 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025



Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
May 01, 2025



Assessing how well a large language model (LLM) understands human, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM's higher-order social cognition. SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations. At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts. Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity. We also build a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena). SAGE thus provides a principled, scalable and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
Apr 27, 2025Evaluating the step-by-step reliability of large language model (LLM) reasoning, such as Chain-of-Thought, remains challenging due to the difficulty and cost of obtaining high-quality step-level supervision. In this paper, we introduce Self-Play Critic (SPC), a novel approach where a critic model evolves its ability to assess reasoning steps through adversarial self-play games, eliminating the need for manual step-level annotation. SPC involves fine-tuning two copies of a base model to play two roles, namely a "sneaky generator" that deliberately produces erroneous steps designed to be difficult to detect, and a "critic" that analyzes the correctness of reasoning steps. These two models engage in an adversarial game in which the generator aims to fool the critic, while the critic model seeks to identify the generator's errors. Using reinforcement learning based on the game outcomes, the models iteratively improve; the winner of each confrontation receives a positive reward and the loser receives a negative reward, driving continuous self-evolution. Experiments on three reasoning process benchmarks (ProcessBench, PRM800K, DeltaBench) demonstrate that our SPC progressively enhances its error detection capabilities (e.g., accuracy increases from 70.8% to 77.7% on ProcessBench) and surpasses strong baselines, including distilled R1 model. Furthermore, applying SPC to guide the test-time search of diverse LLMs significantly improves their mathematical reasoning performance on MATH500 and AIME2024, outperforming state-of-the-art process reward models.
Optimizing Multi-Round Enhanced Training in Diffusion Models for Improved Preference Understanding
Apr 25, 2025Generative AI has significantly changed industries by enabling text-driven image generation, yet challenges remain in achieving high-resolution outputs that align with fine-grained user preferences. Consequently, multi-round interactions are necessary to ensure the generated images meet expectations. Previous methods enhanced prompts via reward feedback but did not optimize over a multi-round dialogue dataset. In this work, we present a Visual Co-Adaptation (VCA) framework incorporating human-in-the-loop feedback, leveraging a well-trained reward model aligned with human preferences. Using a diverse multi-turn dialogue dataset, our framework applies multiple reward functions, such as diversity, consistency, and preference feedback, while fine-tuning the diffusion model through LoRA, thus optimizing image generation based on user input. We also construct multi-round dialogue datasets of prompts and image pairs aligned with user intent. Experiments demonstrate that our method outperforms state-of-the-art baselines, significantly improving image consistency and alignment with user intent. Our approach consistently surpasses competing models in user satisfaction, especially in multi-turn dialogue scenarios.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025


We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
Efficient Temporal Consistency in Diffusion-Based Video Editing with Adaptor Modules: A Theoretical Framework
Apr 22, 2025Adapter-based methods are commonly used to enhance model performance with minimal additional complexity, especially in video editing tasks that require frame-to-frame consistency. By inserting small, learnable modules into pretrained diffusion models, these adapters can maintain temporal coherence without extensive retraining. Approaches that incorporate prompt learning with both shared and frame-specific tokens are particularly effective in preserving continuity across frames at low training cost. In this work, we want to provide a general theoretical framework for adapters that maintain frame consistency in DDIM-based models under a temporal consistency loss. First, we prove that the temporal consistency objective is differentiable under bounded feature norms, and we establish a Lipschitz bound on its gradient. Second, we show that gradient descent on this objective decreases the loss monotonically and converges to a local minimum if the learning rate is within an appropriate range. Finally, we analyze the stability of modules in the DDIM inversion procedure, showing that the associated error remains controlled. These theoretical findings will reinforce the reliability of diffusion-based video editing methods that rely on adapter strategies and provide theoretical insights in video generation tasks.
Twin Co-Adaptive Dialogue for Progressive Image Generation
Apr 21, 2025



Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.
Supporting Urban Low-Altitude Economy: Channel Gain Map Inference Based on 3D Conditional GAN
Apr 17, 2025The advancement of advanced air mobility (AAM) in recent years has given rise to the concept of low-altitude economy (LAE). However, the diverse flight activities associated with the emerging LAE applications in urban scenarios confront complex physical environments, which urgently necessitates ubiquitous and reliable communication to guarantee the operation safety of the low-altitude aircraft. As one of promising technologies for the sixth generation (6G) mobile networks, channel knowledge map (CKM) enables the environment-aware communication by constructing a site-specific dataset, thereby providing a priori on-site information for the aircraft to obtain the channel state information (CSI) at arbitrary locations with much reduced online overhead. Diverse base station (BS) deployments in the three-dimensional (3D) urban low-altitude environment require efficient 3D CKM construction to capture spatial channel characteristics with less overhead. Towards this end, this paper proposes a 3D channel gain map (CGM) inference method based on a 3D conditional generative adversarial network (3D-CGAN). Specifically, we first analyze the potential deployment types of BSs in urban low-altitude scenario, and investigate the CGM representation with the corresponding 3D channel gain model. The framework of the proposed 3D-CGAN is then discussed, which is trained by a dataset consisting of existing CGMs. Consequently, the trained 3D-CGAN is capable of inferring the corresponding CGM only based on the BS coordinate without additional measurement. The simulation results demonstrate that the CGMs inferred by the proposed 3D-CGAN outperform those of the benchmark schemes, which can accurately reflect the radio propagation condition in 3D environment.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025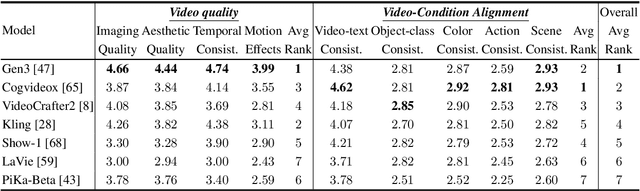
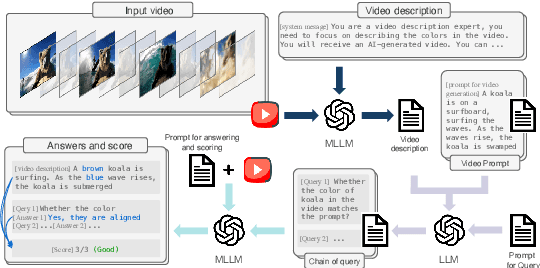
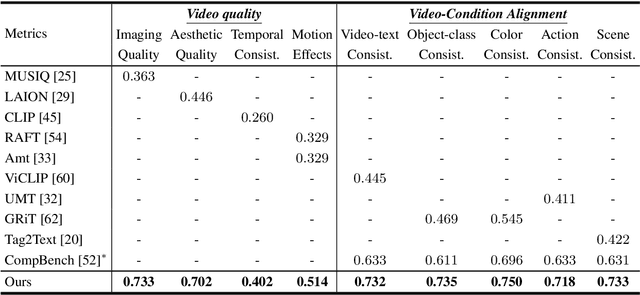
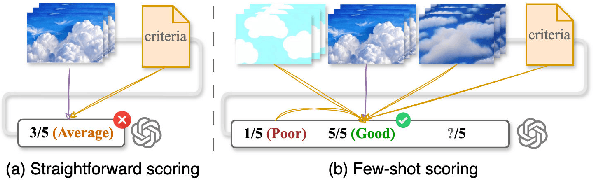
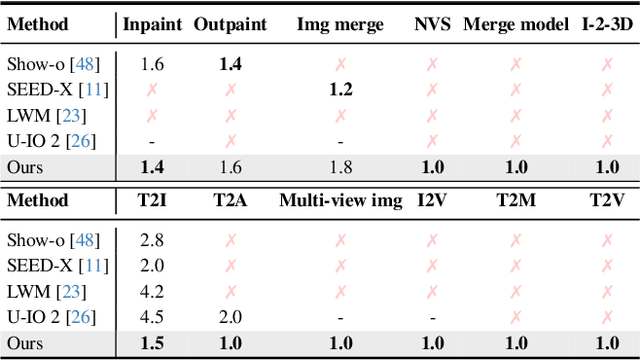
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.