 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Proactive Coding Assistants in Real-World Software Development
May 07, 2026Large language model (LLM)-based coding assistants have made substantial progress, yet most systems remain reactive, requiring developers to explicitly formulate their needs. Proactive coding assistants aim to infer latent developer intent from integrated development environment (IDE) interactions and repository context, thereby reducing interaction overhead and supporting more seamless assistance. However, research in this direction is limited by the scarcity of large-scale real-world developer behavior data. Existing studies therefore often rely on LLM-simulated IDE traces, whose fidelity to real development behavior remains unclear. In this paper, we investigate this simulation-to-reality gap through a large-scale empirical study. We collect real IDE interaction traces from 1{,}246 experienced industry developers over three consecutive days using a custom Visual Studio Code extension, and construct paired LLM-simulated traces for controlled comparison. Our analysis shows that simulated traces differ substantially from real traces in behavioral diversity, temporal structure, and exploratory patterns. Based on the collected data, we introduce \textbf{ProCodeBench}, a real-world benchmark for proactive intent prediction. Experiments with representative LLMs, retrieval-augmented methods, and agentic baselines show that current approaches remain far from reliable under real IDE traces, suggesting that simulation-based evaluation can overestimate real-world performance. Finally, our training study shows that simulated data cannot replace real data, but can complement it when used before real-world fine-tuning. These findings highlight the importance of real developer behavior data for evaluating and training proactive coding assistants.
From Text to Forecasts: Bridging Modality Gap with Temporal Evolution Semantic Space
Mar 16, 2026Incorporating textual information into time-series forecasting holds promise for addressing event-driven non-stationarity; however, a fundamental modality gap hinders effective fusion: textual descriptions express temporal impacts implicitly and qualitatively, whereas forecasting models rely on explicit and quantitative signals. Through controlled semi-synthetic experiments, we show that existing methods over-attend to redundant tokens and struggle to reliably translate textual semantics into usable numerical cues. To bridge this gap, we propose TESS, which introduces a Temporal Evolution Semantic Space as an intermediate bottleneck between modalities. This space consists of interpretable, numerically grounded temporal primitives (mean shift, volatility, shape, and lag) extracted from text by an LLM via structured prompting and filtered through confidence-aware gating. Experiments on four real-world datasets demonstrate up to a 29 percent reduction in forecasting error compared to state-of-the-art unimodal and multimodal baselines. The code will be released after acceptance.
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Mar 02, 2026Automated paper reproduction -- generating executable code from academic papers -- is bottlenecked not by information retrieval but by the tacit knowledge that papers inevitably leave implicit. We formalize this challenge as the progressive recovery of three types of tacit knowledge -- relational, somatic, and collective -- and propose \method, a graph-based agent framework with a dedicated mechanism for each: node-level relation-aware aggregation recovers relational knowledge by analyzing implementation-unit-level reuse and adaptation relationships between the target paper and its citation neighbors; execution-feedback refinement recovers somatic knowledge through iterative debugging driven by runtime signals; and graph-level knowledge induction distills collective knowledge from clusters of papers sharing similar implementations. On an extended ReproduceBench spanning 3 domains, 10 tasks, and 40 recent papers, \method{} achieves an average performance gap of 10.04\% against official implementations, improving over the strongest baseline by 24.68\%. The code will be publicly released upon acceptance; the repository link will be provided in the final version.
AgentExpt: Automating AI Experiment Design with LLM-based Resource Retrieval Agent
