 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025

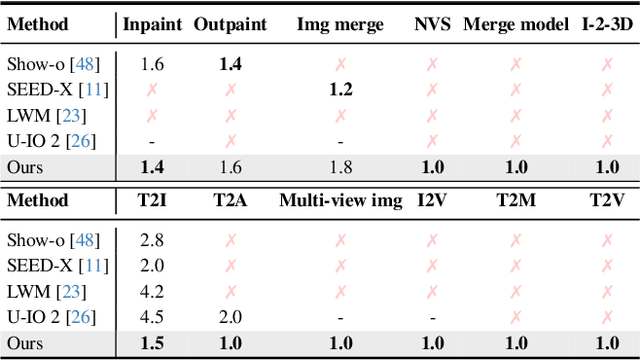

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
Imitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024


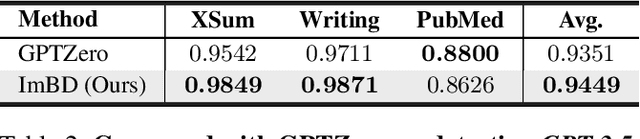
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
UR Channel-Robust Synthetic Speech Detection System for ASVspoof 2021
Aug 23, 2021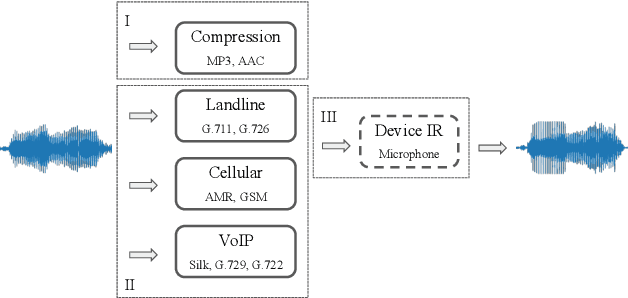
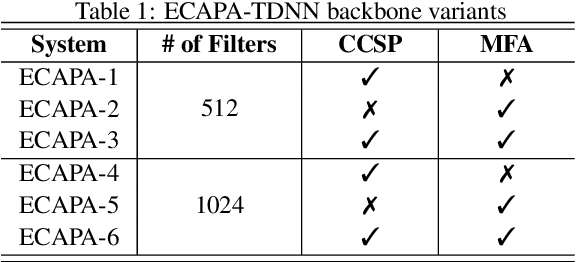
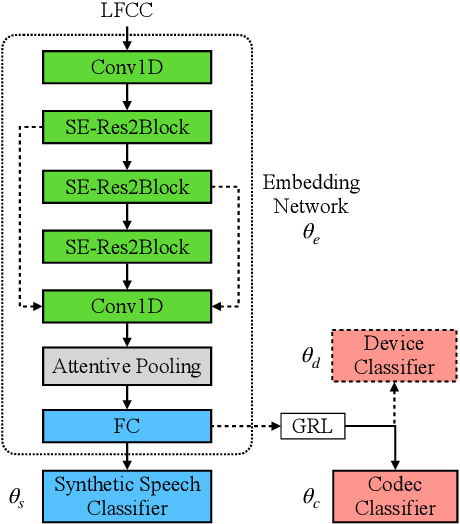
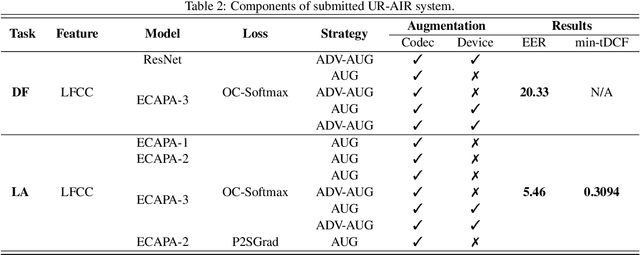
In this paper, we present UR-AIR system submission to the logical access (LA) and the speech deepfake (DF) tracks of the ASVspoof 2021 Challenge. The LA and DF tasks focus on synthetic speech detection (SSD), i.e. detecting text-to-speech and voice conversion as spoofing attacks. Different from previous ASVspoof challenges, the LA task this year presents codec and transmission channel variability, while the new task DF presents general audio compression. Built upon our previous research work on improving the robustness of the SSD systems to channel effects, we propose a channel-robust synthetic speech detection system for the challenge. To mitigate the channel variability issue, we use an acoustic simulator to apply transmission codec, compression codec, and convolutional impulse responses to augmenting the original datasets. For the neural network backbone, we propose to use Emphasized Channel Attention, Propagation and Aggregation Time Delay Neural Networks (ECAPA-TDNN) as our primary model. We also incorporate one-class learning with channel-robust training strategies to further learn a channel-invariant speech representation. Our submission achieved EER 20.33% in the DF task; EER 5.46% and min-tDCF 0.3094 in the LA task.