 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoTactile: Learning Grasp Pressure for Everyday Objects from Egocentric Video
Jun 08, 2026Estimating full-hand grasp pressure from egocentric video is critical for immersive VR and robotic manipulation, yet dense tactile sensing often relies on intrusive hardware. Existing vision-based methods predominantly rely on planar surfaces or fingertip contacts, failing to generalize to complex 3D object interactions. Therefore, we introduce EgoTactile, a benchmark pairing egocentric video with full-hand pressure supervision for diverse everyday objects, incorporating a bare-hand transfer subset to enable generalization to natural scenarios. Leveraging this benchmark, we first establish EgoPressureFormer as a discriminative baseline. Beyond this, to explicitly address the uncertainty in partial observations, we propose EgoPressureDiff, a conditional diffusion framework that adapts a large-scale pre-trained video diffusion backbone. By combining rich world knowledge priors with a Physically-Informed Feature Rectification layer to inject semantic constraints, our approach effectively infers plausible contact patterns and resolves visual-physical ambiguities. Extensive experiments demonstrate that our method achieves superior performance on the benchmark and robust transferability to in-the-wild scenarios. Our project page is available at https://egotactile.github.io/.
Beyond Skeletons: Learning Animation Directly from Driving Videos with Same2X Training Strategy
Jun 05, 2026Human image animation aims to generate a video from a static reference image, guided by pose information extracted from a driving video. Existing approaches often rely on pose estimators to extract intermediate representations, but such signals are prone to errors under occlusion or complex poses. Building on these observations, we present DirectAnimator, a framework that bypasses pose extraction and directly learns from raw driving videos. We introduce a Driving Cue Triplet consisting of pose, face, and location cues that captures motion, expression, and alignment in a semantically rich yet stable form, and we fuse them through a CueFusion DiT block for reliable control during denoising. To make learning dependable when the driving and reference identities differ, we devise a Same2X training strategy that aligns cross-ID features with those learned from same-ID data, regularizing optimization and accelerating convergence. Extensive experiments demonstrate that DirectAnimator attains state-of-the-art visual quality and identity preservation while remaining robust to occlusions and complex articulation, and it does so with fewer computational resources. Our project page is at https://directanimator.github.io/.
StreamingVLA: Streaming Vision-Language-Action Model with Action Flow Matching and Adaptive Early Observation
Mar 30, 2026Vision-language-action (VLA) models have demonstrated exceptional performance in natural language-driven perception and control. However, the high computational cost of VLA models poses significant efficiency challenges, particularly for resource-constrained edge platforms in real-world deployments. However, since different stages of VLA (observation, action generation and execution) must proceed sequentially, and wait for the completion of the preceding stage, the system suffers from frequent halting and high latency. To address this, We conduct a systematic analysis to identify the challenges for fast and fluent generation, and propose enabling VLAs with the ability to asynchronously parallelize across VLA stages in a "streaming" manner. First, we eliminate the reliance on action chunking and adopt action flow matching, which learns the trajectory of action flows rather than denoising chunk-wise actions. It overlaps the latency of action generation and execution. Second, we design an action saliency-aware adaptive observation mechanism, thereby overlapping the latency of execution and observation. Without sacrificing performance, StreamingVLA achieves substantial speedup and improves the fluency of execution. It achieves a 2.4 $\times$ latency speedup and reduces execution halting by 6.5 $\times$.
SmoothSync: Dual-Stream Diffusion Transformers for Jitter-Robust Beat-Synchronized Gesture Generation from Quantized Audio
Jan 04, 2026Co-speech gesture generation is a critical area of research aimed at synthesizing speech-synchronized human-like gestures. Existing methods often suffer from issues such as rhythmic inconsistency, motion jitter, foot sliding and limited multi-sampling diversity. In this paper, we present SmoothSync, a novel framework that leverages quantized audio tokens in a novel dual-stream Diffusion Transformer (DiT) architecture to synthesis holistic gestures and enhance sampling variation. Specifically, we (1) fuse audio-motion features via complementary transformer streams to achieve superior synchronization, (2) introduce a jitter-suppression loss to improve temporal smoothness, (3) implement probabilistic audio quantization to generate distinct gesture sequences from identical inputs. To reliably evaluate beat synchronization under jitter, we introduce Smooth-BC, a robust variant of the beat consistency metric less sensitive to motion noise. Comprehensive experiments on the BEAT2 and SHOW datasets demonstrate SmoothSync's superiority, outperforming state-of-the-art methods by -30.6% FGD, 10.3% Smooth-BC, and 8.4% Diversity on BEAT2, while reducing jitter and foot sliding by -62.9% and -17.1% respectively. The code will be released to facilitate future research.
