 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes Effective Supervision in Latent Chain-of-Thought: An Information-Theoretic Analysis
Jun 18, 2026Latent Chain-of-Thought (CoT) internalizes reasoning within continuous hidden states, offering a promising alternative to verbose discrete reasoning traces. However, robust latent reasoning remains difficult because outcome supervision provides weak learning signals and leaves latent trajectories prone to semantic drift. In this work, we analyze Latent CoT from an information-theoretic perspective and identify this failure as a dual collapse: gradient attenuation along the optimization path and representational drift in the latent space. We further decompose process supervision into two complementary dimensions: Trajectory Supervision, which injects dense stepwise reasoning signals, and Space Supervision, which preserves the semantic structure of the latent manifold. Our analysis shows that rigid geometric compression can collapse the reasoning space, whereas generative reconstruction provides a more flexible semantic anchor that better preserves information capacity. To measure these effects, we introduce the Unified Latent Probe (ULP), which quantifies the mutual information between latent trajectories and explicit reasoning steps. Experiments reveal a clear Information-Performance Binding: reasoning accuracy depends on the information fidelity preserved in the latent chain. These findings provide a principled framework for latent reasoning supervision and suggest shifting from geometric imitation toward mutual information maximization. Our code is available at \href{https://github.com/EIT-NLP/Supervision-in-Latent-CoT}{this repository}.
On the Geometry of On-Policy Distillation
Jun 05, 2026On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly understood. We characterize the trajectory of OPD updates in parameter space and compare it with supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). A suite of parameter-space diagnostics consistently places OPD in a relaxed off-principal regime: compared with SFT, its updates affect fewer weights and avoid principal directions more strongly, while compared with RLVR, they remain less tightly constrained. Beyond this static localization, OPD exhibits subspace locking: its cumulative updates rapidly enter a narrow low-dimensional channel. Constraining training to the update subspace formed early in training preserves OPD performance but substantially degrades SFT, indicating that the locked subspace is functionally sufficient for OPD. Control experiments further show that sparsifying the update tokens and shifting rollout generation off-policy preserve the rank dynamics, whereas mixing the OPD objective with RLVR changes them. Overall, these results suggest that OPD is not merely an intermediate point between SFT and RLVR, but induces its own update geometry in parameter space.
Probing Cultural Awareness in LLMs: A Case Study of Cross-Culture Aesthetic Stylistics
May 26, 2026Large Language Models (LLMs) are increasingly deployed in diverse cultural contexts, yet their ability to master aesthetic stylistics, i.e., the strategic use of language to evoke cultural resonance, remains underexplored. We curate C4STYLI, a benchmark of highly stylized translated movie titles and advertising slogans from Hong Kong and the Chinese Mainland, to evaluate LLMs via the lens of behavioral recognition and productive competence. Extensive evaluations show that LLMs differ from humans in stylistic recognition, and this recognition ability varies across text domains. In addition, stylistic recognition and generation performance in LLMs are not consistently aligned. To further examine whether LLMs genuinely capture stylistic information in stylistic recognition, we conduct structural ablation with logistic regression probes. We find that, in the Hong Kong setting, stylistic recognition in LLMs relies primarily on surface-level linguistic information rather than stylistic structure. This suggests limited sensitivity to Hong Kong-specific stylistic structure.
Finding RELIEF: Shaping Reasoning Behavior without Reasoning Supervision via Belief Engineering
Jan 20, 2026Large reasoning models (LRMs) have achieved remarkable success in complex problem-solving, yet they often suffer from computational redundancy or reasoning unfaithfulness. Current methods for shaping LRM behavior typically rely on reinforcement learning or fine-tuning with gold-standard reasoning traces, a paradigm that is both computationally expensive and difficult to scale. In this paper, we reveal that LRMs possess latent \textit{reasoning beliefs} that internally track their own reasoning traits, which can be captured through simple logit probing. Building upon this insight, we propose Reasoning Belief Engineering (RELIEF), a simple yet effective framework that shapes LRM behavior by aligning the model's self-concept with a target belief blueprint. Crucially, RELIEF completely bypasses the need for reasoning-trace supervision. It internalizes desired traits by fine-tuning on synthesized, self-reflective question-answering pairs that affirm the target belief. Extensive experiments on efficiency and faithfulness tasks demonstrate that RELIEF matches or outperforms behavior-supervised and preference-based baselines while requiring lower training costs. Further analysis validates that shifting a model's reasoning belief effectively shapes its actual behavior.
