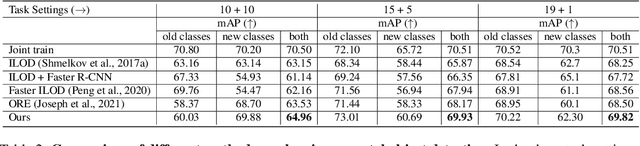
A more realistic object detection paradigm, Open-World Object Detection, has arisen increasing research interests in the community recently. A qualified open-world object detector can not only identify objects of known categories, but also discover unknown objects, and incrementally learn to categorize them when their annotations progressively arrive. Previous works rely on independent modules to recognize unknown categories and perform incremental learning, respectively. In this paper, we provide a unified perspective: Semantic Topology. During the life-long learning of an open-world object detector, all object instances from the same category are assigned to their corresponding pre-defined node in the semantic topology, including the `unknown' category. This constraint builds up discriminative feature representations and consistent relationships among objects, thus enabling the detector to distinguish unknown objects out of the known categories, as well as making learned features of known objects undistorted when learning new categories incrementally. Extensive experiments demonstrate that semantic topology, either randomly-generated or derived from a well-trained language model, could outperform the current state-of-the-art open-world object detectors by a large margin, e.g., the absolute open-set error is reduced from 7832 to 2546, exhibiting the inherent superiority of semantic topology on open-world object detection.