Learning When to Look: A Disentangled Curriculum for Strategic Perception in Multimodal Reasoning
Dec 19, 2025Multimodal Large Language Models (MLLMs) demonstrate significant potential but remain brittle in complex, long-chain visual reasoning tasks. A critical failure mode is "visual forgetting", where models progressively lose visual grounding as reasoning extends, a phenomenon aptly described as "think longer, see less". We posit this failure stems from current training paradigms prematurely entangling two distinct cognitive skills: (1) abstract logical reasoning "how-to-think") and (2) strategic visual perception ("when-to-look"). This creates a foundational cold-start deficiency -- weakening abstract reasoning -- and a strategic perception deficit, as models lack a policy for when to perceive. In this paper, we propose a novel curriculum-based framework to disentangle these skills. First, we introduce a disentangled Supervised Fine-Tuning (SFT) curriculum that builds a robust abstract reasoning backbone on text-only data before anchoring it to vision with a novel Perception-Grounded Chain-of-Thought (PG-CoT) paradigm. Second, we resolve the strategic perception deficit by formulating timing as a reinforcement learning problem. We design a Pivotal Perception Reward that teaches the model when to look by coupling perceptual actions to linguistic markers of cognitive uncertainty (e.g., "wait", "verify"), thereby learning an autonomous grounding policy. Our contributions include the formalization of these two deficiencies and the development of a principled, two-stage framework to address them, transforming the model from a heuristic-driven observer to a strategic, grounded reasoner. \textbf{Code}: \url{https://github.com/gaozilve-max/learning-when-to-look}.
AgentExpt: Automating AI Experiment Design with LLM-based Resource Retrieval Agent
Nov 07, 2025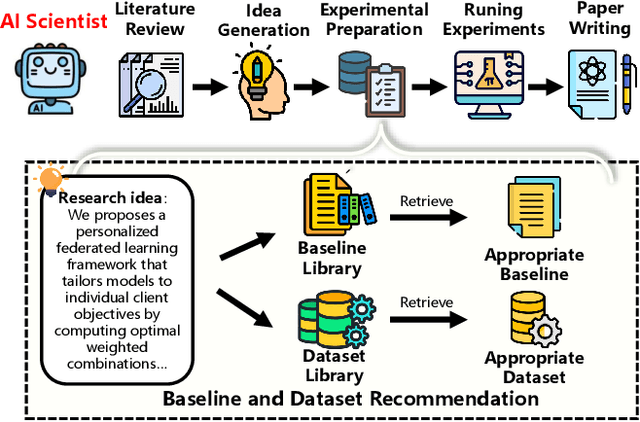
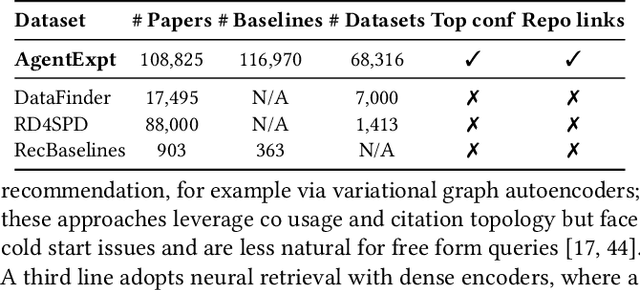
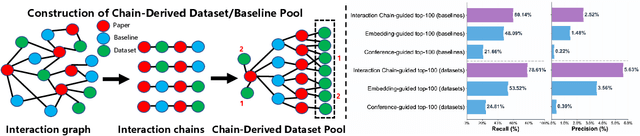
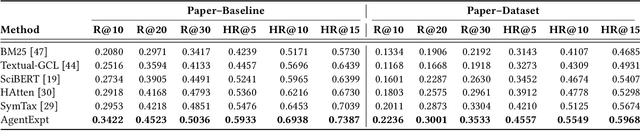
Large language model agents are becoming increasingly capable at web-centric tasks such as information retrieval, complex reasoning. These emerging capabilities have given rise to surge research interests in developing LLM agent for facilitating scientific quest. One key application in AI research is to automate experiment design through agentic dataset and baseline retrieval. However, prior efforts suffer from limited data coverage, as recommendation datasets primarily harvest candidates from public portals and omit many datasets actually used in published papers, and from an overreliance on content similarity that biases model toward superficial similarity and overlooks experimental suitability. Harnessing collective perception embedded in the baseline and dataset citation network, we present a comprehensive framework for baseline and dataset recommendation. First, we design an automated data-collection pipeline that links roughly one hundred thousand accepted papers to the baselines and datasets they actually used. Second, we propose a collective perception enhanced retriever. To represent the position of each dataset or baseline within the scholarly network, it concatenates self-descriptions with aggregated citation contexts. To achieve efficient candidate recall, we finetune an embedding model on these representations. Finally, we develop a reasoning-augmented reranker that exact interaction chains to construct explicit reasoning chains and finetunes a large language model to produce interpretable justifications and refined rankings. The dataset we curated covers 85\% of the datasets and baselines used at top AI conferences over the past five years. On our dataset, the proposed method outperforms the strongest prior baseline with average gains of +5.85\% in Recall@20, +8.30\% in HitRate@5. Taken together, our results advance reliable, interpretable automation of experimental design.