Evaluating Parameter Efficient Methods for RLVR
Dec 30, 2025We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies (\textit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction (\textit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution
May 27, 2025



Reinforcement learning (RL) holds significant promise for training LLM agents to handle complex, goal-oriented tasks that require multi-step interactions with external environments. However, a critical challenge when applying RL to these agentic tasks arises from delayed rewards: feedback signals are typically available only after the entire task is completed. This makes it non-trivial to assign delayed rewards to earlier actions, providing insufficient guidance regarding environmental constraints and hindering agent training. In this work, we draw on the insight that the ultimate completion of a task emerges from the cumulative progress an agent makes across individual steps. We propose Stepwise Progress Attribution (SPA), a general reward redistribution framework that decomposes the final reward into stepwise contributions, each reflecting its incremental progress toward overall task completion. To achieve this, we train a progress estimator that accumulates stepwise contributions over a trajectory to match the task completion. During policy optimization, we combine the estimated per-step contribution with a grounding signal for actions executed in the environment as the fine-grained, intermediate reward for effective agent training. Extensive experiments on common agent benchmarks (including Webshop, ALFWorld, and VirtualHome) demonstrate that SPA consistently outperforms the state-of-the-art method in both success rate (+2.5\% on average) and grounding accuracy (+1.9\% on average). Further analyses demonstrate that our method remarkably provides more effective intermediate rewards for RL training. Our code is available at https://github.com/WangHanLinHenry/SPA-RL-Agent.
Scaling over Scaling: Exploring Test-Time Scaling Pareto in Large Reasoning Models
May 26, 2025Large reasoning models (LRMs) have exhibited the capacity of enhancing reasoning performance via internal test-time scaling. Building upon this, a promising direction is to further scale test-time compute to unlock even greater reasoning capabilities. However, as we push these scaling boundaries, systematically understanding the practical limits and achieving optimal resource allocation becomes a critical challenge. In this paper, we investigate the scaling Pareto of test-time scaling and introduce the Test-Time Scaling Performance Model (TTSPM). We theoretically analyze two fundamental paradigms for such extended scaling, parallel scaling and sequential scaling, from a probabilistic modeling perspective. Our primary contribution is the derivation of the saturation point on the scaling budget for both strategies, identifying thresholds beyond which additional computation yields diminishing returns. Remarkably, despite their distinct mechanisms, both paradigms converge to a unified mathematical structure in their upper bounds. We empirically validate our theoretical findings on challenging reasoning benchmarks, including AIME, MATH-500, and GPQA, demonstrating the practical utility of these bounds for test-time resource allocation. We hope that this work provides insights into the cost-benefit trade-offs of test-time scaling, guiding the development of more resource-efficient inference strategies for large reasoning models.
