 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed3R: Sparse Feed-forward 3D Reconstruction Models
Mar 09, 2026While recent feed-forward 3D reconstruction models accelerate 3D reconstruction by jointly inferring dense geometry and camera poses in a single pass, their reliance on dense attention imposes a quadratic complexity, creating a prohibitive computational bottleneck that severely limits inference speed. To resolve this, we introduce Speed3R, an end-to-end trainable model inspired by the core principle of Structure-from-Motion: that a sparse set of keypoints is sufficient for robust pose estimation. Speed3R features a dual-branch attention mechanism where a compression branch creates a coarse contextual prior to guide a selection branch, which performs fine-grained attention only on the most informative image tokens. This strategy mimics the efficiency of traditional keypoint matching, achieving a remarkable 12.4x inference speedup on 1000-view sequences, while introducing a minimal, controlled trade-off in geometric accuracy. Validated on standard benchmarks with both VGGT and $π^3$ backbones, our method delivers high-quality reconstructions at a fraction of computational cost, paving the way for efficient large-scale scene modeling.
Panoptic Captioning: Seeking An Equivalency Bridge for Image and Text
May 22, 2025



This work introduces panoptic captioning, a novel task striving to seek the minimum text equivalence of images. We take the first step towards panoptic captioning by formulating it as a task of generating a comprehensive textual description for an image, which encapsulates all entities, their respective locations and attributes, relationships among entities, as well as global image state.Through an extensive evaluation, our work reveals that state-of-the-art Multi-modal Large Language Models (MLLMs) have limited performance in solving panoptic captioning. To address this, we propose an effective data engine named PancapEngine to produce high-quality data and a novel method named PancapChain to improve panoptic captioning. Specifically, our PancapEngine first detects diverse categories of entities in images by an elaborate detection suite, and then generates required panoptic captions using entity-aware prompts. Additionally, our PancapChain explicitly decouples the challenging panoptic captioning task into multiple stages and generates panoptic captions step by step. More importantly, we contribute a comprehensive metric named PancapScore and a human-curated test set for reliable model evaluation.Experiments show that our PancapChain-13B model can beat state-of-the-art open-source MLLMs like InternVL-2.5-78B and even surpass proprietary models like GPT-4o and Gemini-2.0-Pro, demonstrating the effectiveness of our data engine and method. Project page: https://visual-ai.github.io/pancap/
NeRF On-the-go: Exploiting Uncertainty for Distractor-free NeRFs in the Wild
May 29, 2024



Neural Radiance Fields (NeRFs) have shown remarkable success in synthesizing photorealistic views from multi-view images of static scenes, but face challenges in dynamic, real-world environments with distractors like moving objects, shadows, and lighting changes. Existing methods manage controlled environments and low occlusion ratios but fall short in render quality, especially under high occlusion scenarios. In this paper, we introduce NeRF On-the-go, a simple yet effective approach that enables the robust synthesis of novel views in complex, in-the-wild scenes from only casually captured image sequences. Delving into uncertainty, our method not only efficiently eliminates distractors, even when they are predominant in captures, but also achieves a notably faster convergence speed. Through comprehensive experiments on various scenes, our method demonstrates a significant improvement over state-of-the-art techniques. This advancement opens new avenues for NeRF in diverse and dynamic real-world applications.
Out of the Room: Generalizing Event-Based Dynamic Motion Segmentation for Complex Scenes
Mar 07, 2024



Rapid and reliable identification of dynamic scene parts, also known as motion segmentation, is a key challenge for mobile sensors. Contemporary RGB camera-based methods rely on modeling camera and scene properties however, are often under-constrained and fall short in unknown categories. Event cameras have the potential to overcome these limitations, but corresponding methods have only been demonstrated in smaller-scale indoor environments with simplified dynamic objects. This work presents an event-based method for class-agnostic motion segmentation that can successfully be deployed across complex large-scale outdoor environments too. To this end, we introduce a novel divide-and-conquer pipeline that combines: (a) ego-motion compensated events, computed via a scene understanding module that predicts monocular depth and camera pose as auxiliary tasks, and (b) optical flow from a dedicated optical flow module. These intermediate representations are then fed into a segmentation module that predicts motion segmentation masks. A novel transformer-based temporal attention module in the segmentation module builds correlations across adjacent 'frames' to get temporally consistent segmentation masks. Our method sets the new state-of-the-art on the classic EV-IMO benchmark (indoors), where we achieve improvements of 2.19 moving object IoU (2.22 mIoU) and 4.52 point IoU respectively, as well as on a newly-generated motion segmentation and tracking benchmark (outdoors) based on the DSEC event dataset, termed DSEC-MOTS, where we show improvement of 12.91 moving object IoU.
3D Textured Shape Recovery with Learned Geometric Priors
Sep 07, 2022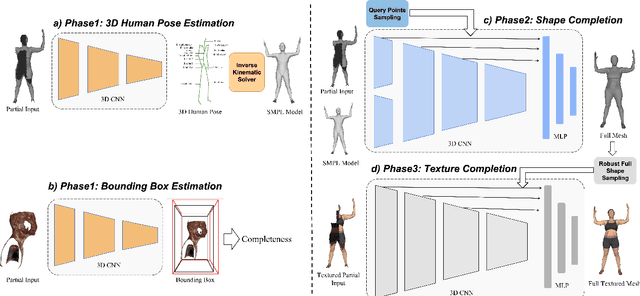
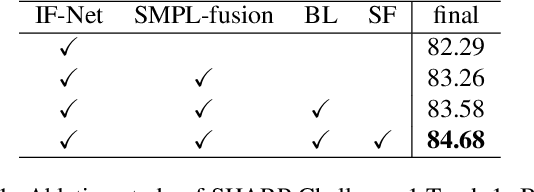

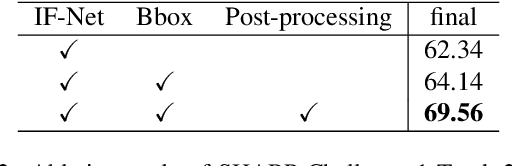
3D textured shape recovery from partial scans is crucial for many real-world applications. Existing approaches have demonstrated the efficacy of implicit function representation, but they suffer from partial inputs with severe occlusions and varying object types, which greatly hinders their application value in the real world. This technical report presents our approach to address these limitations by incorporating learned geometric priors. To this end, we generate a SMPL model from learned pose prediction and fuse it into the partial input to add prior knowledge of human bodies. We also propose a novel completeness-aware bounding box adaptation for handling different levels of scales and partialness of partial scans.