 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRWKV:Frequency-Domain Linear Attention for Long-Term Time Series Forecasting
Dec 09, 2025Traditional Transformers face a major bottleneck in long-sequence time series forecasting due to their quadratic complexity $(\mathcal{O}(T^2))$ and their limited ability to effectively exploit frequency-domain information. Inspired by RWKV's $\mathcal{O}(T)$ linear attention and frequency-domain modeling, we propose FRWKV, a frequency-domain linear-attention framework that overcomes these limitations. Our model integrates linear attention mechanisms with frequency-domain analysis, achieving $\mathcal{O}(T)$ computational complexity in the attention path while exploiting spectral information to enhance temporal feature representations for scalable long-sequence modeling. Across eight real-world datasets, FRWKV achieves a first-place average rank. Our ablation studies confirm the critical roles of both the linear attention and frequency-encoder components. This work demonstrates the powerful synergy between linear attention and frequency analysis, establishing a new paradigm for scalable time series modeling. Code is available at this repository: https://github.com/yangqingyuan-byte/FRWKV.
SpikMamba: When SNN meets Mamba in Event-based Human Action Recognition
Oct 22, 2024



Human action recognition (HAR) plays a key role in various applications such as video analysis, surveillance, autonomous driving, robotics, and healthcare. Most HAR algorithms are developed from RGB images, which capture detailed visual information. However, these algorithms raise concerns in privacy-sensitive environments due to the recording of identifiable features. Event cameras offer a promising solution by capturing scene brightness changes sparsely at the pixel level, without capturing full images. Moreover, event cameras have high dynamic ranges that can effectively handle scenarios with complex lighting conditions, such as low light or high contrast environments. However, using event cameras introduces challenges in modeling the spatially sparse and high temporal resolution event data for HAR. To address these issues, we propose the SpikMamba framework, which combines the energy efficiency of spiking neural networks and the long sequence modeling capability of Mamba to efficiently capture global features from spatially sparse and high a temporal resolution event data. Additionally, to improve the locality of modeling, a spiking window-based linear attention mechanism is used. Extensive experiments show that SpikMamba achieves remarkable recognition performance, surpassing the previous state-of-the-art by 1.45%, 7.22%, 0.15%, and 3.92% on the PAF, HARDVS, DVS128, and E-FAction datasets, respectively. The code is available at https://github.com/Typistchen/SpikMamba.
Phase recovery and holographic image reconstruction using deep learning in neural networks
May 10, 2017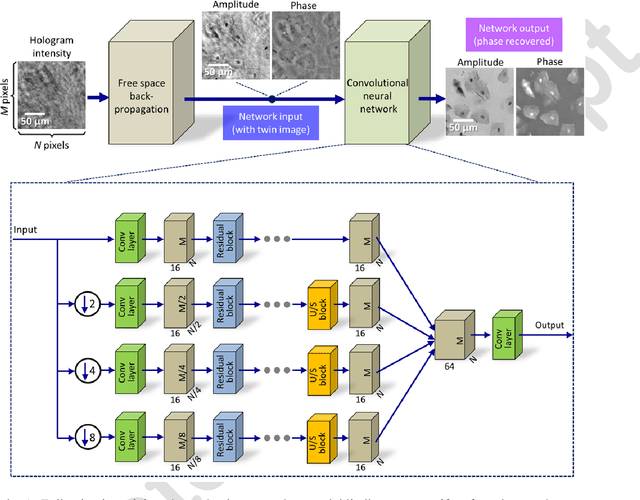

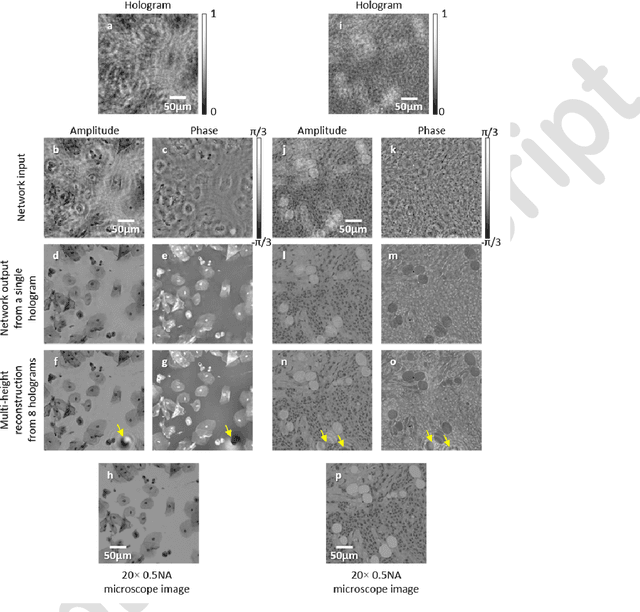

Phase recovery from intensity-only measurements forms the heart of coherent imaging techniques and holography. Here we demonstrate that a neural network can learn to perform phase recovery and holographic image reconstruction after appropriate training. This deep learning-based approach provides an entirely new framework to conduct holographic imaging by rapidly eliminating twin-image and self-interference related spatial artifacts. Compared to existing approaches, this neural network based method is significantly faster to compute, and reconstructs improved phase and amplitude images of the objects using only one hologram, i.e., requires less number of measurements in addition to being computationally faster. We validated this method by reconstructing phase and amplitude images of various samples, including blood and Pap smears, and tissue sections. These results are broadly applicable to any phase recovery problem, and highlight that through machine learning challenging problems in imaging science can be overcome, providing new avenues to design powerful computational imaging systems.