 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-quantified Rollout Policy Adaptation for Unlabelled Cross-domain Temporal Grounding
Aug 08, 2025Video Temporal Grounding (TG) aims to temporally locate video segments matching a natural language description (a query) in a long video. While Vision-Language Models (VLMs) are effective at holistic semantic matching, they often struggle with fine-grained temporal localisation. Recently, Group Relative Policy Optimisation (GRPO) reformulates the inference process as a reinforcement learning task, enabling fine-grained grounding and achieving strong in-domain performance. However, GRPO relies on labelled data, making it unsuitable in unlabelled domains. Moreover, because videos are large and expensive to store and process, performing full-scale adaptation introduces prohibitive latency and computational overhead, making it impractical for real-time deployment. To overcome both problems, we introduce a Data-Efficient Unlabelled Cross-domain Temporal Grounding method, from which a model is first trained on a labelled source domain, then adapted to a target domain using only a small number of unlabelled videos from the target domain. This approach eliminates the need for target annotation and keeps both computational and storage overhead low enough to run in real time. Specifically, we introduce. Uncertainty-quantified Rollout Policy Adaptation (URPA) for cross-domain knowledge transfer in learning video temporal grounding without target labels. URPA generates multiple candidate predictions using GRPO rollouts, averages them to form a pseudo label, and estimates confidence from the variance across these rollouts. This confidence then weights the training rewards, guiding the model to focus on reliable supervision. Experiments on three datasets across six cross-domain settings show that URPA generalises well using only a few unlabelled target videos. Codes will be released once published.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025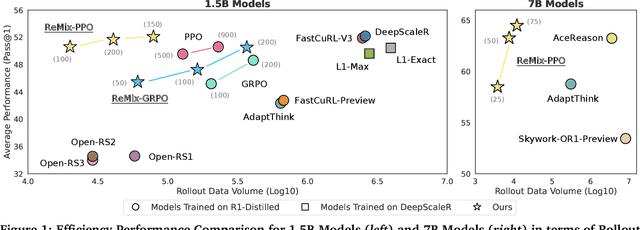
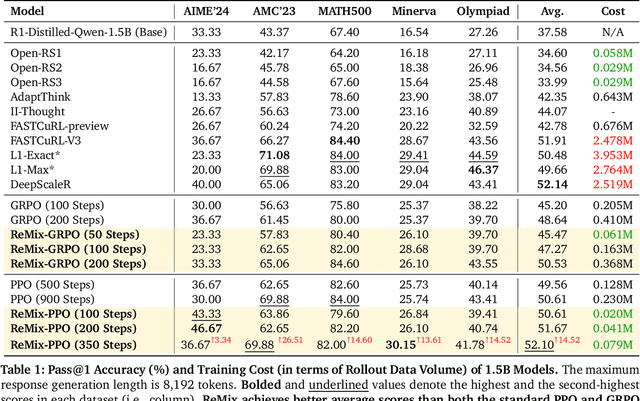
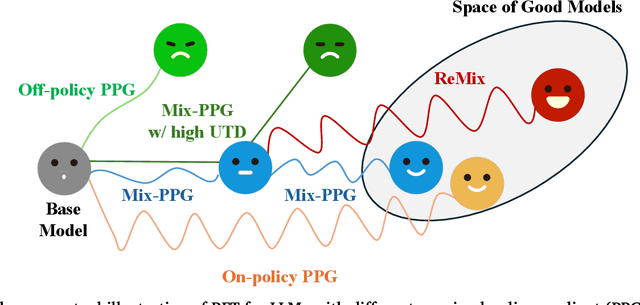

Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
STAR: Learning Diverse Robot Skill Abstractions through Rotation-Augmented Vector Quantization
Jun 04, 2025
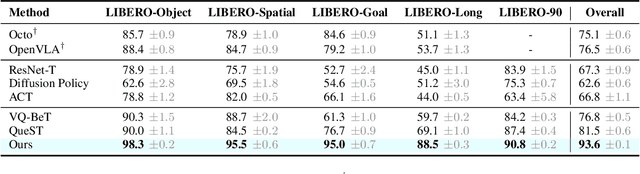
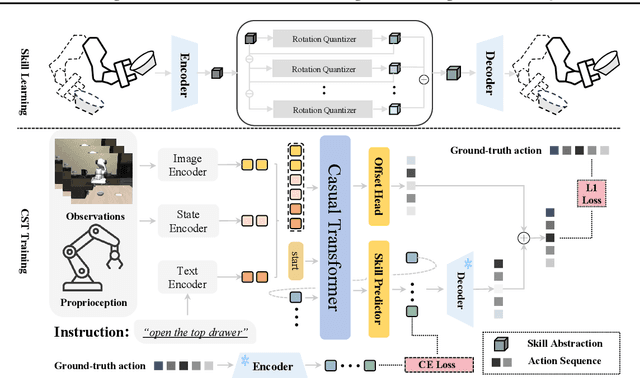