Nov 07, 2025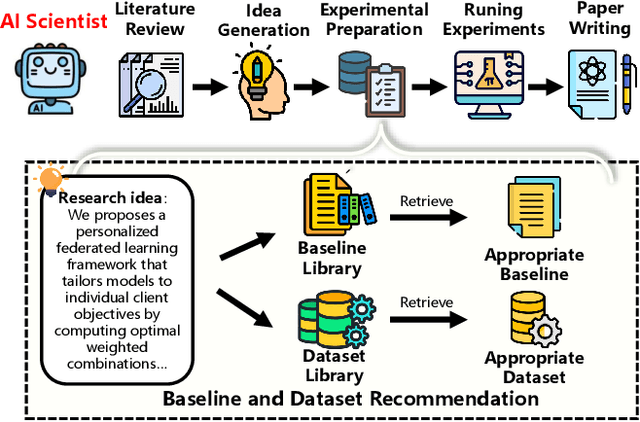
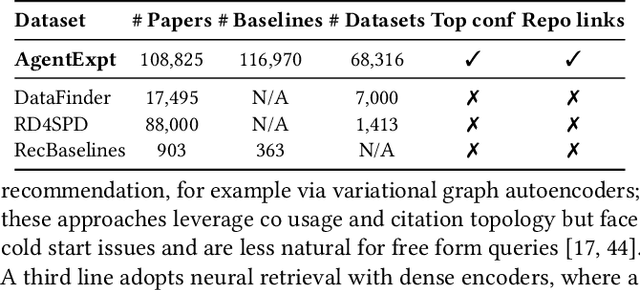
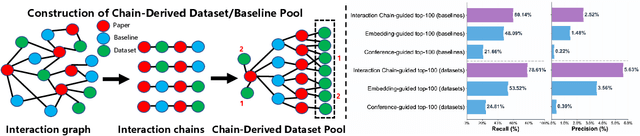
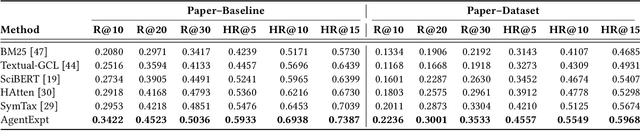
Large language model agents are becoming increasingly capable at web-centric tasks such as information retrieval, complex reasoning. These emerging capabilities have given rise to surge research interests in developing LLM agent for facilitating scientific quest. One key application in AI research is to automate experiment design through agentic dataset and baseline retrieval. However, prior efforts suffer from limited data coverage, as recommendation datasets primarily harvest candidates from public portals and omit many datasets actually used in published papers, and from an overreliance on content similarity that biases model toward superficial similarity and overlooks experimental suitability. Harnessing collective perception embedded in the baseline and dataset citation network, we present a comprehensive framework for baseline and dataset recommendation. First, we design an automated data-collection pipeline that links roughly one hundred thousand accepted papers to the baselines and datasets they actually used. Second, we propose a collective perception enhanced retriever. To represent the position of each dataset or baseline within the scholarly network, it concatenates self-descriptions with aggregated citation contexts. To achieve efficient candidate recall, we finetune an embedding model on these representations. Finally, we develop a reasoning-augmented reranker that exact interaction chains to construct explicit reasoning chains and finetunes a large language model to produce interpretable justifications and refined rankings. The dataset we curated covers 85\% of the datasets and baselines used at top AI conferences over the past five years. On our dataset, the proposed method outperforms the strongest prior baseline with average gains of +5.85\% in Recall@20, +8.30\% in HitRate@5. Taken together, our results advance reliable, interpretable automation of experimental design.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
A clustering adaptive Gaussian process regression method: response patterns based real-time prediction for nonlinear solid mechanics problems
Sep 15, 2024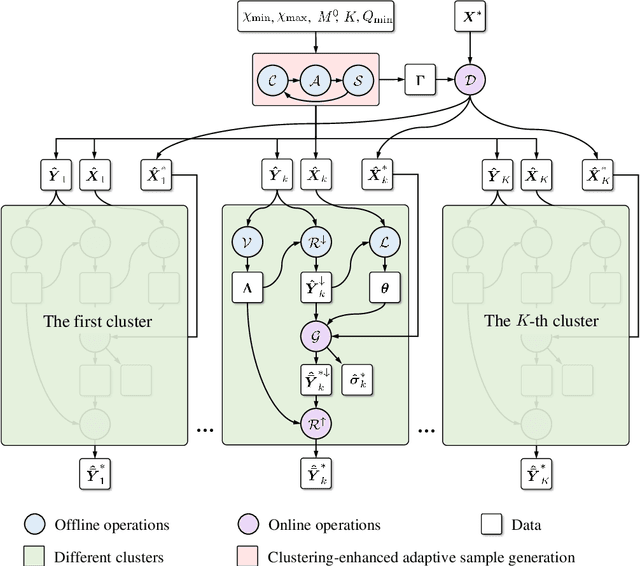
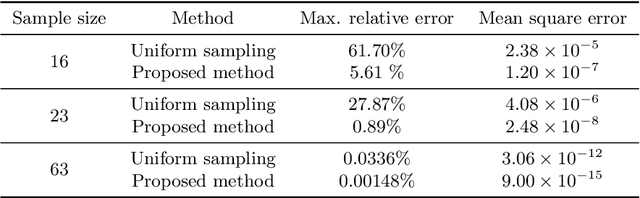

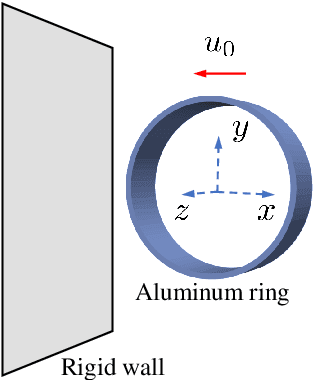
Numerical simulation is powerful to study nonlinear solid mechanics problems. However, mesh-based or particle-based numerical methods suffer from the common shortcoming of being time-consuming, particularly for complex problems with real-time analysis requirements. This study presents a clustering adaptive Gaussian process regression (CAG) method aiming for real-time prediction for nonlinear structural responses in solid mechanics. It is a data-driven machine learning method featuring a small sample size, high accuracy, and high efficiency, leveraging nonlinear structural response patterns. Similar to the traditional Gaussian process regression (GPR) method, it operates in offline and online stages. In the offline stage, an adaptive sample generation technique is introduced to cluster datasets into distinct patterns for demand-driven sample allocation. This ensures comprehensive coverage of the critical samples for the solution space of interest. In the online stage, following the divide-and-conquer strategy, a pre-prediction classification categorizes problems into predefined patterns sequentially predicted by the trained multi-pattern Gaussian process regressor. In addition, dimension reduction and restoration techniques are employed in the proposed method to enhance its efficiency. A set of problems involving material, geometric, and boundary condition nonlinearities is presented to demonstrate the CAG method's abilities. The proposed method can offer predictions within a second and attain high precision with only about 20 samples within the context of this study, outperforming the traditional GPR using uniformly distributed samples for error reductions ranging from 1 to 3 orders of magnitude. The CAG method is expected to offer a powerful tool for real-time prediction of nonlinear solid mechanical problems and shed light on the complex nonlinear structural response pattern.