Large Material Gaussian Model for Relightable 3D Generation
Sep 26, 2025
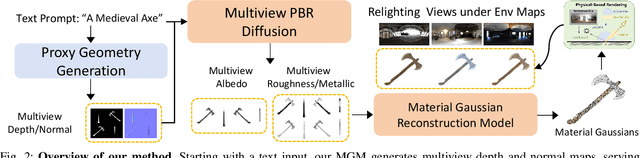
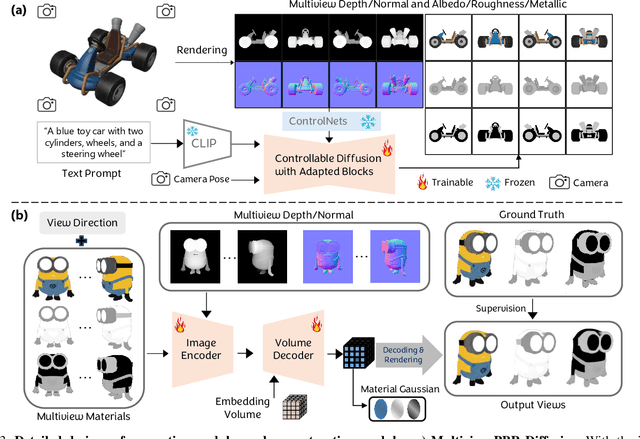

The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
TACO: Think-Answer Consistency for Optimized Long-Chain Reasoning and Efficient Data Learning via Reinforcement Learning in LVLMs
May 27, 2025DeepSeek R1 has significantly advanced complex reasoning for large language models (LLMs). While recent methods have attempted to replicate R1's reasoning capabilities in multimodal settings, they face limitations, including inconsistencies between reasoning and final answers, model instability and crashes during long-chain exploration, and low data learning efficiency. To address these challenges, we propose TACO, a novel reinforcement learning algorithm for visual reasoning. Building on Generalized Reinforcement Policy Optimization (GRPO), TACO introduces Think-Answer Consistency, which tightly couples reasoning with answer consistency to ensure answers are grounded in thoughtful reasoning. We also introduce the Rollback Resample Strategy, which adaptively removes problematic samples and reintroduces them to the sampler, enabling stable long-chain exploration and future learning opportunities. Additionally, TACO employs an adaptive learning schedule that focuses on moderate difficulty samples to optimize data efficiency. Furthermore, we propose the Test-Time-Resolution-Scaling scheme to address performance degradation due to varying resolutions during reasoning while balancing computational overhead. Extensive experiments on in-distribution and out-of-distribution benchmarks for REC and VQA tasks show that fine-tuning LVLMs leads to significant performance improvements.
What Can RL Bring to VLA Generalization? An Empirical Study
May 26, 2025Large Vision-Language Action (VLA) models have shown significant potential for embodied AI. However, their predominant training via supervised fine-tuning (SFT) limits generalization due to susceptibility to compounding errors under distribution shifts. Reinforcement learning (RL) offers a path to overcome these limitations by optimizing for task objectives via trial-and-error, yet a systematic understanding of its specific generalization benefits for VLAs compared to SFT is lacking. To address this, our study introduces a comprehensive benchmark for evaluating VLA generalization and systematically investigates the impact of RL fine-tuning across diverse visual, semantic, and execution dimensions. Our extensive experiments reveal that RL fine-tuning, particularly with PPO, significantly enhances generalization in semantic understanding and execution robustness over SFT, while maintaining comparable visual robustness. We identify PPO as a more effective RL algorithm for VLAs than LLM-derived methods like DPO and GRPO. We also develop a simple recipe for efficient PPO training on VLAs, and demonstrate its practical utility for improving VLA generalization. The project page is at https://rlvla.github.io