KNN-SSD: Enabling Dynamic Self-Speculative Decoding via Nearest Neighbor Layer Set Optimization
May 22, 2025Speculative Decoding (SD) has emerged as a widely used paradigm to accelerate the inference of large language models (LLMs) without compromising generation quality. It works by efficiently drafting multiple tokens using a compact model and then verifying them in parallel using the target LLM. Notably, Self-Speculative Decoding proposes skipping certain layers to construct the draft model, which eliminates the need for additional parameters or training. Despite its strengths, we observe in this work that drafting with layer skipping exhibits significant sensitivity to domain shifts, leading to a substantial drop in acceleration performance. To enhance the domain generalizability of this paradigm, we introduce KNN-SSD, an algorithm that leverages K-Nearest Neighbor (KNN) search to match different skipped layers with various domain inputs. We evaluated our algorithm in various models and multiple tasks, observing that its application leads to 1.3x-1.6x speedup in LLM inference.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025

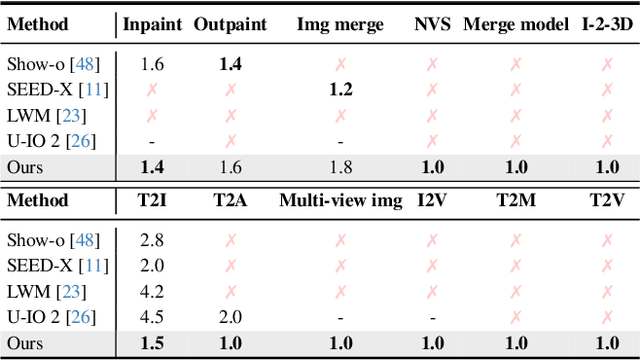

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
Video-Bench: Human-Aligned Video Generation Benchmark
Apr 07, 2025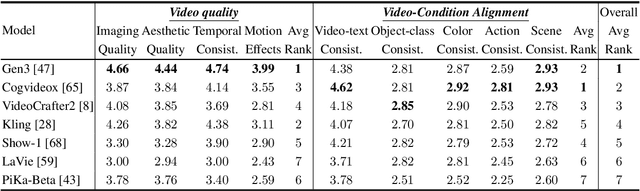
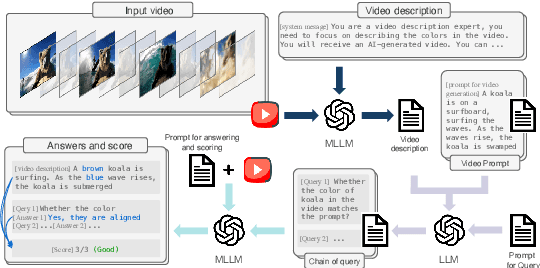
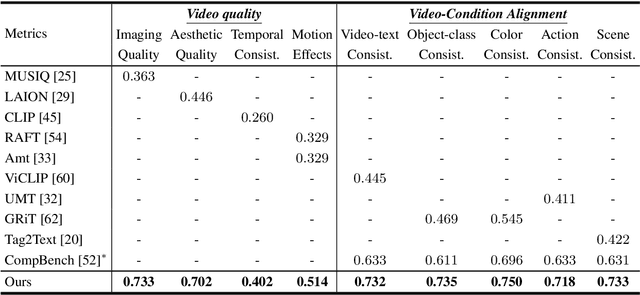
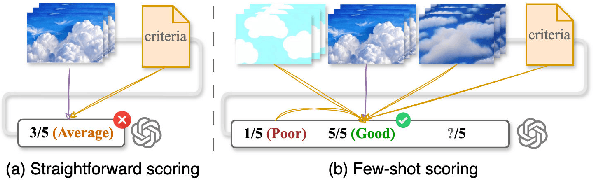
Video generation assessment is essential for ensuring that generative models produce visually realistic, high-quality videos while aligning with human expectations. Current video generation benchmarks fall into two main categories: traditional benchmarks, which use metrics and embeddings to evaluate generated video quality across multiple dimensions but often lack alignment with human judgments; and large language model (LLM)-based benchmarks, though capable of human-like reasoning, are constrained by a limited understanding of video quality metrics and cross-modal consistency. To address these challenges and establish a benchmark that better aligns with human preferences, this paper introduces Video-Bench, a comprehensive benchmark featuring a rich prompt suite and extensive evaluation dimensions. This benchmark represents the first attempt to systematically leverage MLLMs across all dimensions relevant to video generation assessment in generative models. By incorporating few-shot scoring and chain-of-query techniques, Video-Bench provides a structured, scalable approach to generated video evaluation. Experiments on advanced models including Sora demonstrate that Video-Bench achieves superior alignment with human preferences across all dimensions. Moreover, in instances where our framework's assessments diverge from human evaluations, it consistently offers more objective and accurate insights, suggesting an even greater potential advantage over traditional human judgment.