Transforming complex actions into discrete skill abstractions has demonstrated strong potential for robotic manipulation. Existing approaches mainly leverage latent variable models, e.g., VQ-VAE, to learn skill abstractions through learned vectors (codebooks), while they suffer from codebook collapse and modeling the causal relationship between learned skills. To address these limitations, we present \textbf{S}kill \textbf{T}raining with \textbf{A}ugmented \textbf{R}otation (\textbf{STAR}), a framework that advances both skill learning and composition to complete complex behaviors. Specifically, to prevent codebook collapse, we devise rotation-augmented residual skill quantization (RaRSQ). It encodes relative angles between encoder outputs into the gradient flow by rotation-based gradient mechanism. Points within the same skill code are forced to be either pushed apart or pulled closer together depending on gradient directions. Further, to capture the causal relationship between skills, we present causal skill transformer (CST) which explicitly models dependencies between skill representations through an autoregressive mechanism for coherent action generation. Extensive experiments demonstrate the superiority of STAR on both LIBERO benchmark and realworld tasks, with around 12\% improvement over the baselines.
* Accepted by ICML 2025 Spotlight
One Demo Is All It Takes: Planning Domain Derivation with LLMs from A Single Demonstration
May 23, 2025Pre-trained Large Language Models (LLMs) have shown promise in solving planning problems but often struggle to ensure plan correctness, especially for long-horizon tasks. Meanwhile, traditional robotic task and motion planning (TAMP) frameworks address these challenges more reliably by combining high-level symbolic search with low-level motion planning. At the core of TAMP is the planning domain, an abstract world representation defined through symbolic predicates and actions. However, creating these domains typically involves substantial manual effort and domain expertise, limiting generalizability. We introduce Planning Domain Derivation with LLMs (PDDLLM), a novel approach that combines simulated physical interaction with LLM reasoning to improve planning performance. The method reduces reliance on humans by inferring planning domains from a single annotated task-execution demonstration. Unlike prior domain-inference methods that rely on partially predefined or language descriptions of planning domains, PDDLLM constructs domains entirely from scratch and automatically integrates them with low-level motion planning skills, enabling fully automated long-horizon planning. PDDLLM is evaluated on over 1,200 diverse tasks spanning nine environments and benchmarked against six LLM-based planning baselines, demonstrating superior long-horizon planning performance, lower token costs, and successful deployment on multiple physical robot platforms.
Reinforcing Question Answering Agents with Minimalist Policy Gradient Optimization
May 20, 2025Large Language Models (LLMs) have demonstrated remarkable versatility, due to the lack of factual knowledge, their application to Question Answering (QA) tasks remains hindered by hallucination. While Retrieval-Augmented Generation mitigates these issues by integrating external knowledge, existing approaches rely heavily on in-context learning, whose performance is constrained by the fundamental reasoning capabilities of LLMs. In this paper, we propose Mujica, a Multi-hop Joint Intelligence for Complex Question Answering, comprising a planner that decomposes questions into a directed acyclic graph of subquestions and a worker that resolves questions via retrieval and reasoning. Additionally, we introduce MyGO (Minimalist policy Gradient Optimization), a novel reinforcement learning method that replaces traditional policy gradient updates with Maximum Likelihood Estimation (MLE) by sampling trajectories from an asymptotically optimal policy. MyGO eliminates the need for gradient rescaling and reference models, ensuring stable and efficient training. Empirical results across multiple datasets demonstrate the effectiveness of Mujica-MyGO in enhancing multi-hop QA performance for various LLMs, offering a scalable and resource-efficient solution for complex QA tasks.
Conditioning Matters: Training Diffusion Policies is Faster Than You Think
May 16, 2025Diffusion policies have emerged as a mainstream paradigm for building vision-language-action (VLA) models. Although they demonstrate strong robot control capabilities, their training efficiency remains suboptimal. In this work, we identify a fundamental challenge in conditional diffusion policy training: when generative conditions are hard to distinguish, the training objective degenerates into modeling the marginal action distribution, a phenomenon we term loss collapse. To overcome this, we propose Cocos, a simple yet general solution that modifies the source distribution in the conditional flow matching to be condition-dependent. By anchoring the source distribution around semantics extracted from condition inputs, Cocos encourages stronger condition integration and prevents the loss collapse. We provide theoretical justification and extensive empirical results across simulation and real-world benchmarks. Our method achieves faster convergence and higher success rates than existing approaches, matching the performance of large-scale pre-trained VLAs using significantly fewer gradient steps and parameters. Cocos is lightweight, easy to implement, and compatible with diverse policy architectures, offering a general-purpose improvement to diffusion policy training.
EmbodiedMAE: A Unified 3D Multi-Modal Representation for Robot Manipulation
May 15, 2025



We present EmbodiedMAE, a unified 3D multi-modal representation for robot manipulation. Current approaches suffer from significant domain gaps between training datasets and robot manipulation tasks, while also lacking model architectures that can effectively incorporate 3D information. To overcome these limitations, we enhance the DROID dataset with high-quality depth maps and point clouds, constructing DROID-3D as a valuable supplement for 3D embodied vision research. Then we develop EmbodiedMAE, a multi-modal masked autoencoder that simultaneously learns representations across RGB, depth, and point cloud modalities through stochastic masking and cross-modal fusion. Trained on DROID-3D, EmbodiedMAE consistently outperforms state-of-the-art vision foundation models (VFMs) in both training efficiency and final performance across 70 simulation tasks and 20 real-world robot manipulation tasks on two robot platforms. The model exhibits strong scaling behavior with size and promotes effective policy learning from 3D inputs. Experimental results establish EmbodiedMAE as a reliable unified 3D multi-modal VFM for embodied AI systems, particularly in precise tabletop manipulation settings where spatial perception is critical.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025



Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.